kubeai
helm-chart-models-0.9.0
Erhalten Sie die Ausführungen auf Kubernetes: LLMs, Einbettungen, Sprach-zu-Text.
✅️ Drop-In-Ersatz für OpenAI mit API-Kompatibilität
⚖️ Skala von Null, autoscale basierend auf der Last
? Servieren von Textgenerierungsmodellen (LLMs, VLMs usw.)
Rede zu Text -API
? Einbettung/Vektor -API
Multi-Plattform: CPU nur, GPU, TPU
? Modellieren mit gemeinsam genutzten Dateisystemen (EFS, FileStore usw.)
Null -Abhängigkeiten (hängt nicht von iStio, Ritter usw. ab)
Chat UI enthalten (OpenWebui)
? Betreibt OSS -Modellserver (VllM, Ollama, Fasterwhisper, Infinity)
✉ Stream/Batch -Inferenz über Messaging -Integrationen (Kafka, Pubsub usw.)
Zitate aus der Community:
Wiederverwendbare, gut abstrahierte Lösung für LLMs - Mike Ensor
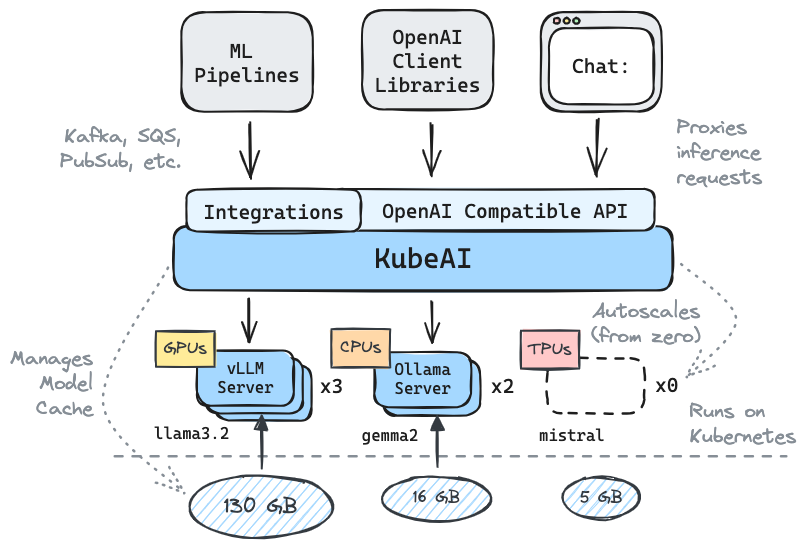
Kubeai dient einer OpenAI -kompatiblen HTTP -API. Administratoren können ML -Modelle über kind: Model Kubernetes benutzerdefinierte Ressourcen konfigurieren. Kubeai kann als Modelloperator (siehe Operatormuster) angesehen werden, das VLLM- und Ollama -Server verwaltet.
Erstellen Sie einen lokalen Cluster mit Art oder Minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startFügen Sie das Kubeai -Helm -Repository hinzu.
helm repo add kubeai https://www.kubeai.org
helm repo updateInstallieren Sie Kubeai und warten Sie, bis alle Komponenten fertig sind (kann eine Minute dauern).
helm install kubeai kubeai/kubeai --wait --timeout 10mInstallieren Sie einige vordefinierte Modelle.
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlBevor Sie zu den nächsten Schritten übergehen, starten Sie eine Uhr auf Pods in einem eigenständigen Terminal, um zu sehen, wie Kubeai Modelle bereitstellt.
kubectl get pods --watch Da wir minReplicas: 1 für das Gemma -Modell, sollten Sie bereits einen Modellschalen sehen.
Starten Sie einen lokalen Port-Vorlauf zur gebündelten Chat-Benutzeroberfläche.
kubectl port-forward svc/openwebui 8000:80Öffnen Sie jetzt Ihren Browser für Localhost: 8000 und wählen Sie das Gemma -Modell aus, um mit dem Chatten zu beginnen.
Wenn Sie zum Browser zurückkehren und einen Chat mit QWEN2 beginnen, werden Sie feststellen, dass es eine Weile dauern wird, bis sie zuerst antworten. Dies liegt daran, dass wir minReplicas: 0 für dieses Modell festlegen und Kubeai einen neuen Pod aufspannen muss (Sie können mit kubectl get models -oyaml qwen2-500m-cpu verifizieren).
Schauen Sie sich unsere Dokumentation auf kubeai.org an, um Informationen zu finden::
Liste der bekannten Anwender:
| Name | Beschreibung | Link |
|---|---|---|
| Teleskop | Teleskop verwendet Kubeai für Multi-Region-LLM-Inferenz mit großem Maßstab. | trytelescope.ai |
| Google Cloud Distributed Edge | Kubeai wird als Referenzarchitektur für die Auslassung am Rande enthalten. | LinkedIn, Gitlab |
| Lambda | Sie können Kubeai auf der Lambda AI Developer Cloud versuchen. Siehe Lambdas Tutorial und Video. | Lambda |
Wenn Sie Kubeai verwenden und als Adoptierer aufgeführt werden möchten, machen Sie bitte eine PR.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* Hinweis: Kubeai wurde aus einem Projekt namens Lingo geboren, das ein einfaches Kubernetes -LLM -Proxy mit Basic -Autoscaling war. Wir haben das Projekt als Kubeai (Ende August 2024) neu gestartet und die Roadmap auf das erweitert, was es heute ist.
? Vergessen Sie nicht, uns einen Stern auf Github zu bringen und dem Repo zu folgen, um auf dem neuesten Stand zu bleiben!
Informieren Sie uns über Funktionen, die Sie an Fragen sehen oder mit Fragen erreichen möchten. Besuchen Sie unseren Discord -Kanal, um sich der Diskussion anzuschließen!
Oder erreichen Sie einfach LinkedIn, wenn Sie eine Verbindung herstellen möchten:


