IP Adapter
1.0.0
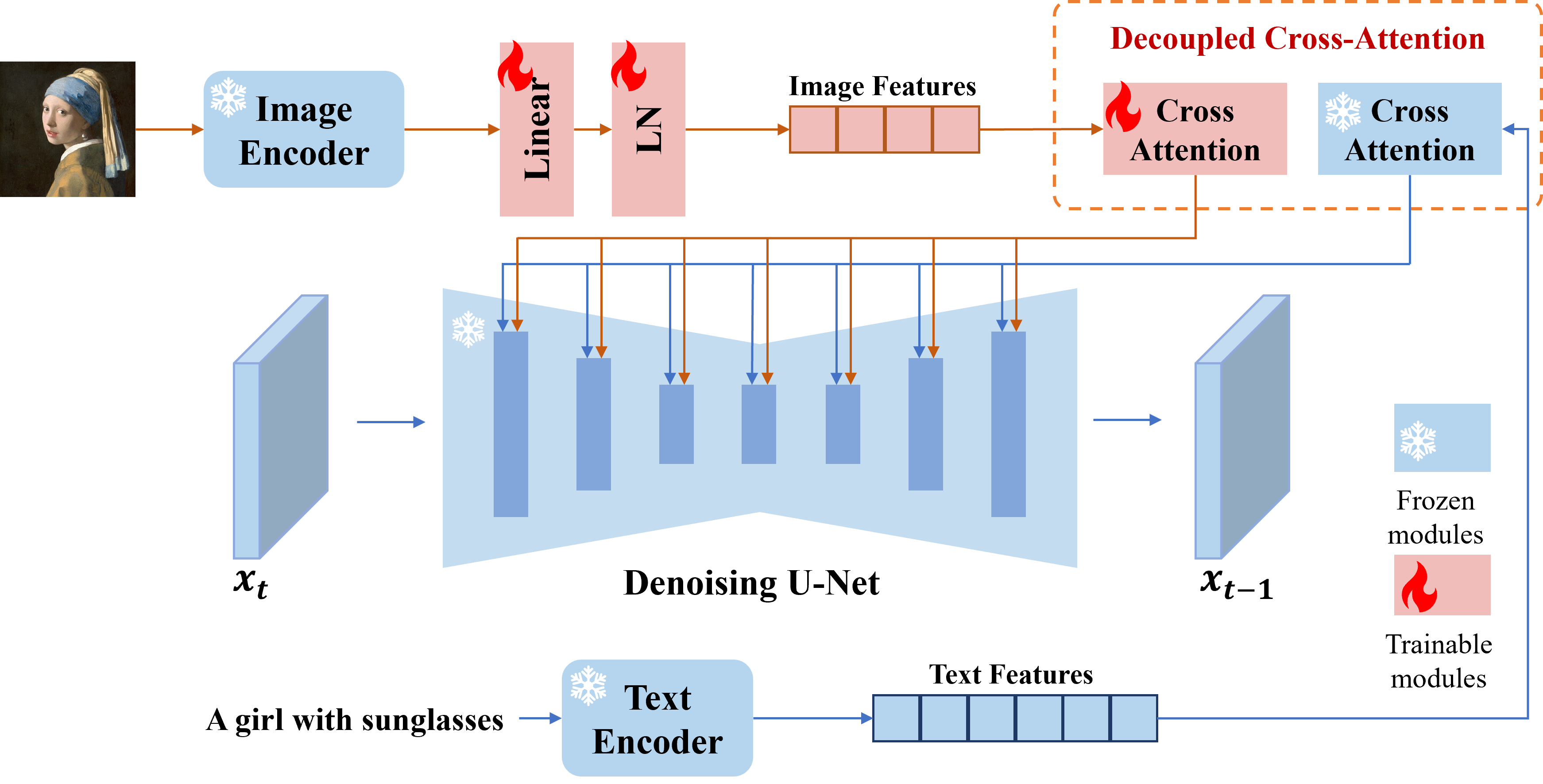
Wir präsentieren IP-Adapter, einen effektiven und leichten Adapter, um die Bildaufforderung für die vorgebildeten Text-zu-Image-Diffusionsmodelle zu erzielen. Ein IP-Adapter mit nur 22M-Parametern kann eine vergleichbare oder sogar bessere Leistung zu einem fein abgestimmten Bildaufforderung erringen. IP-Adapter kann nicht nur auf andere benutzerdefinierte Modelle verallgemeinert werden, die aus demselben Basismodell fein abgestimmt sind, sondern auch auf steuerbare Generation mit vorhandenen steuerbaren Tools. Darüber hinaus kann die Bildaufforderung auch gut mit der Textaufforderung funktionieren, um die multimodale Bildgenerierung zu erreichen.
# install latest diffusers
pip install diffusers==0.22.1
# install ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# download the models
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# then you can use the notebook
Sie können Modelle von hier herunterladen. Um die Demo auszuführen, sollten Sie auch die folgenden Modelle herunterladen:









Beste Practice
scale=1.0 und text_prompt="" (oder einige generische Texteingabeaufforderungen, z. B. "beste Qualität", auch eine negative Textaufforderung verwenden). Wenn Sie die scale senken, können vielfältigere Bilder generiert werden, die jedoch möglicherweise nicht so übereinstimmend mit der Bildaufforderung stimmen.scale anpassen, um die besten Ergebnisse zu erzielen. In den meisten Fällen kann das Einstellen scale=0.5 gute Ergebnisse erzielen. Für die Version von SD 1.5 empfehlen wir die Verwendung von Community -Modellen, um gute Bilder zu generieren.IP-Adapter für nicht qualifizierte Bilder
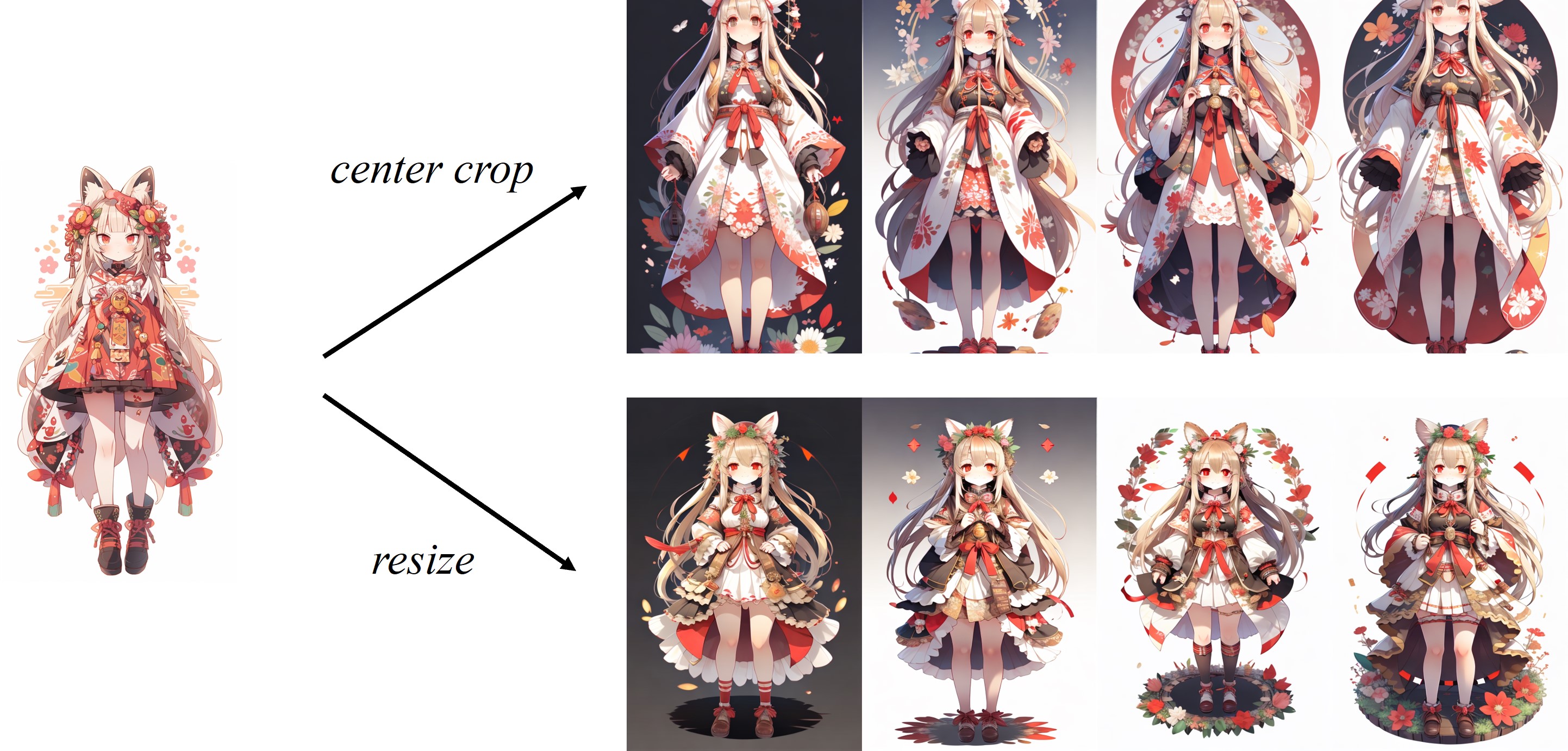
Da das Bild im Standard-Bildprozessor von Clip in der Mitte geschnitten ist, eignet sich IP-Adapter am besten für quadratische Bilder. Für die nicht quadratischen Bilder wird es die Informationen außerhalb des Zentrums verpassen. Sie können jedoch nur die Größe von 224x224 für nicht quadratische Bilder ändern. Der Vergleich lautet wie folgt:
Der Vergleich von IP-Adapter_xl mit Reimagine XL wird wie folgt angezeigt:

Verbesserungen in der neuen Version (2023.9.8) :
Für das Training sollten Sie Accelerate und Ihren eigenen Datensatz zu einer JSON -Datei einbauen.
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16"
tutorial_train.py
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/"
--image_encoder_path="{image_encoder_path}"
--data_json_file="{data.json}"
--data_root_path="{image_path}"
--mixed_precision="fp16"
--resolution=512
--train_batch_size=8
--dataloader_num_workers=4
--learning_rate=1e-04
--weight_decay=0.01
--output_dir="{output_dir}"
--save_steps=10000
Sobald das Training abgeschlossen ist, können Sie die Gewichte mit dem folgenden Code umwandeln:
import torch
ckpt = "checkpoint-50000/pytorch_model.bin"
sd = torch . load ( ckpt , map_location = "cpu" )
image_proj_sd = {}
ip_sd = {}
for k in sd :
if k . startswith ( "unet" ):
pass
elif k . startswith ( "image_proj_model" ):
image_proj_sd [ k . replace ( "image_proj_model." , "" )] = sd [ k ]
elif k . startswith ( "adapter_modules" ):
ip_sd [ k . replace ( "adapter_modules." , "" )] = sd [ k ]
torch . save ({ "image_proj" : image_proj_sd , "ip_adapter" : ip_sd }, "ip_adapter.bin" )Dieses Projekt ist bestrebt, die Domäne der AI-gesteuerten Bildgenerierung positiv zu beeinflussen. Den Benutzern wird die Freiheit gewährt, Bilder mit diesem Tool zu erstellen. Es wird jedoch erwartet, dass sie die lokalen Gesetze einhalten und auf verantwortungsvolle Weise nutzen. Die Entwickler übernehmen keine Verantwortung für potenziellen Missbrauch durch Benutzer.
Wenn Sie IP-Adapter für Ihre Forschung und Anwendungen nützlich finden, zitieren Sie bitte mit diesem Bibtex:
@article { ye2023ip-adapter ,
title = { IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models } ,
author = { Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei } ,
booktitle = { arXiv preprint arxiv:2308.06721 } ,
year = { 2023 }
}

