rl 6 nimmt
1.0.0
6 nimmt! ist ein preisgekröntes Kartenspiel für zwei bis zehn Spieler von 1994. Zitat von Wikipedia:
Das Spiel verfügt über 104 Karten, die jeweils eine Nummer und ein bis sieben Bullenköpfe Symbole tragen, die Strafpunkte darstellen. Eine Runde von zehn Runden wird gespielt, wo alle Spieler eine Karte ihrer Wahl auf den Tisch legen. Die platzierten Karten sind nach festen Regeln auf vier Zeilen angeordnet. Wenn der Spieler in einer Reihe, die bereits fünf Karten hat, wird diese fünf Karten erhält, die als Strafpunkte gelten, die am Ende der Runde insgesamt erhöht sind.
6 nimmt! ist ein wettbewerbsfähiges Spiel unvollständiger Informationen und eine große Menge an Stochastizität. Gutes Spielen erfordert ein bisschen Planung. Das gleichzeitige Spielspiel eignet sich an Mind Games und Bluffing, während eine langfristige Strategie erforderlich ist, um nicht in schwierigen Endspielpositionen zu landen.
Wir haben eine leicht vereinfachte Version von 6 nimmt implementiert! Als Openai -Fitnessumgebung. Im Gegensatz zum Originalspiel kann der Spieler beim Spielen einer niedrigeren Karte als die letzte Karte in allen Stapeln nicht frei wählen, welcher Stapel ersetzen soll, sondern wird immer den Stapel mit der geringsten Anzahl von Elfmeterpunkten nehmen.
Bisher haben wir die folgenden Agenten implementiert:
Als erster Test haben wir ein einfaches Selbstvertretungsturnier durchgeführt. Beginnend mit fünf ungeschulten Agenten haben wir insgesamt 4000 Spiele gespielt. Für jedes Spiel haben wir zufällig zwei, drei oder vier Agenten ausgewählt, um sie zu spielen (und zu lernen). Alle 400 Spiele klonierten wir den besten Agenten und haben einige der schlechteren Leistung ausgelöst. Am Ende haben wir einfach die beste Instanz jedes Agenten -Typs gehalten.
Ergebnisse über alle Spiele:
| Agent | Spiele gespielt | Mittelwert | Fraktion gewinnen | Elo |
|---|---|---|---|---|
| Alpha0.5 | 2246 | -7.79 | 0,42 | 1806 |
| MCS | 2314 | -8.06 | 0,40 | 1745 |
| Acer | 1408 | -12.28 | 0,18 | 1629 |
| D3qn | 1151 | -13.32 | 0,17 | 1577 |
| Zufällig | 1382 | -13.49 | 0,19 | 1556 |
So die Leistung (gemessen in ELO) der Modelle, die im Verlauf des Turniers entwickelt wurden:
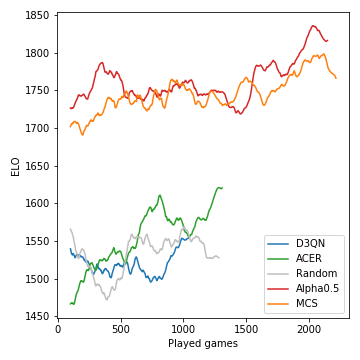
Die Monte-Carlo-Baumsuche ist entscheidend und führt zu starken Spielern. Die modellfreien RL-Agenten dagegen haben Schwierigkeiten, die zufällige Grundlinie klar zu übertreffen. Aufgrund der stochastischen Natur des Spiels sind die Gewinnwahrscheinlichkeiten und ELO -Unterschiede nicht annähernd so drastisch, wie sie beispielsweise für Schach sein könnten. Beachten Sie, dass wir keine der vielen Hyperparameter abgestimmt haben.
Nach dieser Selbstvertriebsphase stand der Alpha0.5-Agent Merle, einem der besten 6 Nimmt! Spieler in unserer Gruppe von Freunden für 5 Spiele. Dies sind die Punktzahlen:
| Spiel | 1 | 2 | 3 | 4 | 5 | Summe |
|---|---|---|---|---|---|---|
| Merle | -10 | -16 | -11 | -3 | -4 | -44 |
| Alpha0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
Angenommen, Sie haben Anaconda installiert, klonen Sie das Repo mit
git clone [email protected]:johannbrehmer/rl-6nimmt.git
und eine virtuelle Umgebung erstellen mit
conda env create -f environment.yml
conda activate rl
Sowohl Agents-Selbstspiele als auch Spiele zwischen einem menschlichen Spieler und geschulten Agenten werden in Simple_Tournament.ipynb demonstriert.
Zusammengestellt von Johann Brehmer und Marcel Gutsche.


