rlcard
RLCard 1.0.7
中文文档
RLCARD ist ein Toolkit für das Verstärkungslernen (RL) in Kartenspielen. Es unterstützt mehrere Kartenumgebungen mit benutzerfreundlichen Schnittstellen für die Implementierung verschiedener Verstärkungslernen und Suchalgorithmen. Das Ziel von RLCard ist es, Verstärkungslernen und unvollkommene Informationsspiele zu überbrücken. RLCARD wurde vom Data Lab an Rice und Texas A & M University sowie von Community -Mitwirkenden entwickelt.
Gemeinschaft:
Nachricht:
Die folgenden Spiele werden hauptsächlich von Mitwirkenden der Gemeinschaft entwickelt und gepflegt. Danke schön!
Vielen Dank an alle Mitwirkenden!




























Wenn Sie dieses Repo nützlich finden, können Sie zitieren:
Zha, Daochen et al. "RLCARD: Eine Plattform für Verstärkungslernen in Kartenspielen." Ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} Stellen Sie sicher, dass Sie Python 3.6+ und PIP installiert haben. Wir empfehlen, die stabile Version von rlcard mit pip zu installieren:
pip3 install rlcard
Die Standardinstallation umfasst nur die Kartenumgebungen. Um die Pytorch -Implementierung der Trainingsalgorithmen zu verwenden, laufen Sie aus
pip3 install rlcard[torch]
Wenn Sie in China sind und der obige Befehl zu langsam ist, können Sie den von der Tsinghua University bereitgestellten Spiegel verwenden:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
Alternativ können Sie die neueste Version klonen (wenn Sie in China sind und GitHub langsam ist, können Sie den Spiegel in Gitee verwenden):
git clone https://github.com/datamllab/rlcard.git
oder nur einen Zweig klonen, um es schneller zu machen:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
Dann installieren mit
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
Wir bieten auch die Conda -Installationsmethode:
conda install -c toubun rlcard
Die Conda -Installation bietet nur die Kartenumgebungen, Sie müssen Pytorch in Ihren Anforderungen manuell installieren.
Ein kurzes Beispiel ist wie unten.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCard kann flexibel mit verschiedenen Algorithmen verbunden sein. Siehe folgende Beispiele:
Ausführen examples/human/leduc_holdem_human.py um mit dem vorgebildeten Leduc Hold'em-Modell zu spielen. Leduc Hold'em ist eine vereinfachte Version von Texas Hold'em. Regeln finden Sie hier.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
Wir bieten auch eine GUI für das einfache Debuggen. Bitte überprüfen Sie hier. Einige Demos:
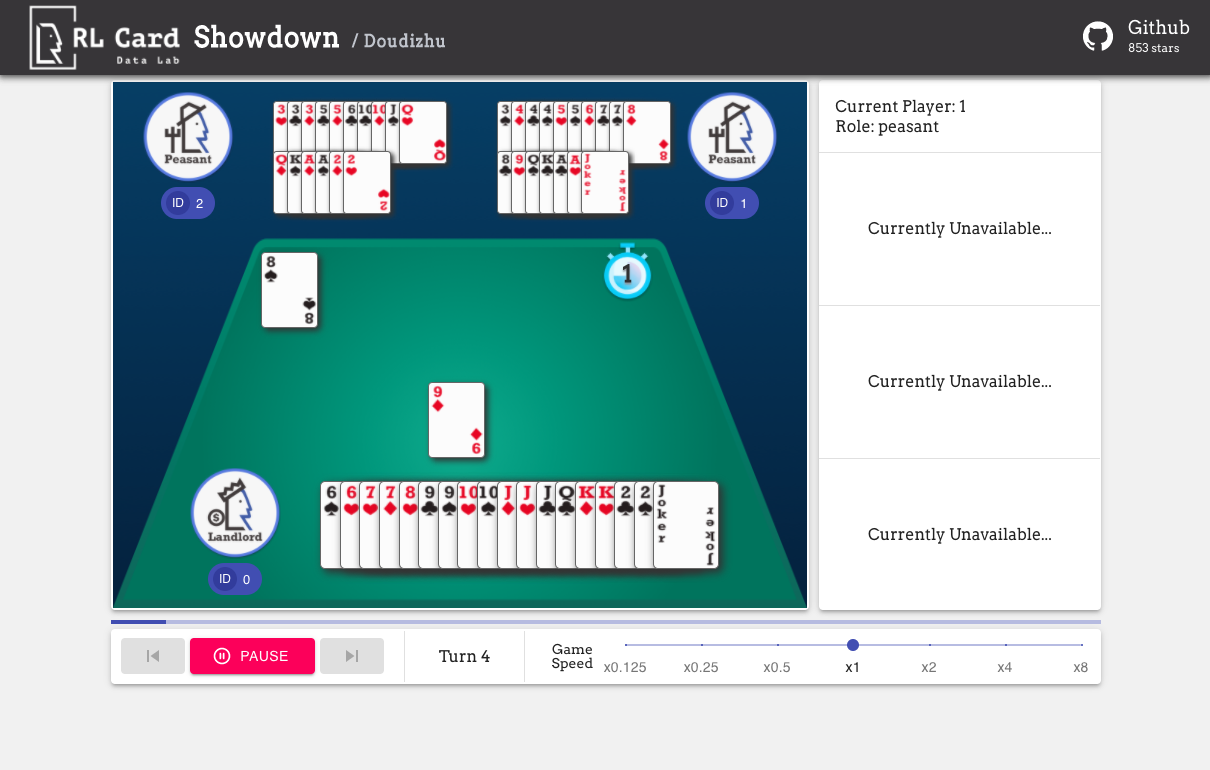
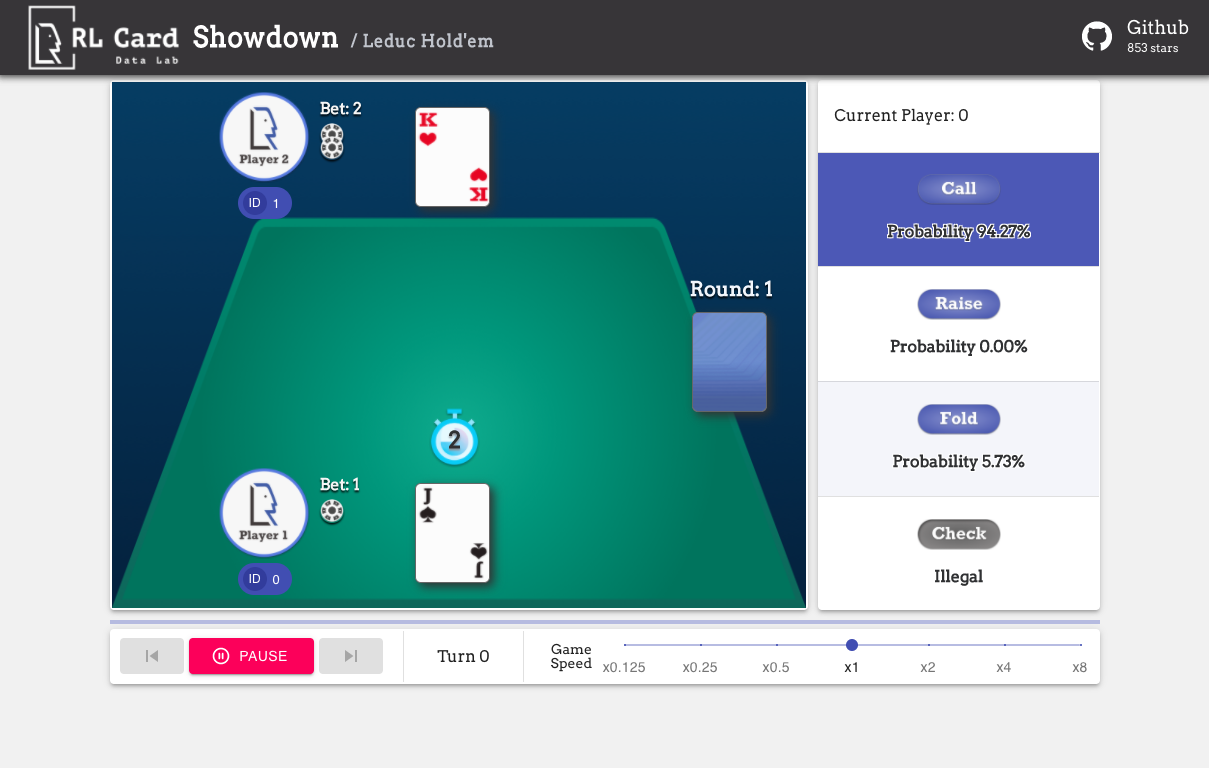
Wir bieten eine Komplexitätsschätzung für die Spiele zu verschiedenen Aspekten. Infosetnummer: Die Anzahl der Informationssätze; Infosetgröße: Die durchschnittliche Anzahl der Zustände in einem einzigen Informationssatz; Aktionsgröße: Die Größe des Aktionsraums. Name: Der Name, der an rlcard.make übergeben werden sollte, um die Spielumgebung zu erstellen. Wir geben auch den Link zur Dokumentation und zum zufälligen Beispiel an.
| Spiel | Infoset -Nummer | Infosetgröße | Aktionsgröße | Name | Verwendung |
|---|---|---|---|---|---|
| Blackjack (Wiki, Baike) | 10^3 | 10^1 | 10^0 | Blackjack | doc, Beispiel |
| Leduc Hold'em (Papier) | 10^2 | 10^2 | 10^0 | Leduc-holdem | doc, Beispiel |
| Limit Texas Hold'em (Wiki, Baike) | 10^14 | 10^3 | 10^0 | Grenzholdem | doc, Beispiel |
| Dou dizhu (Wiki, Baike) | 10^53 ~ 10^83 | 10^23 | 10^4 | Doudizhu | doc, Beispiel |
| Mahjong (Wiki, Baike) | 10^121 | 10^48 | 10^2 | Mahjong | doc, Beispiel |
| No-Limit Texas Hold'em (Wiki, Baike) | 10^162 | 10^3 | 10^4 | No-Limit-Holdem | doc, Beispiel |
| Uno (Wiki, Baike) | 10^163 | 10^10 | 10^1 | Uno | doc, Beispiel |
| Gin Rummy (Wiki, Baike) | 10^52 | - - | - - | Gin-Rummy | doc, Beispiel |
| Brücke (Wiki, Baike) | - - | - - | Brücke | doc, Beispiel |
| Algorithmus | Beispiel | Referenz |
|---|---|---|
| Deep Monte-Carlo (DMC) | Beispiele/run_dmc.py | [Papier] |
| Deep Q-Learning (DQN) | Beispiele/run_rl.py | [Papier] |
| Neuronales fiktives Selbstspiel (NFSP) | Beispiele/run_rl.py | [Papier] |
| Kontrolle Bedauernminimierung (CFR) | Beispiele/run_cfr.py | [Papier] |
Wir stellen einen Modellzoo zur Verfügung, um als Baselines zu dienen.
| Modell | Erläuterung |
|---|---|
| Leduc-holdem-cfr | Vorausgebildeter CFR-Modell (Chance Proble) auf LEDUC Hold'em |
| LEDUC-HOLDEM-RULE-V1 | Regelbasiertes Modell für Leduc Hold'em, v1 |
| LEDUC-HOLDEM-RULE-V2 | Regelbasiertes Modell für Leduc Hold'em, v2 |
| UNO-RULE-V1 | Regelbasiertes Modell für UNO, v1 |
| Grenzholdem-Rule-V1 | Regelbasiertes Modell für Limit Texas Hold'em, v1 |
| Doudizhu-Rule-V1 | Regelbasiertes Modell für Dou dizhu, v1 |
| Gin-Rummy-Novice-Rule | Gin Rommé Novice Rule Model |
Sie können die folgende Schnittstelle verwenden, um eine Umgebung zu erstellen. Sie können optional einige Konfigurationen mit einem Wörterbuch angeben.
env_id ist eine Umgebung Zeichenfolge; config ist ein Wörterbuch, das einige Umgebungskonfigurationen angibt, die wie folgt sind.seed : Standard None . Legen Sie eine Umgebung ein lokaler Zufallssamen für die Reproduktion der Ergebnisse.allow_step_back : Standard False . True , wenn die Funktion step_back im Baum nach hinten nach hinten durchquert werden kann.game_ . Derzeit unterstützen wir nur game_num_players in Blackjack ,.Sobald die Umgebung hergestellt ist, können wir auf einige Informationen des Spiels zugreifen.
Staat ist ein Python -Wörterbuch. Es besteht aus Beobachtungsstatus state['obs'] , rechtlichen Handlungen state['legal_actions'] , Roh state['raw_obs'] und RAW Legal Action state['raw_legal_actions'] .
Die folgenden Schnittstellen bieten eine grundlegende Verwendung. Es ist einfach zu bedienen, aber es hat Annahmen für den Agenten. Der Agent muss die Agentenvorlage folgen.
agents ist eine Liste von Agent . Die Länge der Liste sollte der Anzahl der Spieler im Spiel entsprechen.set_agents aufgerufen wurden. Wenn is_training True ist, wird die step im Agenten zum Spielen des Spiels verwendet. Wenn is_training False ist, wird eval_step stattdessen aufgerufen.Für die fortgeschrittene Verwendung ermöglichen die folgenden Schnittstellen flexible Vorgänge auf dem Spielbaum. Diese Schnittstellen sind keine Annahmen für den Agenten.
action kann eine rohe Aktion oder Ganzzahl sein; raw_action sollte True sein, wenn die Aktion RAW -Aktion (Zeichenfolge) ist.allow_step_back True ist. Machen Sie einen Schritt rückwärts. Dies kann für Algorithmen verwendet werden, die auf dem Spielbaum wie CFR (Chance -Sampling) arbeiten.True , wenn das aktuelle Spiel vorbei ist. Kehren Sie anderen Wege False zurück.player_id entspricht.Die Zwecke der Hauptmodule sind wie unten aufgeführt:
Weitere Unterlagen finden Sie in den Dokumenten für allgemeine Einführungen. API -Dokumente finden Sie auf unserer Website.
Der Beitrag zu diesem Projekt wird sehr geschätzt! Bitte erstellen Sie ein Problem für Feedbacks/Fehler. Wenn Sie Codes beitragen möchten, lesen Sie bitte den beitragenden Leitfaden. Wenn Sie Fragen haben, wenden Sie sich bitte an Daochen Zha unter [email protected].
Wir möchten JJ World Network Technology Co., Ltd für die großzügige Unterstützung und alle Beiträge der Community -Mitwirkenden danken.


