ChatIE
1.0.0
Offizielles Repository von Papier "Null-Shot-Informationsextraktion durch Chating mit Chatgpt". Bitte spielen Sie zu, schauen Sie sich an und geben Sie unser Repo für die aktiven Updates!
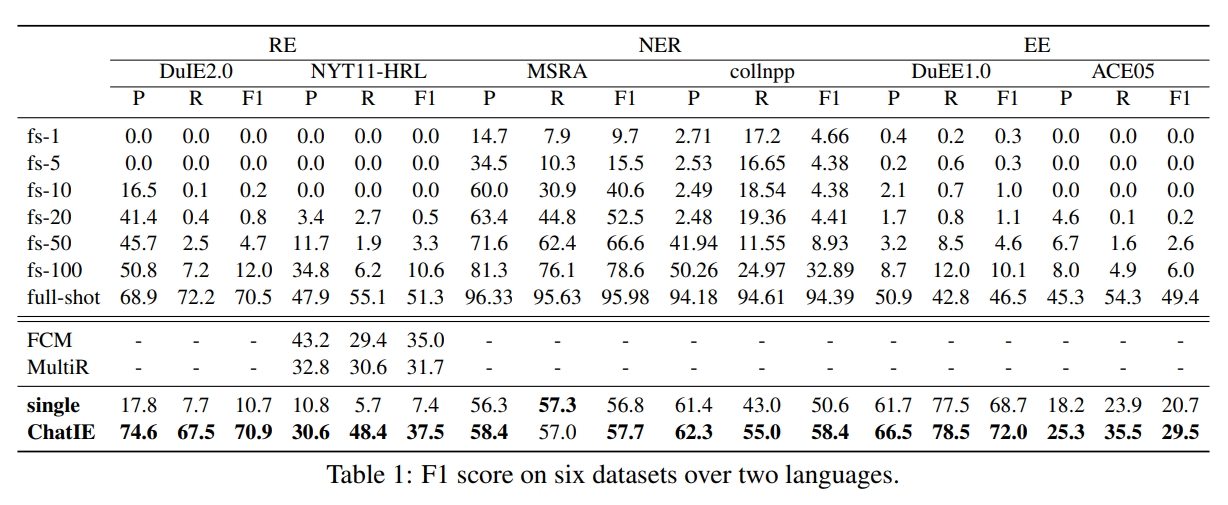
Die Extraktion von Null-Shot-Informationen (IE) zielt darauf ab, IE-Systeme aus dem nicht annotierten Text zu erstellen. Es ist eine Herausforderung aufgrund der geringen menschlichen Intervention. Herausfordernd, aber lohnend ist, dass Null-Shot-IE die Zeit und Aufwand, die die Datenkennzeichnung benötigt, verringert. Die jüngsten Bemühungen um Großsprachmodelle (LLMs, z. In dieser Arbeit fragen wir, ob starke IE -Modelle konstruiert werden können, indem Sie direkt LLMs auffordern. Insbesondere verwandeln wir die Null-Shot-IE-Aufgabe in ein Multiturn-Fragen-Beantwortungsproblem mit einem zweistufigen Framework (Chatie). Mit der Kraft von ChatGPT bewerten wir unser Rahmen ausführlich zu drei IE -Aufgaben: EntityRelation Triple Extract, benannte Entitätserkennung und Ereignisförderung. Empirische Ergebnisse von sechs Datensätzen in zwei Sprachen zeigen, dass Chatie eine beeindruckende Leistung erzielt und sogar einige Vollschussmodelle auf mehreren Datensätzen (z. B. NYT11-HRL) übertrifft. Wir glauben, dass unsere Arbeit den Aufbau von IE -Modellen mit begrenzten Ressourcen beleuchten könnte.
零样本信息抽取( Informationsextraktion , dh )旨在从无标注文本中建立 ie 系统 , 因为很少涉及人为干预 , 该问题非常具有挑战性。但零样本 ie 不再需要标注数据时耗费的时间和人力, 因此十分重要。近来的大规模语言模型(例如 GPT-3 , CHAT GPT )在零样本设置下取得了很好的表现 , 这启发我们探索基于提示的方法来解决零样本 IE 任务。我们提出一个问题 : 不经过训练来实现零样本信息抽取是否可行?我们将零样本 ie 任务转变为一个两阶段框架的多轮问答问题( chat dh), 并在三个 ie 任务中广泛评估了该框架 : 实体关系三元组抽取、命名实体识别和事件抽取。在两个语言的 6 个数据集上的实验结果表明 , Chat dh 取得了非常好的效果 , 甚至在几个数据集上(例如 nyt11-hrl)上超过了全监督模型的表现。我们的工作能够为有限资源下 dh 系统的建立奠定基础。 系统的建立奠定基础。
Update: Wir verwenden die offizielle API, das Tool wird schneller !!! Wenn der Schlüssel die Grenzen überschreitet, teilen Sie es uns bitte mit.
Hinweis: Die Reaktionsgeschwindigkeit hängt von der offiziellen OpenAI -Chatgpt -API ab. (Manchmal ist der Beamte zu überfüllt und die Geschwindigkeit wird langsam oder der ChatGPT wird überladen.) Darüber hinaus verwenden Sie Ihren eigenen OpenAI -Schlüssel besser, denn wenn unser Standardkonto gleichzeitig von mehreren Personen verwendet wird, kann das Konto möglicherweise sein überladen.
Hinweis: Da die offizielle API nicht im Inland verfügbar ist, verwenden wir API von Revchatgpt und V1 -Version. Aber es ist zu langsam , also raten wir, das Tool offline für das Studium zu verwenden. Wir werden die API in Zukunft weiter aktualisieren ( Todo ).
Wir bieten auch ein IE -Tool an, das auf GPT3.5 basiert. Sie können in GPT4ie sehen
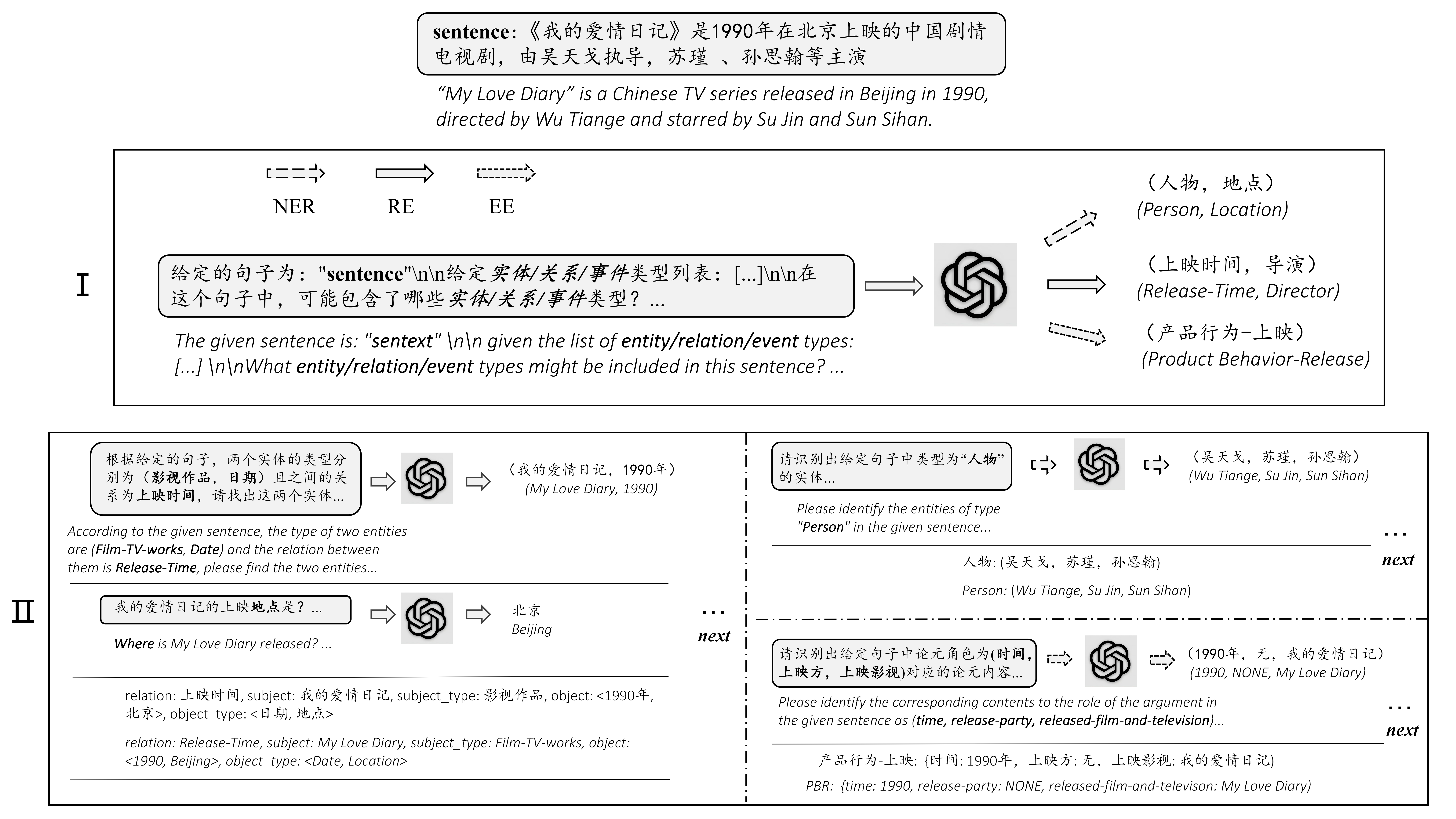
Chatie (Null-Shot-Informationsextraktion durch Chating mit ChatGPT) ist eine Open-Source- und leistungsstarke IE-Tool-Demo. Verbessert durch ChatGPT und Aufforderung soll es automatisch strukturierte Informationen aus einem Rohsatz extrahieren und eine wertvolle eingehende Analyse des Eingabestats durchführen. Durch die Nutzung wertvoller strukturierter Informationen hilft Unternehmen, inzwischen eindrucksvolles und geschäftsbetriebendes Entscheidungen zu treffen. 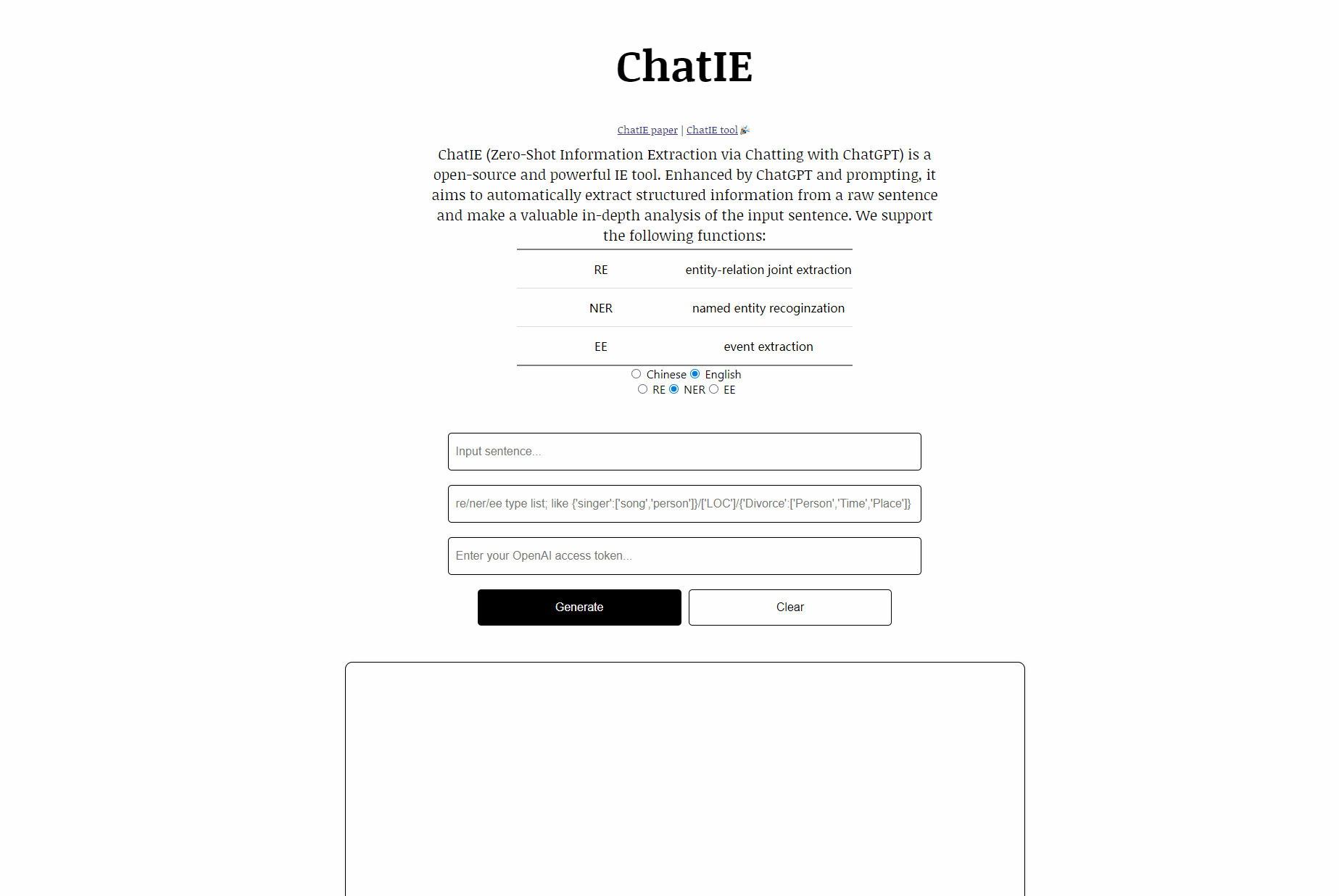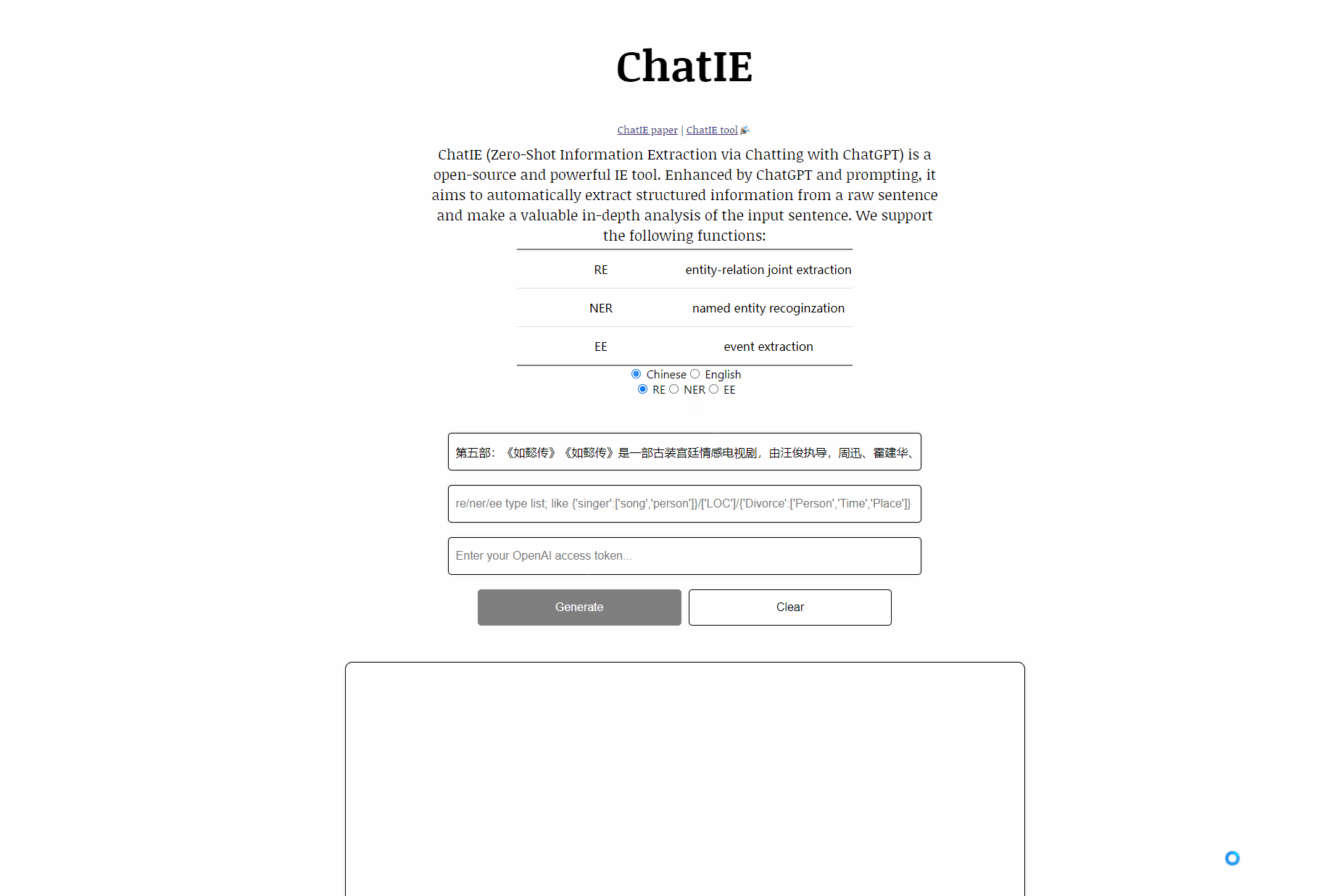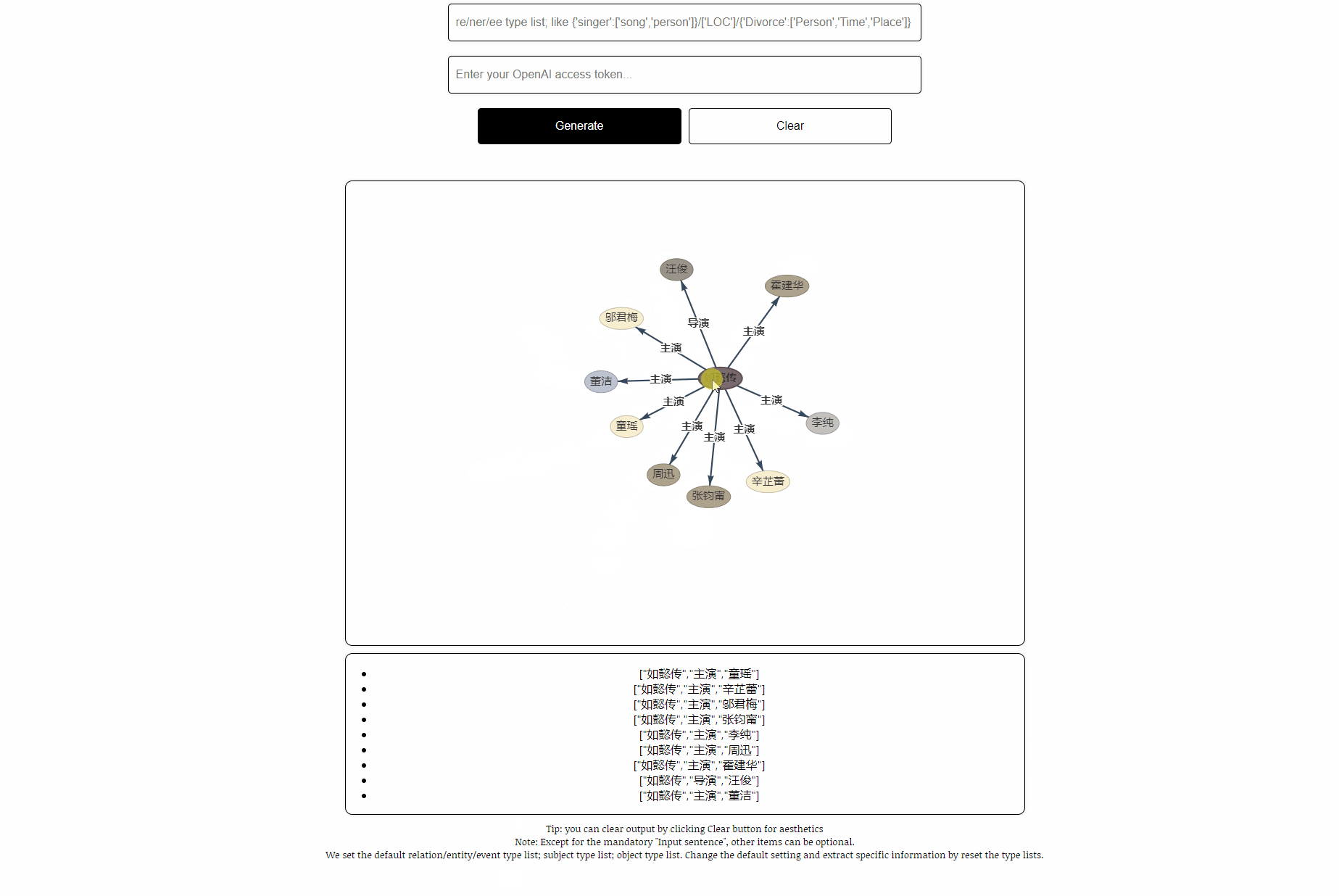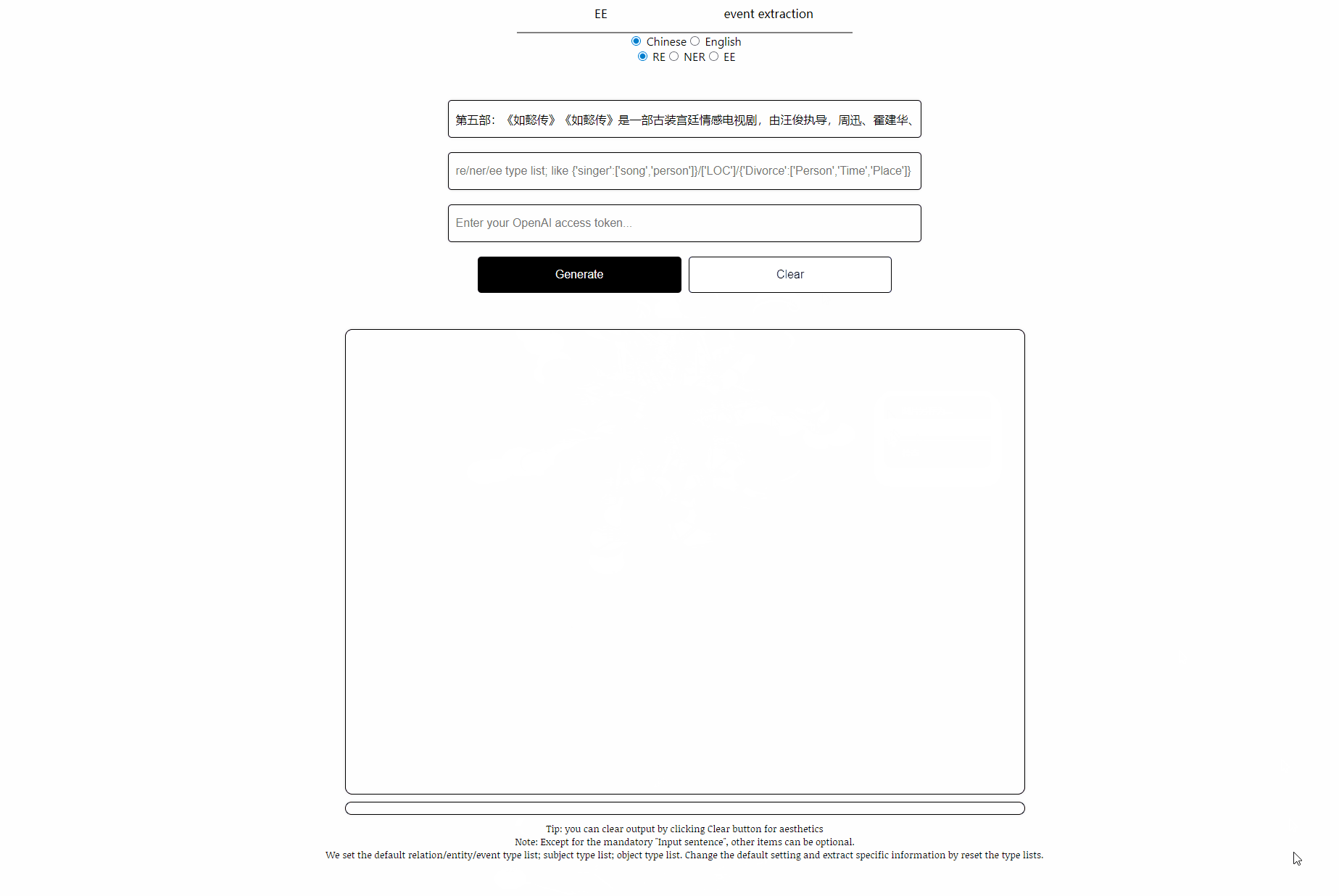
Wir unterstützen die folgenden Funktionen:
| Aufgabe | Name | Lauguages |
|---|---|---|
| RE | Entitätsbeziehungsgelenkextraktion | Chinesisch, Englisch |
| Ner | genannte Entitätsrecoginzation | Chinesisch, Englisch |
| EE | Ereignisextraktion | Chinesisch, Englisch |
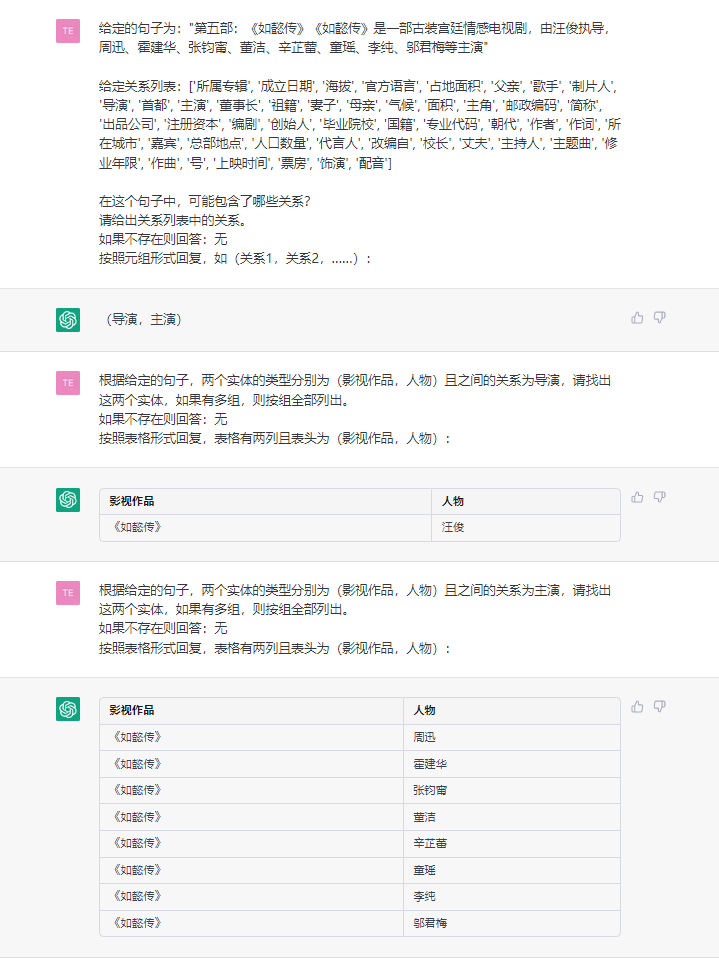
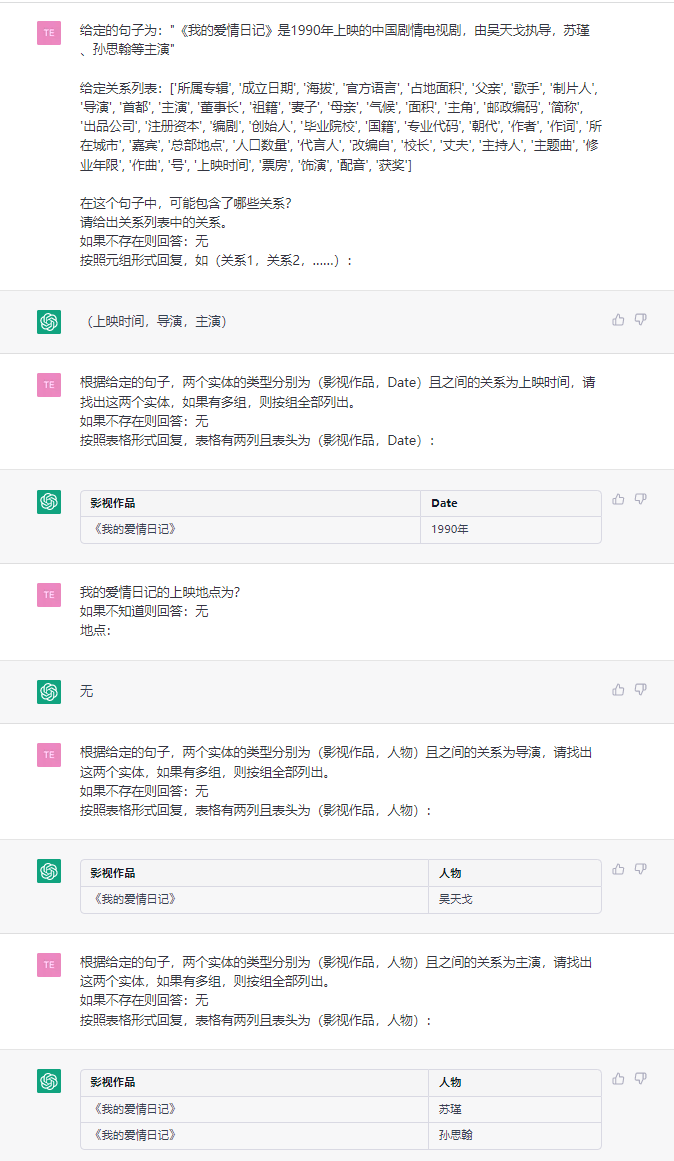
Diese Aufgabe zielt darauf ab, Dreifach aus einfachen Texten wie (China, Kapital, Peking) , (《如懿传》, 主演, 周迅) zu extrahieren.
PS: * OPTIONAL BEDEUTEN, Wir setzen den Standardwert für sie. Für eine bessere Extraktion sollten Sie jedoch die drei Liste gemäß den Anwendungsszenarien angeben.
Satz: Vier weitere Google -Führungskräfte Der Chief Financial Officer George Reyes; der Senior Vice President für Geschäftsoperationen, Shona Brown; der Chief Legal Officer David Drummond; und der Senior Vice President für Produktmanagement, Jonathan Rosenberg, verdiente jeweils 250.000 US -Dollar.
RTL: Standardend siehe Datei "Standardtypen"
OUPTUT: 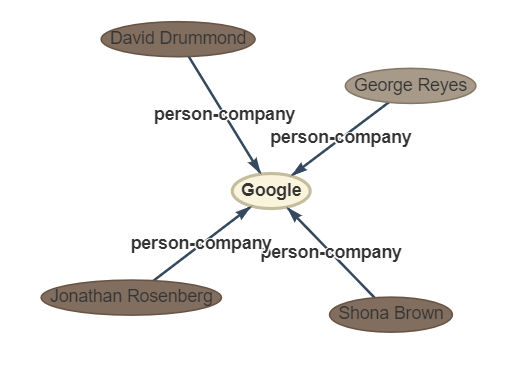
Satz:第五部 : 《如懿传》《如懿传》是一部古装宫廷情感电视剧 , 由汪俊执导 , 周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。 周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。
RTL: Standardend siehe Datei "Standardtypen"
OUPTUT: 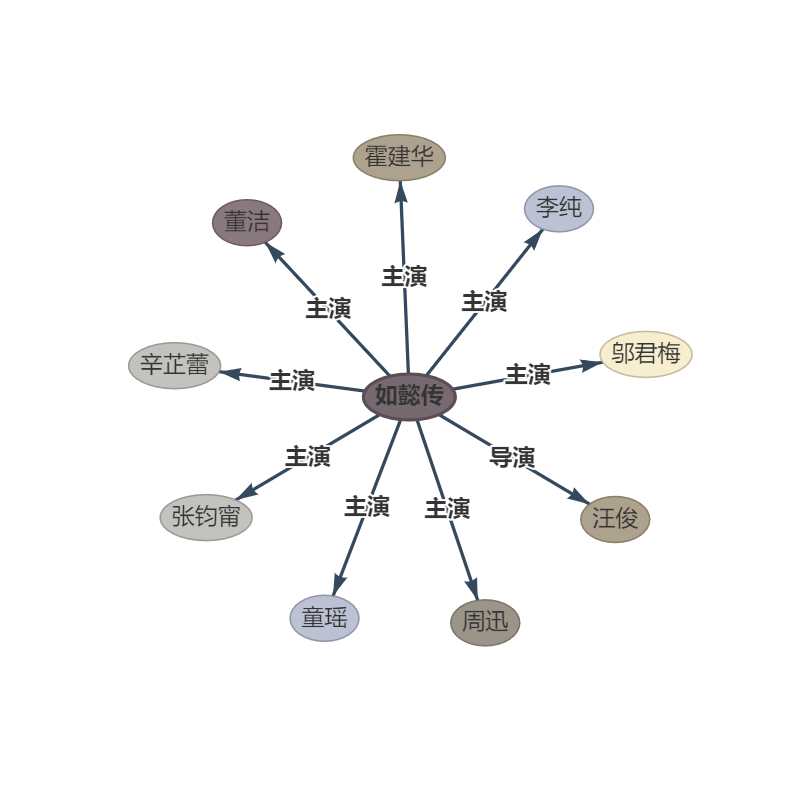
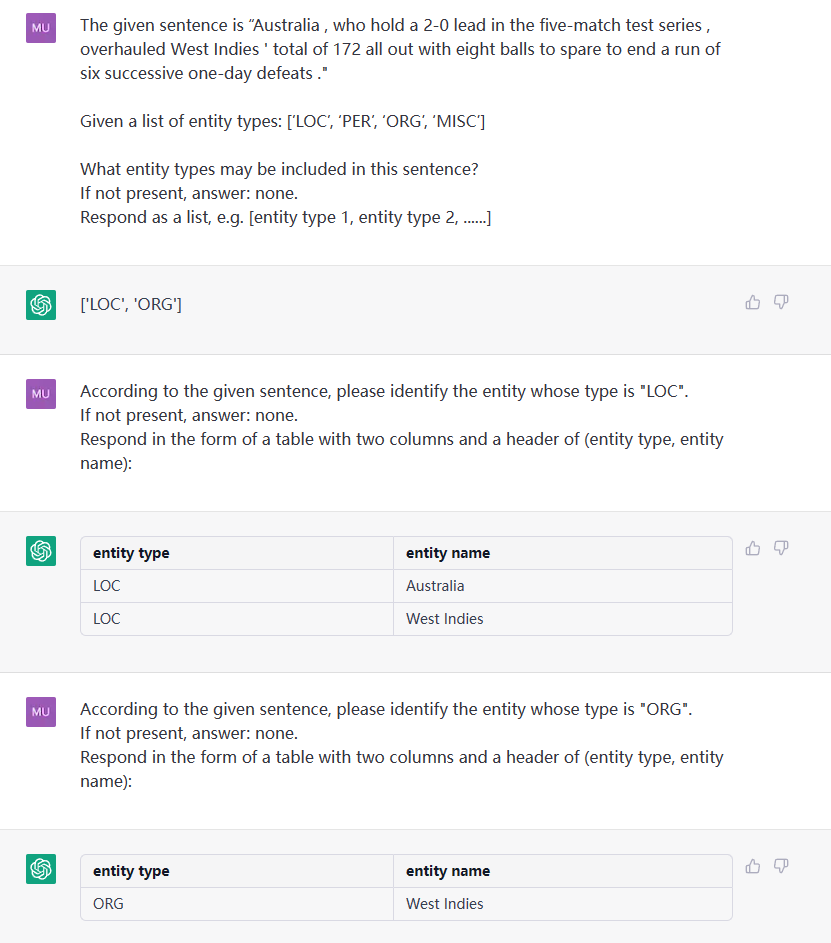
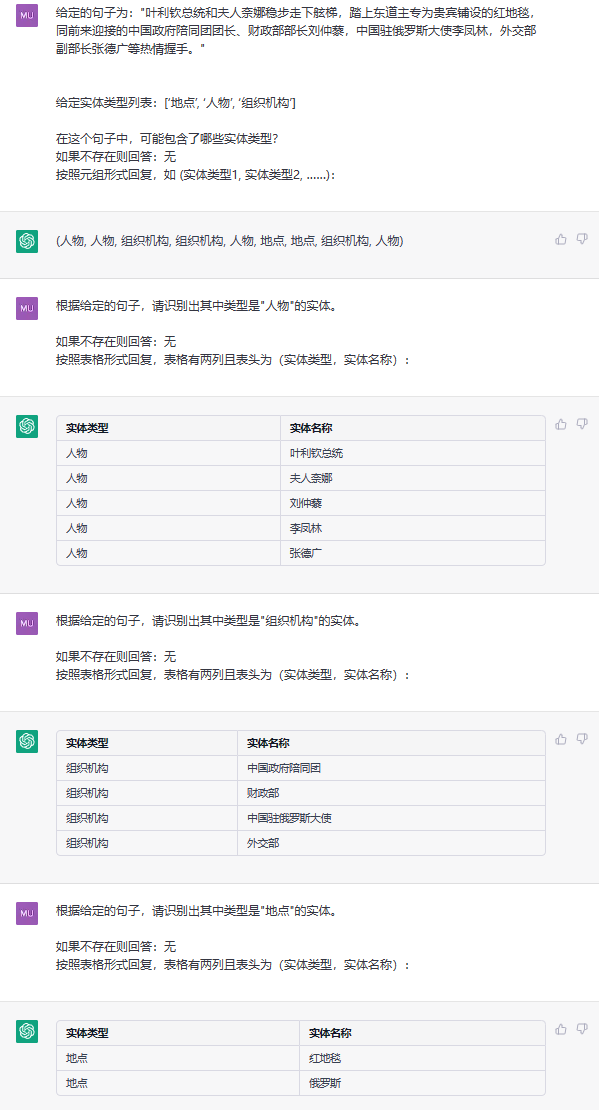
Diese Aufgabe zielt darauf ab, Entitäten aus einfachen Texten wie (loc, peking) , (人物, 周恩来) zu extrahieren.
Satz: James arbeitete für Google in Peking, die Hauptstadt Chinas. ETL: ['loc', 'misc', 'org', 'pro']
OUPTUT: 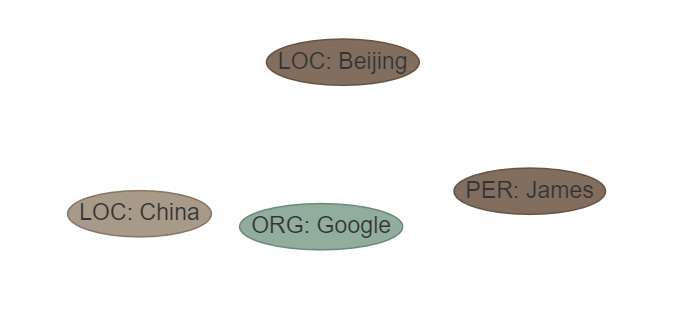
Satz:中国 产党创立于中华民国大陆时期 产党创立于中华民国大陆时期 , 由陈独秀和李大钊领导组织。
ETL: ['组织机构', '地点', '人物']
OUPTUT: 
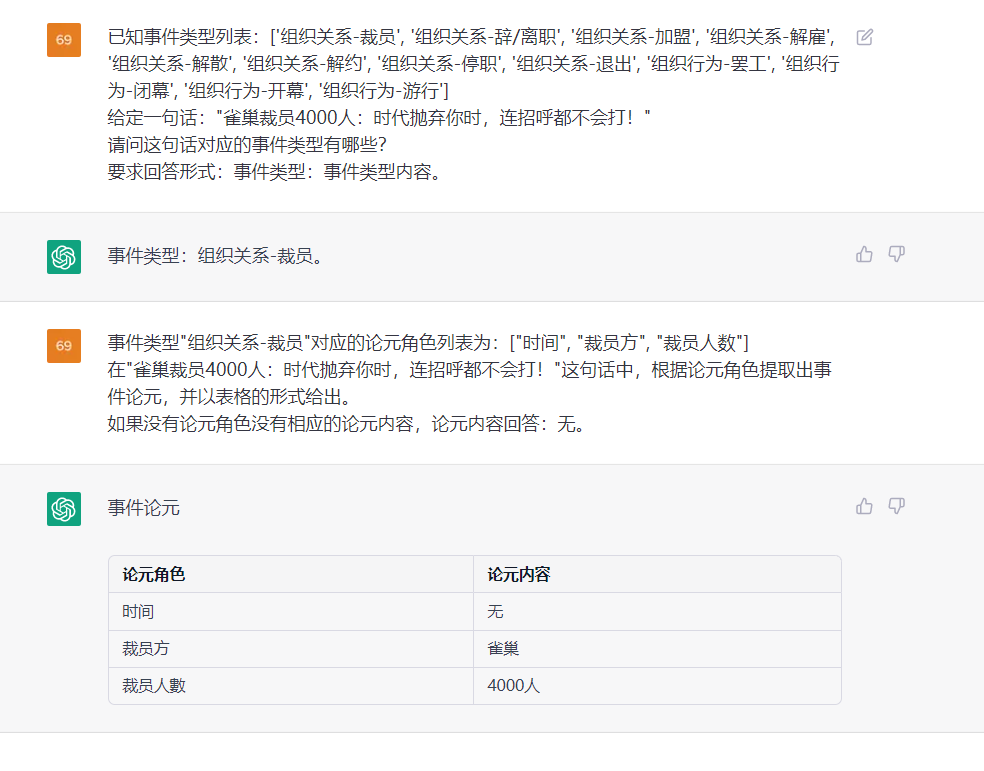
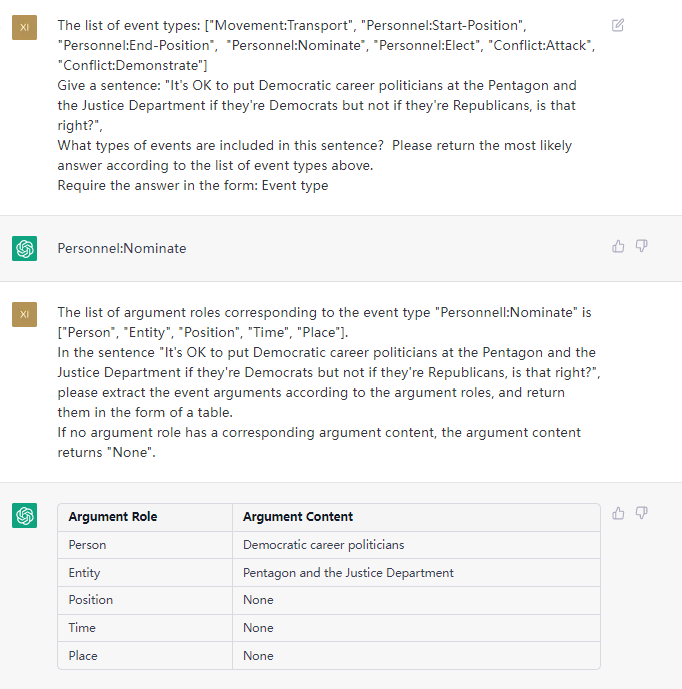
Diese Aufgabe zielt darauf ab, Ereignisse aus einfachen Texten wie {Life-Divorce: {Person: Bob, Zeit: Heute, Ort: America}}, {竞赛行为-晋级: {时间: 无, 晋级方: 西北狼, 晋级, 晋级, zu extrahieren.赛事: 中甲榜首之争}} .
Satz: Gestern haben sich Bob und seine Frau in Guangzhou geschieden.
ETL: Standardend siehe Datei "Standardtypen"
OUPTUT: 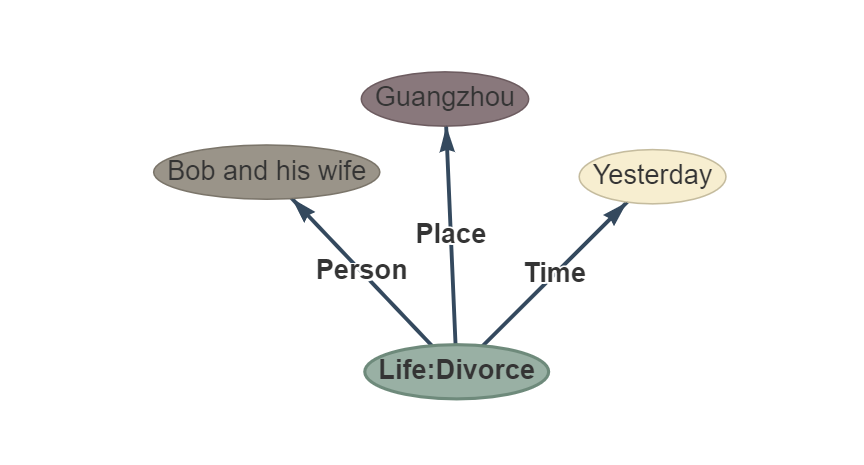
Satz:在 2022 年卡塔尔世界杯决赛中 , 阿根廷以点球大战险胜法国。 阿根廷以点球大战险胜法国。
ETL: Standardend siehe Datei "Standardtypen"
OUPTUT: 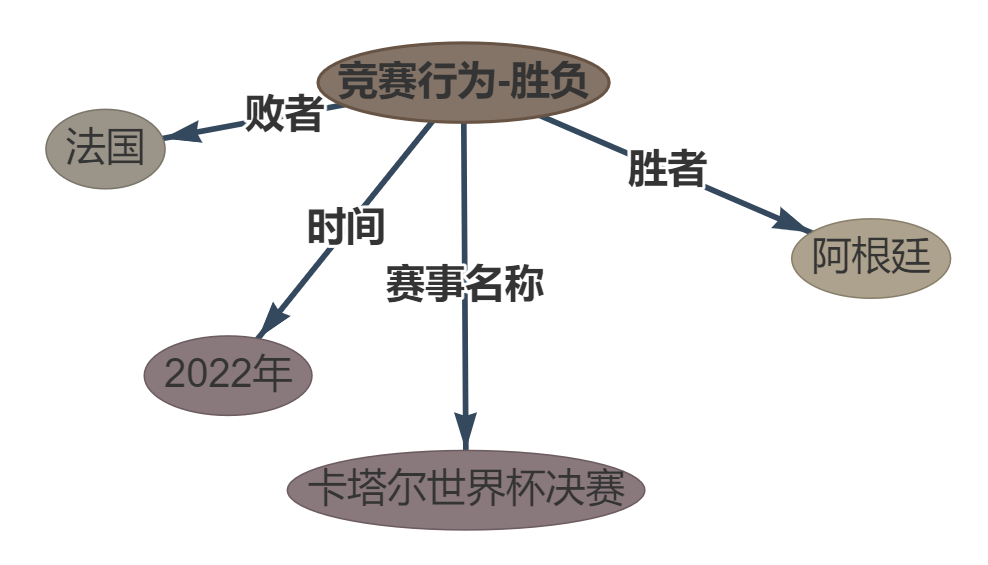
reagieren+Flask
front-end und Führen Sie npm install aus, um die erforderlichen Abhängigkeiten herunterzuladen.npm run start . Chatie sollte sich in einem neuen Browser -Registerkarte öffnen.back-end und Run python run.py
Wir sind bestrebt, unser Projekt zu verbessern und Ihnen die bestmögliche Erfahrung zu bieten. Um dies zu erreichen, sammeln wir Ihre Daten, um zu verstehen, wie Sie mit unserem Projekt interagieren und Verbesserungsbereiche identifizieren. Wir schätzen die Privatsphäre und Sicherheit Ihrer Daten und stellen die Daten nur sicher, um unser Projekt zu verbessern.
Kasse dieses Papiers Arxiv: 2302.10205
@article{wei2023zero,
title={Zero-Shot Information Extraction via Chatting with ChatGPT},
author={Wei, Xiang and Cui, Xingyu and Cheng, Ning and Wang, Xiaobin and Zhang, Xin and Huang, Shen and Xie, Pengjun and Xu, Jinan and Chen, Yufeng and Zhang, Meishan and others},
journal={arXiv preprint arXiv:2302.10205},
year={2023}
}


