pytorch openai transformer lm
1.0.0
Dies ist eine Pytorch-Implementierung des Tensorflow-Code, das mit OpenAIs Papier "Verbesserung des Sprachverständnisses durch generative Vorversorgung" von Alec Radford, Karthik Narasimhan, Tim Salimans und Ilya Sutskever bereitgestellt wird.
Diese Implementierung umfasst ein Skript, um das Pytorch-Modell zu laden .
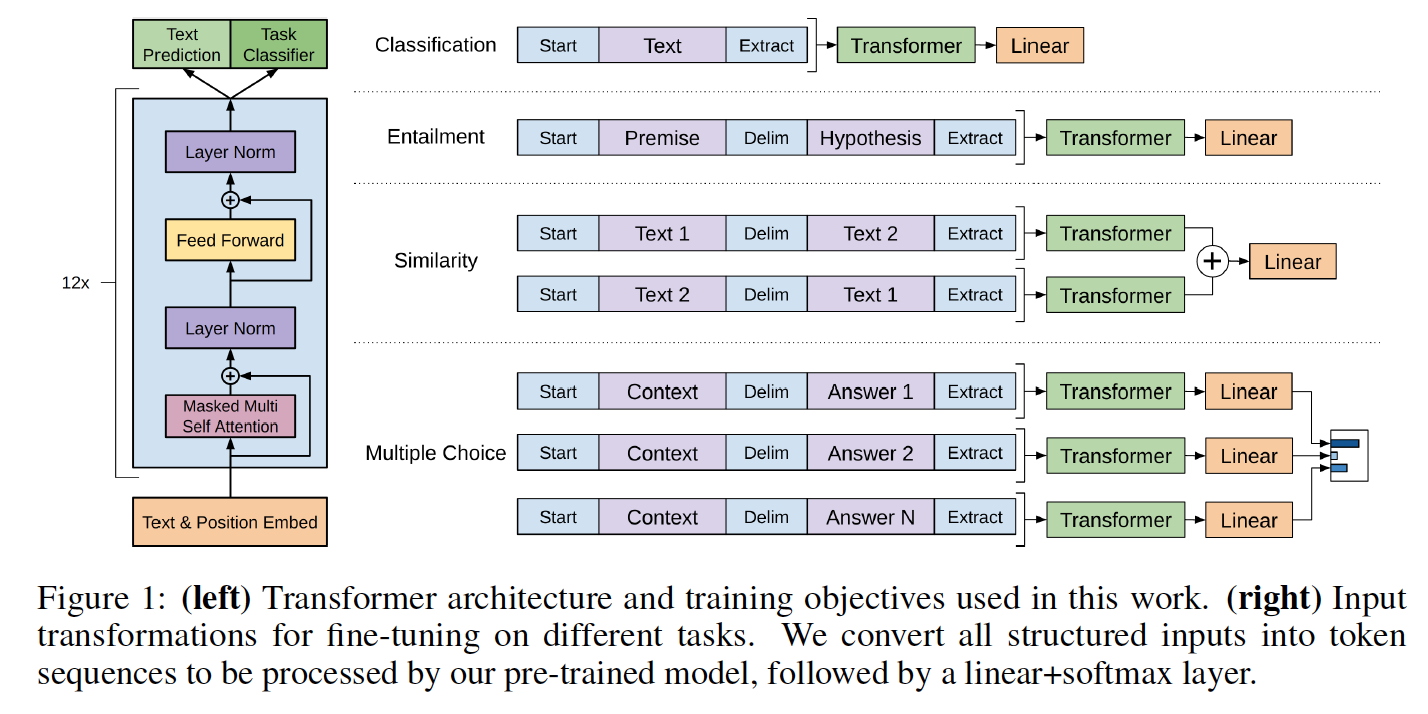
Die Modellklassen und das Ladeskript befinden sich in model_pytorch.py.
Die Namen der Module im Pytorch -Modell folgen den Namen der Variablen in der Tensorflow -Implementierung. Diese Implementierung versucht, den ursprünglichen Code so genau wie möglich zu befolgen, um die Diskrepanzen zu minimieren.
Diese Implementierung umfasst somit auch einen modifizierten ADAM -Optimierungsalgorithmus, der in OpenA -Papier verwendet wird, mit:
Um das Modell selbst zu verwenden, indem Sie model_pytorch.py importieren, brauchen Sie nur:
Um das Klassifikator -Trainingskript in Train.py auszuführen, benötigen Sie zusätzlich:
Sie können die Gewichte der OpenAI-vor-ausgebildeten Version herunterladen, indem Sie Alec Radfords Repo klonieren und den model mit den vorgebauten Gewichten im vorliegenden Repo platzieren.
Das Modell kann als Transformatorsprachmodell mit OpenAIs vorgebildeten Gewichten wie folgt verwendet werden:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) Dieses Modell generiert die versteckten Zustände des Transformators. Sie können die LMHead -Klasse in model_pytorch.py verwenden, um einen Decoder hinzuzufügen, der mit den Gewichten des Encoders verbunden ist und ein volles Sprachmodell erhalten kann. Sie können auch die ClfHead -Klasse in model_pytorch.py verwenden, um einen Klassifizierer über den Transformator hinzuzufügen und einen Klassifikator zu erhalten, wie in OpenAIs Publikation beschrieben. (Siehe ein Beispiel für beide in der __main__ -Funktion von Train.py)
Um den Positionscodierer des Transformators zu verwenden, sollten Sie Ihren Datensatz mit der Funktion encode_dataset() von utils.py codieren. Bitte beachten Sie den Beginn der Funktion __main__ in Train.py, um zu sehen, wie Sie den Wortschatz richtig definieren und Ihren Datensatz codieren.
Dieses Modell kann auch in einen Klassifizierer integriert werden, der in OpenA -Papier detailliert ist. Ein Beispiel für die Feinabstimmung in der Rokstories Cloze-Aufgabe ist im Trainingscode in Train.py enthalten
Der Rocstories -Datensatz kann von der zugehörigen Website heruntergeladen werden.
Wie beim TensorFlow -Code implementiert dieser Code das in dem Artikel angegebene Rokstories -Testergebnis, das durch Laufen reproduziert werden kann:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Das Flossen, das Pytorch-Modell für 3 Epochen auf Rocstories zu finden, dauert 10 Minuten, um auf einem einzelnen NVIDIA K-80 zu laufen.
Die Einzelanlauf -Testgenauigkeit dieser Pytorch -Version beträgt 85,84%, während die Autoren eine mediane Genauigkeit mit dem Tensorflow -Code von 85,8%berichten und das Papier eine beste Einzel -Run -Genauigkeit von 86,5%berichtet.
Die Autoren -Implementierungen verwenden 8 GPU und können somit eine Stapel von 64 Proben unterbringen, während die vorliegende Implementierung eine einzelne GPU ist und aus Speichergründen auf 20 Instanzen auf einem K80 begrenzt ist. In unserem Test erhöhte die Erhöhung der Chargengröße von 8 auf 20 Proben die Testgenauigkeit um 2,5 Punkte. Eine bessere Genauigkeit kann durch Verwendung einer Multi-GPU-Einstellung (noch nicht ausprobiert) erhalten werden.
Der vorherige SOTA im Rokstories -Datensatz beträgt 77,6% ("Hidden Cohärenzmodell" von Chaturvedi et al. In "Story -Verständnis für die Vorhersage des nächsten passiert" EMNLP 2017, was auch ein sehr schönes Papier ist!)


