IncarnaMind
1.0.0
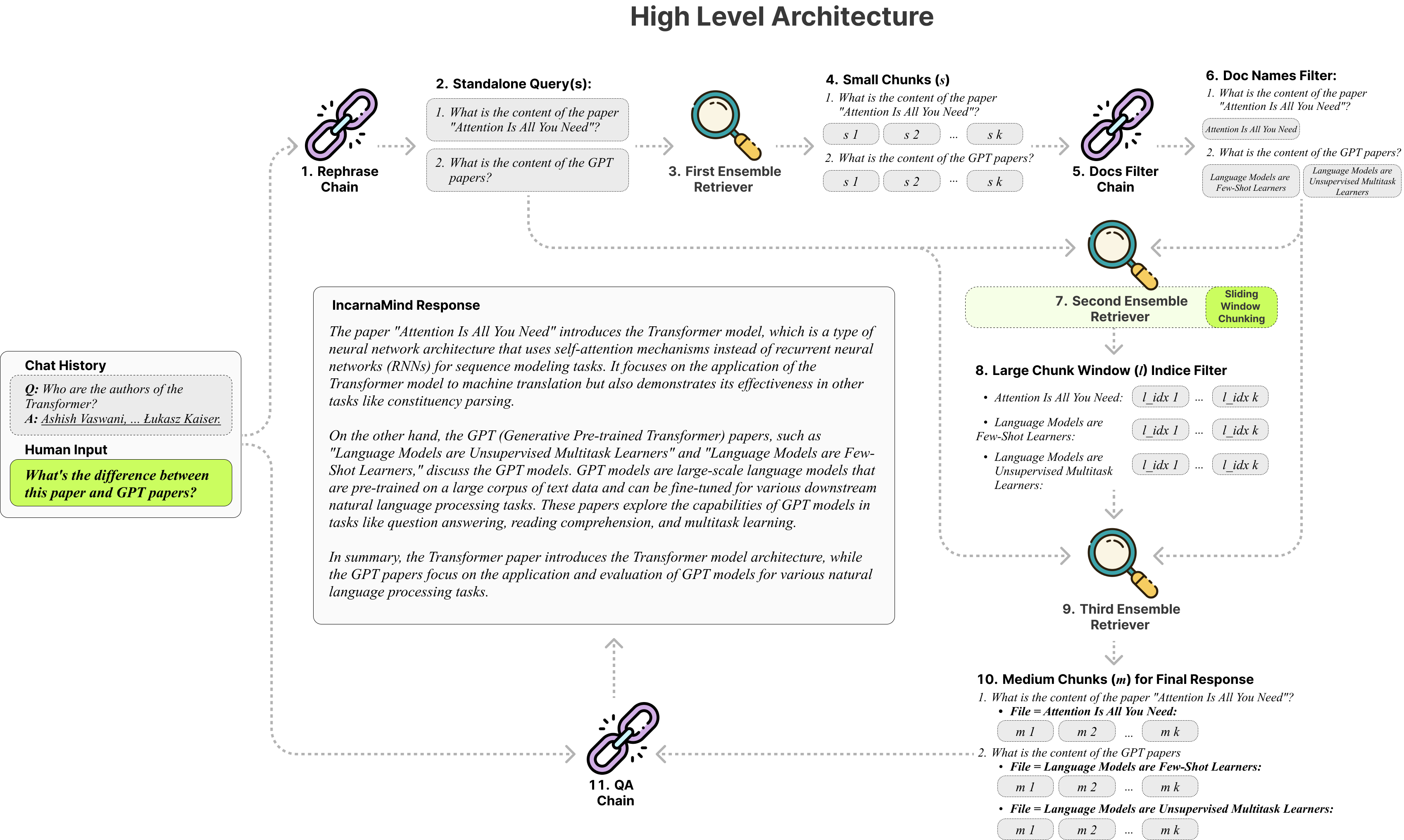
Mit Incarnamind können Sie mit Ihren persönlichen Dokumenten chatten? (PDF, TXT) Verwenden großer Sprachmodelle (LLMs) wie GPT (Architekturübersicht). Während OpenAI kürzlich eine feine API für GPT-Modelle auf den Markt gebracht hat, ermöglicht dies nicht, dass die vorgelegten Basismodelle neue Daten erlernen, und die Antworten können zu sachlichen Halluzinationen anfällig sein. Verwenden Sie unseren Mechanismus für Schiebfenster, und Ensemble Retriever ermöglicht eine effiziente Abfrage sowohl feinkörniger als auch grobkörniger Informationen in Ihren Grundwahrheitsdokumenten, um die LLMs zu erweitern.
Fühlen Sie sich frei, es zu verwenden, und wir freuen uns über Feedback- und neue Feature -Vorschläge.
Hier ist eine Vergleichstabelle der verschiedenen Modelle, die ich getestet habe, nur als Referenz:
| Metriken | GPT-4 | GPT-3.5 | Claude 2.0 | LAMA2-70B | LAMA2-70B-GUF | LAMA2-70B-API |
|---|---|---|---|---|---|---|
| Argumentation | Hoch | Medium | Hoch | Medium | Medium | Medium |
| Geschwindigkeit | Medium | Hoch | Medium | Sehr niedrig | Niedrig | Medium |
| GPU RAM | N / A | N / A | N / A | Sehr hoch | Hoch | N / A |
| Sicherheit | Niedrig | Niedrig | Niedrig | Hoch | Hoch | Niedrig |
Festes Chunking : Herkömmliche Lag -Tools stützen sich auf feste Stückgrößen und begrenzen deren Anpassungsfähigkeit bei der Umstellung der unterschiedlichen Datenkomplexität und des unterschiedlichen Kontextes.
Präzision vs. Semantik : Aktuelle Abrufmethoden konzentrieren sich normalerweise entweder auf das semantische Verständnis oder das genaue Abruf, aber selten beides.
Einbeschränkung der Einzeldokument : Viele Lösungen können jeweils nur ein Dokument abfragen, wodurch das Abrufen von Informationen zum Multi-Dokument einschränken.
Stabilität : Inkarnamind ist mit OpenAI GPT, Anthropic Claude, LLAMA2 und anderen Open-Source-LLMs kompatibel, um eine stabile Parsen zu gewährleisten.
Adaptives Chunking : Unsere Schiebungsfenster-Chunking-Technik passt die Fenstergröße und -position dynamisch für Lappen an und balancieren feinkörniger und grobkörniger Datenzugriff basierend auf Datenkomplexität und Kontext.
Multi-Dokument-Konversations-QA : Unterstützt einfache und Multi-Hop-Abfragen in mehreren Dokumenten gleichzeitig, wodurch die Einschränkung des Einzeldokuments verstößt.
Dateikompatibilität : Unterstützt sowohl PDF- als auch TXT -Dateiformate.
LLM-Modellkompatibilität : Unterstützt OpenAI GPT, Anthropic Claude, LLAMA2 und andere Open-Source-LLMs.

Die Installation ist einfach, Sie müssen nur wenige Befehle ausführen.
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMindErstellen Sie die virtuelle Konda -Umgebung:
conda create -n IncarnaMind python=3.10Aktivieren:
conda activate IncarnaMindAlle Anforderungen installieren:
pip install -r requirements.txtInstallieren Sie LLAMA-CPP separat, wenn Sie quantisierte lokale LLMs ausführen möchten:
NVIDIA -GPUS -Unterstützung cuBLAS CMAKE_ARGS= " -DLLAMA_CUBLAS=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirM1/M2 ) CMAKE_ARGS= " -DLLAMA_METAL=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirRichten Sie Ihre One/Alle -API -Schlüssel in configParser.ini -Datei ein:
[tokens]
OPENAI_API_KEY = (replace_me)
ANTHROPIC_API_KEY = (replace_me)
TOGETHER_API_KEY = (replace_me)
# if you use full Meta-Llama models, you may need Huggingface token to access.
HUGGINGFACE_TOKEN = (replace_me)(Optional) Richten Sie Ihre benutzerdefinierten Parameter in configParser.ini -Datei ein:
[parameters]
PARAMETERS 1 = (replace_me)
PARAMETERS 2 = (replace_me)
...
PARAMETERS n = (replace_me)Fügen Sie alle Ihre Dateien (Bitte benennen Sie jede Datei korrekt, um die Leistung zu maximieren) in das Verzeichnis /Daten und führen Sie den folgenden Befehl aus, um alle Daten aufzunehmen: (Sie können Beispieldateien im /Datenverzeichnis löschen, bevor Sie den Befehl ausführen).
python docs2db.pyUm das Gespräch zu starten, führen Sie einen Befehl aus wie:
python main.pyWarten Sie, bis das Skript Ihre Eingabe wie das unten erfordert.
Human:Wenn Sie einen Chat starten, generiert das System automatisch eine Incarnamind.log -Datei. Wenn Sie die Protokollierung bearbeiten möchten, bearbeiten Sie bitte in der Datei configParser.ini .
[logging]
enabled = True
level = INFO
filename = IncarnaMind.log
format = %(asctime)s [%(levelname)s] %(name)s: %(message)sBesonderer Dank geht an Langchain, Chroma DB, Localgpt, Lama-CPP für ihre unschätzbaren Beiträge zur Open-Source-Community. Ihre Arbeit war maßgeblich daran beteiligt, das Inkarnamind -Projekt Wirklichkeit werden zu lassen.
Wenn Sie unsere Arbeit zitieren möchten, verwenden Sie bitte den folgenden Bibtex -Eintrag:
@misc { IncarnaMind2023 ,
author = { Junru Xiong } ,
title = { IncarnaMind } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub Repository } ,
howpublished = { url{https://github.com/junruxiong/IncarnaMind} }
}Apache 2.0 Lizenz


