ainovelprompter
1.0.0
AI Novel ProPter kann Schreibaufforderungen für Romane basierend auf benutzerdefinierten Merkmalen generieren.
AI Novel ProPter ist eine Desktop-Anwendung, mit der Autoren konsistente und gut strukturierte Aufforderungen für KI-Schreibassistenten wie Chatgpt und Claude erstellen sollen. Das Tool hilft, Story -Elemente, Charakterdetails zu verwalten und ordnungsgemäß formatierte Aufforderungen für die Fortsetzung Ihres Romans zu generieren.
Die ausführbare Datei befindet sich auf Build/Bin ausführbar
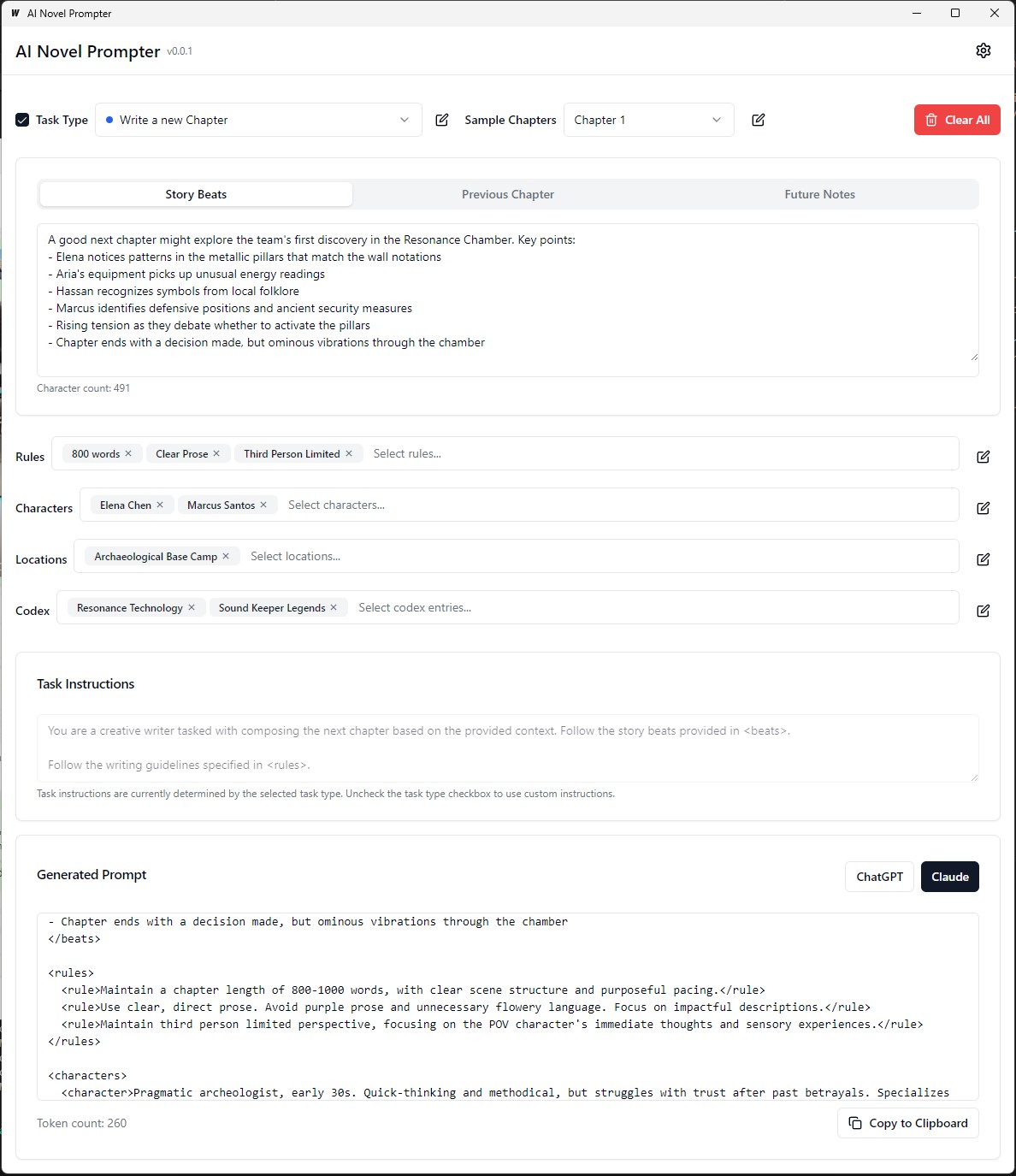
Jede Kategorie kann bearbeitet, gespeichert und über verschiedene Eingaben wiederverwendet werden:
Frontend :
Backend :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev Verwenden Sie, um ein umverteilbares Produktionsmodus -Paket zu erstellen. Verwenden Sie wails build .
wails buildDie ausführbare Datei befindet sich auf Build/Bin ausführbar
Oder generieren Sie es mit:
wails build -nsisDies kann für Mac erfolgen und den neuesten Teil dieses Handbuchs sehen
Die gebaute Anwendung wird im build -Verzeichnis erhältlich sein.
Erstes Setup :
Erstellen einer Eingabeaufforderung :
Ausgabe erzeugen :
Stellen Sie vor dem Ausführen der Anwendung sicher, dass Sie die folgenden Installationen installiert haben:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Navigieren Sie zum server :
cd server
Installieren Sie die GO -Abhängigkeiten:
go mod download
Aktualisieren Sie die Datei config.yaml mit Ihrer Datenbankkonfiguration.
Führen Sie die Datenbankmigrationen aus:
go run cmd/main.go migrate
Starten Sie den Backend Server:
go run cmd/main.go
Navigieren Sie zum client -Verzeichnis:
cd ../client
Installieren Sie die Frontend -Abhängigkeiten:
npm install
Starten Sie den Frontend Development Server:
npm start
http://localhost:3000 um auf die Anwendung zuzugreifen. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Aktualisieren Sie die Datei docker-compose.yml mit Ihrer Datenbankkonfiguration.
Starten Sie die Anwendung mit Docker Compose:
docker-compose up -d
http://localhost:3000 um auf die Anwendung zuzugreifen. server/config.yaml geändert werden.client/src/config.ts geändert werden. Führen Sie den folgenden Befehl im client -Verzeichnis aus, um das Frontend für die Produktion zu erstellen:
npm run build
Die produktionsbereiten Dateien werden im client/build -Verzeichnis generiert.
Diese kleine Anleitung enthält Anweisungen zur Installation von PostgreSQL im Windows -Subsystem für Linux (WSL) sowie Schritte zur Verwaltung von Benutzerberechtigungen und zur Fehlerbehebung bei allgemeinen Problemen.
Öffnen Sie das WSL -Terminal : Starten Sie Ihre WSL -Verteilung (Ubuntu empfohlen).
Pakete aktualisieren :
sudo apt updatePostgresql installieren :
sudo apt install postgresql postgresql-contribInstallation überprüfen :
psql --versionSetzen Sie das PostgreSQL -Benutzerkennwort :
sudo passwd postgresDatenbank erstellen :
createdb mydbZugriff auf Datenbank :
psql mydbTabellen aus der SQL -Datei importieren :
psql -U postgres -q mydb < /path/to/file.sqlListen Sie Datenbanken und Tabellen auf :
l # List databases
dt # List tables in the current databaseDatenbank wechseln :
c dbnameNeuen Benutzer erstellen :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;Privilegien gewähren :
ALTER USER your_db_user CREATEDB;Die Rolle gibt keinen Fehler : Wechseln Sie zum Benutzer "Postgres":
sudo -i -u postgres
createdb your_db_nameErlaubnis verweigert, Erweiterung zu erstellen : Login als "Postgres" und Ausführung:
CREATE EXTENSION IF NOT EXISTS pg_trgm; Unbekannter Benutzerfehler : Stellen Sie sicher, dass Sie einen erkannten Systembenutzer verwenden oder korrekt auf einen PostgreSQL -Benutzer in der SQL -Umgebung beziehen, nicht über sudo .
Um benutzerdefinierte Trainingsdaten für die Feinabstimmung eines Sprachmodells zu generieren, um den Schreibstil von George MacDonald zu emulieren, beginnt der Prozess mit dem Erhalt des vollständigen Textes eines seiner Romane "The Princess and the Goblin" von Project Gutenberg. Der Text wird dann in einzelne Story -Beats oder Schlüsselmomente unter Verwendung einer Aufforderung unterteilt, die die KI anweist, für jeden Beat ein JSON -Objekt zu erzeugen und den Autor, den emotionalen Ton, die Art des Schreibens und den tatsächlichen Textauszug zu erfassen.
Als nächstes wird GPT-4 verwendet, um jede dieser Geschichte in seinen eigenen Worten umzuschreiben und einen parallelen Satz von JSON-Daten mit eindeutigen Kennungen zu erzeugen, die jeden umgeschriebenen Beat mit seinem ursprünglichen Gegenstück verbinden. Um die Daten zu vereinfachen und sie für das Training nützlicher zu machen, wird die Vielzahl der emotionalen Töne mit einer Python -Funktion auf einen kleineren Satz von Kerntönen abgebildet. Die beiden JSON-Dateien (Original- und umgeschriebene Beats) werden dann verwendet, um Trainingseinweisungen zu generieren, wobei das Modell aufgefordert wird, den GPT-4-generierten Text im Stil des ursprünglichen Autors neu zu erstellen. Schließlich werden diese Eingabeaufforderungen und ihre Zielausgänge in JSONL- und JSON-Dateien formatiert, um das Sprachmodell zur Feinabstimmung zu verwenden, um MacDonalds unverwechselbare Schreibstil zu erfassen.
Im vorherigen Beispiel beinhaltete der Prozess der Generierung von paraphrasiertem Text unter Verwendung eines Sprachmodells einige manuelle Aufgaben. Der Benutzer musste den Eingangstext manuell bereitstellen, das Skript ausführen und dann die generierte Ausgabe überprüfen, um seine Qualität zu gewährleisten. Wenn die Ausgabe nicht die gewünschten Kriterien erfüllte, müsste der Benutzer den Erzeugungsprozess mit unterschiedlichen Parametern manuell wiederholen oder Anpassungen am Eingangstext vornehmen.
Mit der aktualisierten Version der Funktion process_text_file wurde der gesamte Prozess jedoch vollständig automatisiert. Die Funktion kümmert sich um das Lesen der Eingabetextdatei, die Aufteilung in Absätze und sendet automatisch jeden Absatz an das Sprachmodell zur Umschreibung. Es enthält verschiedene Überprüfungen und Wiederholungsmechanismen, um Fälle zu bewältigen, in denen die generierte Ausgabe nicht den angegebenen Kriterien erfüllt, z.
Der Automatisierungsprozess enthält mehrere wichtige Funktionen:
Wiederaufnahme aus dem zuletzt verarbeiteten Absatz: Wenn das Skript unterbrochen wird oder mehrmals ausgeführt werden muss, überprüft es automatisch die Ausgabedatei und setzt die Verarbeitung von dem zuletzt erfolgreich abgeschriebenen Absatz fort. Dies stellt sicher, dass der Fortschritt nicht verloren geht und das Skript dort aufnehmen kann, wo es aufgehört hat.
Wiederholungsmechanismus mit zufälliger Saatgut und Temperatur: Wenn eine erzeugte Paraphrase die angegebenen Kriterien nicht erfüllt, wird das Skript automatisch den Erzeugungsprozess bis zu einer bestimmten Anzahl von Malen überholt. Bei jedem Wiederholung ändert es zufällig die Saatgut- und Temperaturwerte, um Variationen der erzeugten Antworten einzuführen, wodurch die Wahrscheinlichkeit erhöht wird, dass eine zufriedenstellende Ausgabe erfasst wird.
Fortschrittssparen: Das Skript speichert den Fortschritt in der Ausgabedatei jede angegebene Anzahl von Absätzen (z. B. alle 500 Absätze). Dieser Schutz vor Datenverlust bei Unterbrechungen oder Fehlern während der Verarbeitung einer großen Textdatei.
Detaillierte Protokollierung und Zusammenfassung: Das Skript enthält detaillierte Protokollierungsinformationen, einschließlich des Eingabebereichs, generierter Ausgabe, Wiederholungsversuche und Gründen für das Scheitern. Am Ende generiert es auch eine Zusammenfassung, in der die Gesamtzahl der Absätze, erfolgreich umschriebene Absätze, übersprungene Absätze und die Gesamtzahl der Wiederholungen angezeigt wird.
So generieren Sie orpo benutzerdefinierte Trainingsdaten für die Feinabstimmung eines Sprachmodells, um den Schreibstil von George MacDonald zu emulieren.
Die Eingabedaten sollten im JSONL -Format enthalten sein, wobei jede Zeile ein JSON -Objekt enthält, das die Eingabeaufforderung und die ausgewählte Antwort enthält. (Aus der vorherigen Feinabstimmung) Um das Skript zu verwenden, müssen Sie den OpenAI -Client mit Ihrer API -Taste einrichten und die Eingabe- und Ausgabedateipfade angeben. Durch Ausführen des Skripts verarbeitet die JSONL -Datei und generiert eine CSV -Datei mit Spalten für die Eingabeaufforderung, die ausgewählte Antwort und eine generierte abgelehnte Antwort. Das Skript speichert alle 100 Zeilen Fortschritte und kann von der Stelle wieder aufgenommen werden, wenn es aufgehört hat, wenn es unterbrochen wird. Nach Abschluss bietet es eine Zusammenfassung der verarbeiteten Gesamtzeilen, geschriebenen Zeilen, übersprungenen Zeilen und Wiederholungsdetails.
Datensatzqualitätsangelegenheiten: 95% der Ergebnisse sind von der Datensatzqualität abhängig. Ein sauberer Datensatz ist unerlässlich, da selbst ein wenig schlechte Daten das Modell beeinträchtigen können.
Manuelle Datenübersicht: Reinigen und Bewertung des Datensatzes kann das Modell erheblich verbessern. Dies ist ein zeitaufwändiger, aber notwendiger Schritt, da kein Parameteranpassung einen defekten Datensatz beheben kann.
Trainingsparameter sollten sich nicht verbessern, sondern den Modellabbau verhindern. In robusten Datensätzen sollte das Ziel sein, negative Auswirkungen zu vermeiden, während das Modell leitet. Es gibt keine optimale Lernrate.
Modellskala- und Hardware-Einschränkungen: Größere Modelle (33B-Parameter) können eine bessere Feinabstimmung ermöglichen, erfordern jedoch mindestens 48 GB VRAM, was sie für die Mehrheit der Heim-Setups unpraktisch macht.
Gradientenakkumulation und Chargengröße: Die Gradientenakkumulation reduziert die Überanpassung, indem die Verallgemeinerung über verschiedene Datensätze hinweg verbessert wird, kann jedoch nach einigen Chargen eine geringere Qualität beeinträchtigen.
Die Größe des Datensatzes ist wichtiger für die Feinabstimmung eines Basismodells als ein gut abgestimmtes Modell. Das Überladen eines gut abgestimmten Modells mit übermäßigen Daten kann seine vorherige Feinabstimmung beeinträchtigen.
Ein idealer Lernrate -Zeitplan beginnt mit einer Aufwärmphase, hält für eine Epoche konstant und nimmt dann mit einem Cosinus -Zeitplan allmählich ab.
Modellrang und Verallgemeinerung: Die Menge an trainierbaren Parametern wirkt sich auf die Details und die Verallgemeinerung des Modells aus. Modelle mit niedrigerem Rang verallgemeinern besser, verlieren aber Details.
Die Anwendbarkeit von LORA: Parameter-effizientes Feinabstimmung (PEFT) ist für große Sprachmodelle (LLMs) und Systeme wie stabile Diffusion (SD) anwendbar, was deren Vielseitigkeit demonstriert.
Die Unloth -Community hat dazu beigetragen, mehrere Probleme mit dem Finetuning LLAMA3 zu lösen. Hier sind einige wichtige Punkte zu beachten:
Doppel -BOS -Token : Doppel -Bos -Token während der Finetuning kann die Dinge brechen. Unloth behebt dieses Problem automatisch.
GGUF -Umwandlung : Die GGUF -Umwandlung ist gebrochen. Achten Sie auf Doppel -BOS und verwenden Sie CPU anstelle von GPU zur Konvertierung. Unloth verfügt über integrierte automatische GGUF-Conversions.
Buggy-Basisgewichte : Einige der Basis von Lama 3 (nicht anweisen) Gewichte sind "buggy" (untrainiert): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> . Dies kann NANS- und Buggy -Ergebnisse verursachen. Unloth behebt dies automatisch.
System -Eingabeaufforderung : Laut der Unloth -Community macht das Hinzufügen einer Systemaufforderung die Finetuning der Anweisungsversion (und möglicherweise der Basisversion) viel besser.
Quantisierungsprobleme : Quantisierungsprobleme sind häufig. Sehen Sie sich diesen Vergleich an, der zeigt, dass Sie mit LLAMA3 eine gute Leistung erzielen können, aber die Verwendung der falschen Quantisierung kann die Leistung beeinträchtigen. Verwenden Sie zum Finetuning Bitsandbytes NF4, um die Genauigkeit zu steigern. Verwenden Sie für GGUF die I -Versionen so weit wie möglich.
Lange Kontextmodelle : Lange Kontextmodelle sind schlecht ausgebildet. Sie erweitern einfach das Seil Theta, manchmal ohne Training, und trainieren dann auf einem seltsamen verketteten Datensatz, um es zu einem langen Datensatz zu machen. Dieser Ansatz funktioniert nicht gut. Eine glatte, kontinuierliche, lange Kontextskalierung wäre viel besser gewesen, wenn sie von 8K bis 1 m Kontextlänge skalieren.
Um einige dieser Probleme zu lösen, verwenden Sie Unloth für das Finetuning llama3.
Bei der Feinabstimmung eines Sprachmodells für das Paraphrasieren im Stil eines Autors ist es wichtig, die Qualität und Wirksamkeit der erzeugten Paraphrasen zu bewerten.
Die folgenden Bewertungsmetriken können verwendet werden, um die Leistung des Modells zu bewerten:
Bleu (zweisprachige Bewertungsstuddie):
sacrebleu -Bibliothek in Python verwenden.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (Rückruf-orientierte Zweitbesetzung zur Gisting-Bewertung):
rouge -Bibliothek in Python verwenden.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)Verwirrung:
perplexity = model.perplexity(generated_paraphrases)Stilometrische Maßnahmen:
stylometry -Bibliothek in Python verwenden.from stylometry import extract_features; features = extract_features(generated_paraphrases)Befolgen Sie diese Schritte, um diese Bewertungsmetriken in Ihre Axolotl -Pipeline zu integrieren:
Bereiten Sie Ihre Schulungsdaten vor, indem Sie einen Datensatz mit Absätzen aus den Werken des Zielautors erstellen und in Trainings- und Validierungssätze aufteilt.
Fein Ihres Sprachmodells mit dem Trainingssatz, folgt dem zuvor diskutierten Ansatz.
Generieren Sie Paraphrasen für die Absätze im Validierungssatz unter Verwendung des feinabstimmigen Modells.
Implementieren Sie die Bewertungsmetriken mithilfe der jeweiligen Bibliotheken ( sacrebleu , rouge , stylometry ) und berechnen Sie die Bewertungen für jede erzeugte Paraphrase.
Führen Sie die menschliche Bewertung durch, indem Sie Bewertungen und Feedback von menschlichen Bewertern sammeln.
Analysieren Sie die Bewertungsergebnisse, um die Qualität und den Stil der generierten Paraphrasen zu bewerten und fundierte Entscheidungen zu treffen, um Ihren Feinabstimmungsprozess zu verbessern.
Hier ist ein Beispiel dafür, wie Sie diese Metriken in Ihre Pipeline integrieren können:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )Denken Sie daran, die notwendigen Bibliotheken (Sacrebleu, Rouge, Stylometrie) zu installieren und den Code so anzupassen, dass Sie Ihre Implementierung in Axolotl oder ähnliches entsprechen.
In diesem Experiment habe ich die Fähigkeiten und Unterschiede zwischen verschiedenen KI-Modellen bei der Erzeugung eines 1500-Wörter-Textes untersucht, der auf einer detaillierten Eingabeaufforderung basiert. Ich habe Modelle von https://chat.lmsys.org/, Chatgpt4, Claude 3 Opus und einigen lokalen Modellen in LM Studio getestet. Jedes Modell erzeugte den Text dreimal, um die Variabilität ihrer Ausgänge zu beobachten. Ich habe auch eine separate Eingabeaufforderung für die Bewertung des Schreibens der ersten Iteration aus jedem Modell erstellt und Chatgpt 4 und Claude Opus 3 gefragt, um Feedback zu geben.
Durch diesen Prozess habe ich festgestellt, dass einige Modelle eine höhere Variabilität zwischen Ausführungen aufweisen, während andere dazu neigen, ähnliche Formulierungen zu verwenden. Es gab auch signifikante Unterschiede in der Anzahl der generierten Wörter und der Menge an Dialog, Beschreibungen und Absätzen, die von jedem Modell erzeugt wurden. Das Evaluierungs -Feedback ergab, dass ChatGPT eine "raffiniertere" Prosa vorschlägt, während Claude weniger lila Prosa empfiehlt. Basierend auf diesen Erkenntnissen habe ich eine Liste von Imbissbuden zusammengestellt, die in die nächste Aufforderung einbezogen werden, wobei ich mich auf Präzision, abwechslungsreiche Satzstrukturen, starke Verben, einzigartige Wendungen zu Fantasy -Motiven, konsistenten Ton, unterschiedlicher Erzählerstimme und ansprechendes Tempo konzentrierte. Eine andere Technik, die Sie berücksichtigen sollten, ist das Feedback und die Umschreibung des Textes basierend auf diesem Feedback.
Ich bin offen für die Zusammenarbeit mit anderen, um für jedes Modell weiterzugeben und ihre Fähigkeiten bei kreativen Schreibaufgaben zu erkunden.
Modelle haben inhärente Formatierungsverzerrungen. Einige Modelle bevorzugen Bindestriche für Listen, andere Sternchen. Bei der Verwendung dieser Modelle ist es hilfreich, ihre Vorlieben für konsistente Ausgänge zu spiegeln.
Formatierende Tendenzen:
Lama 3 bevorzugt Listen mit kühnen Überschriften und Sternchen.
Beispiel: Fettdrucker Titelfall Überschrift
Listen Sie Elemente mit Sternchen nach zwei neuen Zeilen auf
Listen Sie Elemente auf, die durch eine neue Linie getrennt sind
Nächste Liste
Weitere Listenelemente
Usw...
Ein paar Schussbeispiele:
Systemumfortige Einhaltung:
Kontextfenster:
Zensur:
Intelligenz:
Konsistenz:
Listen und Formatierung:
CHAT -Einstellungen:
Pipeline -Einstellungen:
Lama 3 ist flexibel und intelligent, hat aber Kontext und zitierende Einschränkungen. Passen Sie die Auflaufmethoden entsprechend an.
Alle Kommentare sind willkommen. Öffnen Sie ein Problem oder senden Sie eine Pull -Anfrage, wenn Sie Fehler finden oder Empfehlungen zur Verbesserung haben.
Dieses Projekt ist lizenziert unter: Attribution-Noncommercial-noderivatives (BY-NC-ND) Lizenz siehe: https://creativcommons.org/licenses/by-nc-nd/4.0/deed.en


