instructor
1.7.0
Ausbilder ist die beliebteste Python -Bibliothek für die Arbeit mit strukturierten Ausgaben aus Großsprachenmodellen (LLMs) mit über 600.000 monatlichen Downloads. Es basiert auf Pydantic und bietet eine einfache, transparente und benutzerfreundliche API, um die Validierung, Wiederholungen und Streaming-Antworten zu verwalten. Machen Sie sich bereit, Ihre LLM -Workflows mit der besten Wahl der Community zu beenden!
Wenn Ihr Unternehmen viel Lehrer einsetzt, würden wir gerne Ihr Logo auf unserer Website haben! Bitte füllen Sie dieses Formular aus
Installieren Sie den Lehrer mit einem einzigen Befehl:
pip install -U instructorLassen Sie uns nun den Ausbilder in Aktion mit einem einfachen Beispiel sehen:
import instructor
from pydantic import BaseModel
from openai import OpenAI
# Define your desired output structure
class UserInfo ( BaseModel ):
name : str
age : int
# Patch the OpenAI client
client = instructor . from_openai ( OpenAI ())
# Extract structured data from natural language
user_info = client . chat . completions . create (
model = "gpt-4o-mini" ,
response_model = UserInfo ,
messages = [{ "role" : "user" , "content" : "John Doe is 30 years old." }],
)
print ( user_info . name )
#> John Doe
print ( user_info . age )
#> 30Ausbilder bietet ein leistungsstarkes Hakensystem, mit dem Sie verschiedene Phasen des LLM -Interaktionsprozesses abfangen und protokollieren können. Hier ist ein einfaches Beispiel, das zeigt, wie man Hooks verwendet:
import instructor
from openai import OpenAI
from pydantic import BaseModel
class UserInfo ( BaseModel ):
name : str
age : int
# Initialize the OpenAI client with Instructor
client = instructor . from_openai ( OpenAI ())
# Define hook functions
def log_kwargs ( ** kwargs ):
print ( f"Function called with kwargs: { kwargs } " )
def log_exception ( exception : Exception ):
print ( f"An exception occurred: { str ( exception ) } " )
client . on ( "completion:kwargs" , log_kwargs )
client . on ( "completion:error" , log_exception )
user_info = client . chat . completions . create (
model = "gpt-4o-mini" ,
response_model = UserInfo ,
messages = [
{ "role" : "user" , "content" : "Extract the user name: 'John is 20 years old'" }
],
)
"""
{
'args': (),
'kwargs': {
'messages': [
{
'role': 'user',
'content': "Extract the user name: 'John is 20 years old'",
}
],
'model': 'gpt-4o-mini',
'tools': [
{
'type': 'function',
'function': {
'name': 'UserInfo',
'description': 'Correctly extracted `UserInfo` with all the required parameters with correct types',
'parameters': {
'properties': {
'name': {'title': 'Name', 'type': 'string'},
'age': {'title': 'Age', 'type': 'integer'},
},
'required': ['age', 'name'],
'type': 'object',
},
},
}
],
'tool_choice': {'type': 'function', 'function': {'name': 'UserInfo'}},
},
}
"""
print ( f"Name: { user_info . name } , Age: { user_info . age } " )
#> Name: John, Age: 20Dieses Beispiel zeigt:
Die Hooks bieten wertvolle Einblicke in die Eingaben der Funktion und alle Fehler, wodurch Debugging- und Überwachungsfunktionen verbessert werden.
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_anthropic ( Anthropic ())
# note that client.chat.completions.create will also work
resp = client . messages . create (
model = "claude-3-opus-20240229" ,
max_tokens = 1024 ,
system = "You are a world class AI that excels at extracting user data from a sentence" ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 Stellen Sie sicher, dass Sie cohere installieren und Ihre Systemumgebungsvariable mit export CO_API_KEY=<YOUR_COHERE_API_KEY> einstellen.
pip install cohere
import instructor
import cohere
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_cohere ( cohere . Client ())
# note that client.chat.completions.create will also work
resp = client . chat . completions . create (
model = "command-r-plus" ,
max_tokens = 1024 ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 Stellen Sie sicher, dass Sie den Google AI Python SDK installieren. Mit Ihrem API -Schlüssel sollten Sie eine Umgebungsvariable GOOGLE_API_KEY festlegen. Durch Gemini Tool Calling muss auch jsonref installiert werden.
pip install google-generativeai jsonref
import instructor
import google . generativeai as genai
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
# genai.configure(api_key=os.environ["API_KEY"]) # alternative API key configuration
client = instructor . from_gemini (
client = genai . GenerativeModel (
model_name = "models/gemini-1.5-flash-latest" , # model defaults to "gemini-pro"
),
mode = instructor . Mode . GEMINI_JSON ,
) Alternativ können Sie Gemini vom OpenAI -Kunden anrufen. Sie müssen gcloud einrichten, ein Setup auf Vertex AI erhalten und die Google Auth -Bibliothek installieren.
pip install google-auth import google . auth
import google . auth . transport . requests
import instructor
from openai import OpenAI
from pydantic import BaseModel
creds , project = google . auth . default ()
auth_req = google . auth . transport . requests . Request ()
creds . refresh ( auth_req )
# Pass the Vertex endpoint and authentication to the OpenAI SDK
PROJECT = 'PROJECT_ID'
LOCATION = (
'LOCATION' # https://cloud.google.com/vertex-ai/generative-ai/docs/learn/locations
)
base_url = f'https:// { LOCATION } -aiplatform.googleapis.com/v1beta1/projects/ { PROJECT } /locations/ { LOCATION } /endpoints/openapi'
client = instructor . from_openai (
OpenAI ( base_url = base_url , api_key = creds . token ), mode = instructor . Mode . JSON
)
# JSON mode is req'd
class User ( BaseModel ):
name : str
age : int
resp = client . chat . completions . create (
model = "google/gemini-1.5-flash-001" ,
max_tokens = 1024 ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 import instructor
from litellm import completion
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_litellm ( completion )
resp = client . chat . completions . create (
model = "claude-3-opus-20240229" ,
max_tokens = 1024 ,
messages = [
{
"role" : "user" ,
"content" : "Extract Jason is 25 years old." ,
}
],
response_model = User ,
)
assert isinstance ( resp , User )
assert resp . name == "Jason"
assert resp . age == 25 Dies war der Traum des Ausbilders, aber aufgrund der Patching von OpenAI war es mir nicht möglich, dass ich gut funktioniert. Jetzt können wir mit dem neuen Kunden gut arbeiten lassen! Wir haben auch einige Methoden create_* hinzugefügt, um es einfacher zu machen, ITerables und Teilnehmer zu erstellen und auf die ursprüngliche Fertigstellung zuzugreifen.
create import openai
import instructor
from pydantic import BaseModel
class User ( BaseModel ):
name : str
age : int
client = instructor . from_openai ( openai . OpenAI ())
user = client . chat . completions . create (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
)Wenn Sie nun eine IDE verwenden, können Sie sehen, dass der Typ korrekt abgeleitet ist.
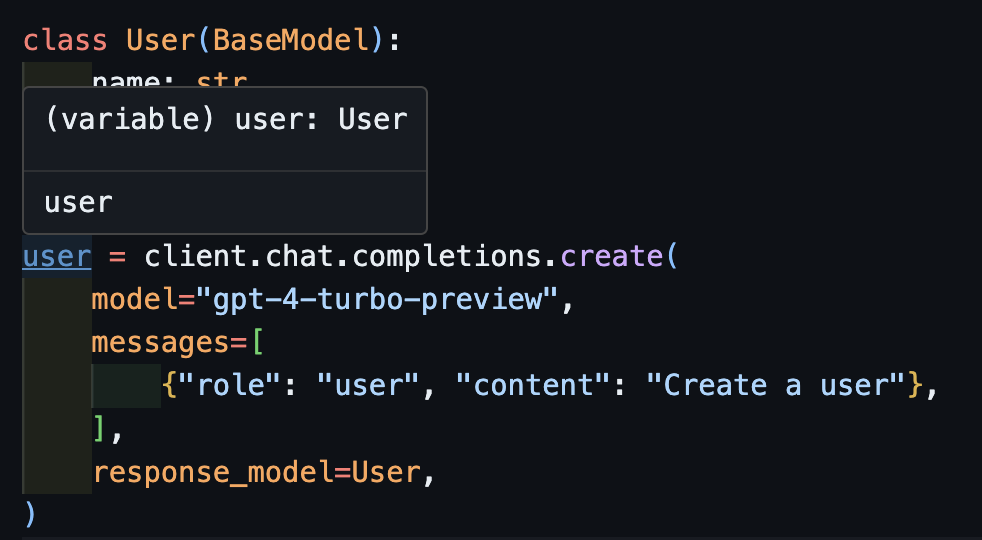
await createDies funktioniert auch korrekt mit asynchronen Kunden.
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . AsyncOpenAI ())
class User ( BaseModel ):
name : str
age : int
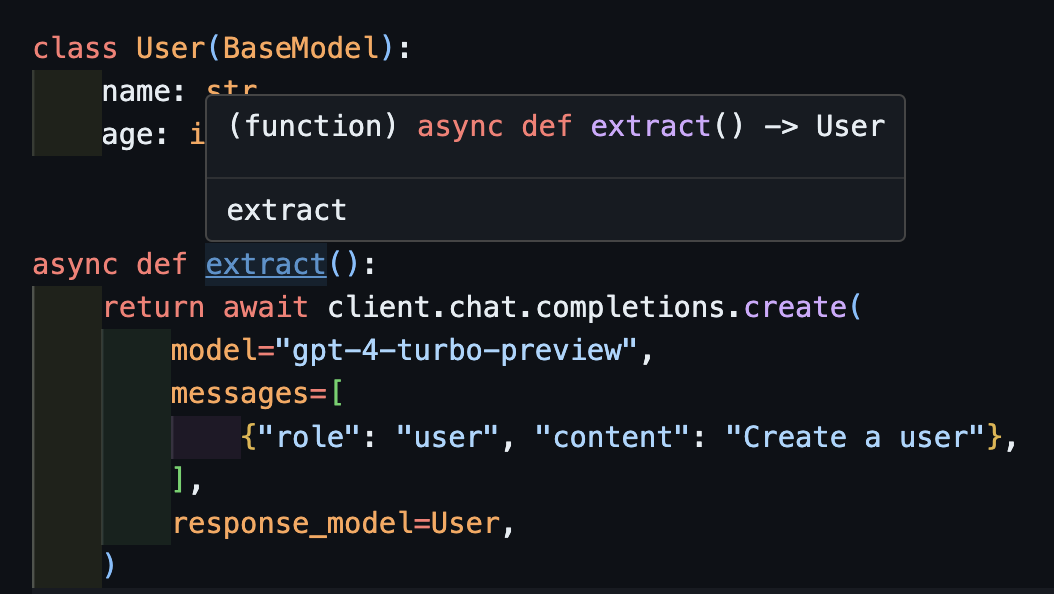
async def extract ():
return await client . chat . completions . create (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
) Beachten Sie, dass die Funktion extract() nur, weil wir die Methode create , die richtige Benutzertyp zurückgeben.
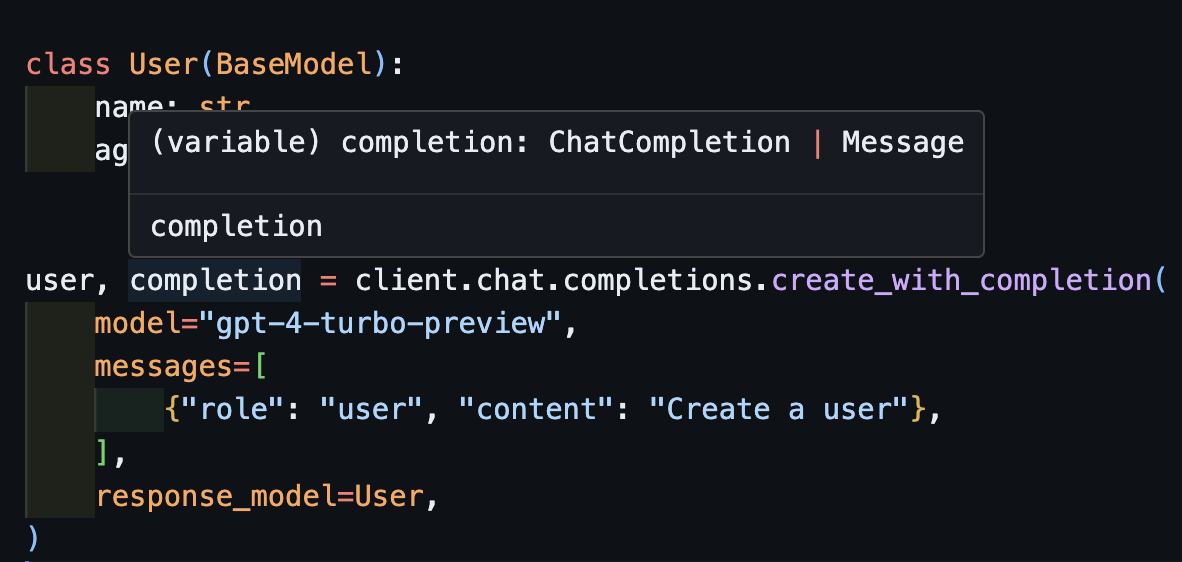
create_with_completionSie können auch das ursprüngliche Abschlussobjekt zurückgeben
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . OpenAI ())
class User ( BaseModel ):
name : str
age : int
user , completion = client . chat . completions . create_with_completion (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
)
create_partial Um Streams zu verarbeiten, unterstützen wir weiterhin Iterable[T] und Partial[T] Um jedoch die Inferenz zu vereinfachen, haben wir auch create_iterable und create_partial -Methoden hinzugefügt!
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . OpenAI ())
class User ( BaseModel ):
name : str
age : int
user_stream = client . chat . completions . create_partial (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create a user" },
],
response_model = User ,
)
for user in user_stream :
print ( user )
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name=None age=None
#> name='John Doe' age=None
#> name='John Doe' age=None
#> name='John Doe' age=None
#> name='John Doe' age=30
#> name='John Doe' age=30
# name=None age=None
# name='' age=None
# name='John' age=None
# name='John Doe' age=None
# name='John Doe' age=30 Beachten Sie jetzt, dass der abgeleitete Typ Generator[User, None] ist
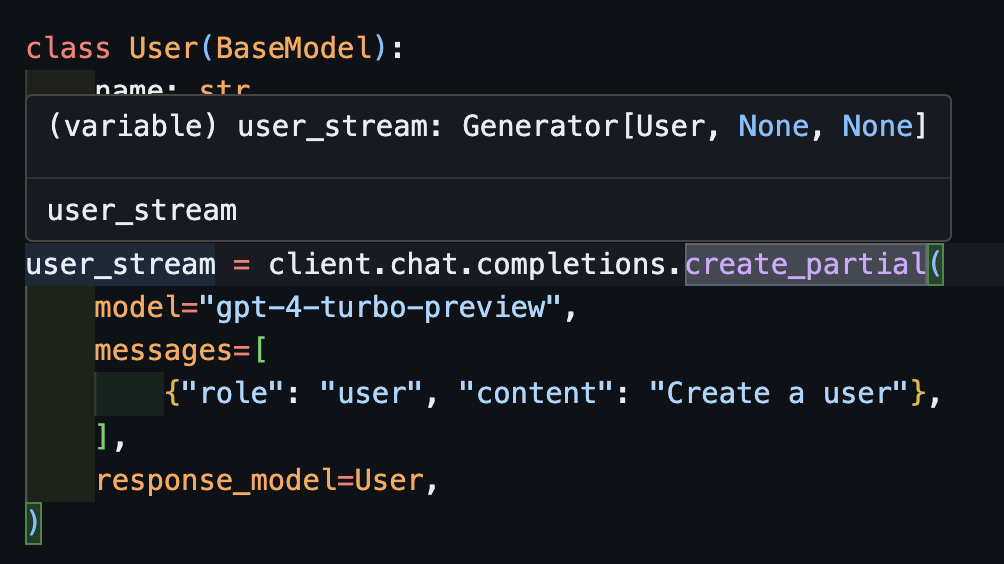
create_iterableWir erhalten Objekte, wenn wir mehrere Objekte extrahieren möchten.
import openai
import instructor
from pydantic import BaseModel
client = instructor . from_openai ( openai . OpenAI ())
class User ( BaseModel ):
name : str
age : int
users = client . chat . completions . create_iterable (
model = "gpt-4-turbo-preview" ,
messages = [
{ "role" : "user" , "content" : "Create 2 users" },
],
response_model = User ,
)
for user in users :
print ( user )
#> name='John Doe' age=30
#> name='Jane Doe' age=28
# User(name='John Doe', age=30)
# User(name='Jane Smith', age=25) 
Wir laden Sie ein, zu Evals in pytest beizutragen, um die Qualität der OpenAI -Modelle und der instructor zu überwachen. Schauen Sie sich die Evals für anthropisch und openai an und tragen Sie Ihre eigenen Evals in Form von PyTest -Tests bei. Diese Evals werden einmal pro Woche ausgeführt und die Ergebnisse werden veröffentlicht.
Wenn Sie helfen möchten, überprüfen Sie einige der Probleme, die als good-first-issue als help-wanted . Sie könnten alles von Codeverbesserungen, einem Gast -Blog -Beitrag oder einem neuen Kochbuch sein.
Wir bieten auch einige zusätzliche CLI -Funktionen für einfache Komfort:
instructor jobs : Dies hilft bei der Schaffung Feinabstimmungsjobs mit OpenAI. Einfache instructor jobs create-from-file --help um mit dem Erstellen Ihres ersten fein abgestimmten GPT-3.5-Modells zu beginnen
instructor files : Verwalten Sie Ihre hochgeladenen Dateien mühelos. Sie können Dateien alle aus der Befehlszeile erstellen, löschen und hochladen
instructor usage : Anstatt jedes Mal auf die OpenAI -Website zu fahren, können Sie Ihre Nutzung über die CLI und den Filter nach Datum und Zeitraum überwachen. Beachten Sie, dass die Verwendung von OpenAi häufig ~ 5-10 Minuten dauert, um von Openai zu aktualisieren
Dieses Projekt ist gemäß den Bedingungen der MIT -Lizenz lizenziert.


