dalle flow
1.0.0


Ein Mensch in der Schleife ? Workflow zum Erstellen von HD -Bildern aus Text
Dall · E Flow ist ein interaktiver Workflow zur Erzeugung hochauflösender Bilder aus der Textaufforderung. Zuerst nutzt es Dall · E-Mega, Glid-3 XL und stabile Diffusion, um Bildkandidaten zu erzeugen, und nennt dann Clip-as-Service, um die Kandidaten der Eingabeaufforderung zu bewerten. Der bevorzugte Kandidat wird für die Diffusion mit Glid-3 XL zugeführt, die häufig die Textur und den Hintergrund anreichert. Schließlich ist der Kandidat über Swinir auf 1024 x 1024 hochgeführt.
Dall · E Flow wird mit Jina in einer Client-Server-Architektur gebaut, die ihm eine hohe Skalierbarkeit, nicht blockierende Streaming und eine moderne pythonische Schnittstelle verleiht. Der Client kann über GRPC/WebSocket/HTTP mit TLS mit dem Server interagieren.
Warum Menschen in der Schleife? Generative Kunst ist ein kreativer Prozess. Während die jüngsten Fortschritte von Dall · e die Kreativität der Menschen entfesseln, sperrt ein einzelner prompt-single-output-UX/UI die Vorstellungskraft einer einzigen Möglichkeit, was schlecht ist, egal wie gut dieses einzelne Ergebnis ist. Dall · E Flow ist eine Alternative zum Einzeiler, indem die generative Kunst als iteratives Verfahren formalisiert wird.
Dall · E Flow befindet sich in der Client-Server-Architektur.
grpcs://api.clip.jina.ai:2096 (erfordert jina >= v3.11.0 ) müssen Sie zuerst einen Zugangstoken von hier erhalten. Weitere Informationen finden Sie unter Verwendung des Clip-as-Service.flow_parser.py aktivieren.grpcs://dalle-flow.dev.jina.ai . Alle Verbindungen sind jetzt mit TLS -Verschlüsselung. Bitte eröffnen Sie das Notebook in Google Colab.p2.x8large -Instanz.ViT-L/14@336px von Clip-as-Service, steps 100->200 .















































Die Verwendung von Client ist super einfach. Die folgenden Schritte werden am besten in Jupyter Notebook oder Google Colab ausgeführt.
Sie müssen zuerst Docarray und Jina installieren:
pip install " docarray[common]>=0.13.5 " jinaWir haben einen Demo -Server für Sie zum Spielen zur Verfügung gestellt:
Euen Aufgrund der massiven Anforderungen kann unser Server eine Verzögerung bei der Reaktion sein. Dennoch sind wir sehr zuversichtlich, dass wir die Verfügbarkeit hoch halten. Sie können auch Ihren eigenen Server bereitstellen, indem Sie hier der Anweisung folgen.
server_url = 'grpcs://dalle-flow.dev.jina.ai'Definieren wir nun die Eingabeaufforderung:
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'Lassen Sie es uns an den Server senden und die Ergebnisse visualisieren:
from docarray import Document
doc = Document ( text = prompt ). post ( server_url , parameters = { 'num_images' : 8 })
da = doc . matches
da . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Hier erzeugen wir 24 Kandidaten, 8 von Dalle-Mega, 8 aus Glid3 XL und 8 aus stabiler Diffusion. Dies ist wie in num_images definiert, was ungefähr ~ 2 Minuten dauert. Sie können einen kleineren Wert verwenden, wenn es für Sie zu lang ist.

Die 24 Kandidaten werden nach Clip-as-Service sortiert, wobei der 0 der beste Kandidat mit Clip gemessen wird. Natürlich können Sie anders denken. Beachten Sie die Nummer in der oberen linken Ecke? Wählen Sie die aus, die Ihnen am meisten gefällt, und erhalten Sie eine bessere Ansicht:
fav_id = 3
fav = da [ fav_id ]
fav . embedding = doc . embedding
fav . display ()
Lassen Sie uns nun die ausgewählten Kandidaten zur Diffusion an den Server senden.
diffused = fav . post ( f' { server_url } ' , parameters = { 'skip_rate' : 0.5 , 'num_images' : 36 }, target_executor = 'diffusion' ). matches
diffused . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Dadurch werden 36 Bilder basierend auf dem ausgewählten Bild basieren. Sie können dem Modell zulassen, dass das Modell mehr improvisiert, indem Sie skip_rate einen Wert nahezu null oder einen nahezu einen Wert geben, um seine Nähe zum angegebenen Bild zu erzwingen. Das gesamte Verfahren dauert ungefähr ~ 2 Minuten.

Wählen Sie das Bild aus, das Ihnen am meisten gefällt, und sehen Sie es genauer an:
dfav_id = 34
fav = diffused [ dfav_id ]
fav . display ()
Senden Sie schließlich für den letzten Schritt an den Server: Upscaling auf 1024 x 1024px.
fav = fav . post ( f' { server_url } /upscale' )
fav . display ()Das war's! Es ist derjenige . Wenn nicht zufrieden, wiederholen Sie die Prozedur.

Übrigens ist Docarray eine leistungsstarke und benutzerfreundliche Datenstruktur für unstrukturierte Daten. Es ist super produktiv für Datenwissenschaftler, die in Kreuz-/multimodaler Domäne arbeiten. Um mehr über Docarray zu erfahren, lesen Sie bitte die Dokumente.
Sie können Ihren eigenen Server hosten, indem Sie die folgende Anweisung folgen.
Dall · E Flow braucht eine GPU mit 21 GB VRAM am Peak. Alle Dienste werden in diese eine GPU unterdrückt, darunter (ungefähr)
config.yml , 512x512)Die folgenden angemessenen Tricks können zur weiteren Reduzierung von VRAM verwendet werden:
Auf der Festplatte benötigt es mindestens 50 GB freien Speicherplatz, hauptsächlich zum Herunterladen von vorbereiteten Modellen.
Hochgeschwindigkeits-Internet ist erforderlich. Langsames/instabiles Internet kann beim Herunterladen von Modellen frustrierendes Timeout werfen.
CPU-Umgebung wird nicht getestet und wird wahrscheinlich nicht funktionieren. Google Colab wirft wahrscheinlich auch nicht funktionieren.

Wenn Sie Jina installiert haben, kann das obige Flussdiagramm über:
# pip install jina
jina export flowchart flow.yml flow.svgWenn Sie eine stabile Diffusion verwenden möchten, müssen Sie zunächst ein Konto auf der Website -Umarmung registrieren und den Geschäftsbedingungen für das Modell zustimmen. Nach dem Anmeldung finden Sie die Version des Modells, das hier erforderlich ist:
Compvis / SD-V1-5-Einbindungen.ckpt
Klicken Sie unter dem Abschnitt Gewichte auf den Link für sd-v1-x.ckpt . Die neuesten Gewichte zum Zeitpunkt des Schreibens sind sd-v1-5.ckpt .
Docker-Benutzer : Geben Sie diese Datei in einen Ordner mit dem Namen ldm/stable-diffusion-v1 ein und benennen Sie es um model.ckpt um. Befolgen Sie die folgenden Anweisungen sorgfältig, da SD standardmäßig nicht aktiviert ist.
Native Benutzer : Fügen Sie diese Datei in dalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt nachdem Sie den Rest der Schritte unter "nativ rennen" beendet haben. Befolgen Sie die folgenden Anweisungen sorgfältig, da SD standardmäßig nicht aktiviert ist.
Wir haben ein vorgebautes Docker -Bild bereitgestellt, das direkt gezogen werden kann.
docker pull jinaai/dalle-flow:latestWir haben eine Dockerfile bereitgestellt, mit der Sie einen Server aus der Box ausführen können.
Unsere Dockerfile verwendet CUDA 11.6 als Basisbild. Möglicherweise möchten Sie es nach Ihrem System einstellen.
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID= $( id -g ${USER} ) --build-arg USER_ID= $( id -u ${USER} ) -t jinaai/dalle-flow .Das Gebäude dauert 10 Minuten mit durchschnittlicher Internetgeschwindigkeit, was zu einem 18 -GB -Docker -Image führt.
Um es auszuführen, tun Sie einfach:
docker run -p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowAlternativ können Sie auch mit einigen aktivierten oder deaktivierten Workflows ausgeführt werden, um außerhalb des Memory-Abstürze zu verhindern. Dazu passieren Sie eine dieser Umgebungsvariablen:
DISABLE_DALLE_MEGA
DISABLE_GLID3XL
DISABLE_SWINIR
ENABLE_STABLE_DIFFUSION
ENABLE_CLIPSEG
ENABLE_REALESRGAN
Wenn Sie beispielsweise Glid3XL -Workflows deaktivieren möchten, rennen Sie:
docker run -e DISABLE_GLID3XL= ' 1 '
-p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow-v $HOME/.cache:/root/.cache vermieden wiederholtes Modell, das auf jedem Docker -Lauf heruntergeladen wird.-p 51005:51005 ist Ihr öffentlicher Host. Stellen Sie sicher, dass die Leute auf diesen Hafen zugreifen können, wenn Sie öffentlich dienen. Der zweite Par ist der in Flow.yml definierte Port.ENABLE_STABLE_DIFFUSION manuell aktiviert werden.ENABLE_CLIPSEG manuell aktiviert werden.ENABLE_REALESRGAN manuell aktiviert werden. Stabile Diffusion kann nur aktiviert werden, wenn Sie die Gewichte heruntergeladen haben und sie als virtuelles Volumen verfügbar machen, während Sie das Umgebungsflag ( ENABLE_STABLE_DIFFUSION ) für SD aktivieren .
Sie sollten die Gewichte zuvor in einen Ordner namens ldm/stable-diffusion-v1 einfügen und sie model.ckpt bezeichnen. Ersetzen YOUR_MODEL_PATH/ldm unten durch den Pfad auf Ihrem eigenen System, um die Gewichte in das Docker -Bild zu leiten.
docker run -e ENABLE_STABLE_DIFFUSION= " 1 "
-e DISABLE_DALLE_MEGA= " 1 "
-e DISABLE_GLID3XL= " 1 "
-p 51005:51005
-it
-v YOUR_MODEL_PATH/ldm:/dalle/stable-diffusion/models/ldm/
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowSie sollten den Bildschirm so sehen, wie es einmal ausgeführt wird:
Beachten Sie, dass im Gegensatz zum nativen Laufen in Docker eine weniger lebendige Fortschrittsleiste, Farbprotokolle und Drucke ergeben kann. Dies ist auf die Einschränkungen des Terminals in einem Docker -Container zurückzuführen. Es wirkt sich nicht auf die tatsächliche Verwendung aus.
Nativ, erfordert einige manuelle Schritte, aber es ist oft einfacher zu debuggen.
mkdir dalle && cd dalle
git clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/jina-ai/SwinIR.git
git clone --branch v0.0.15 https://github.com/AmericanPresidentJimmyCarter/stable-diffusion.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/jina-ai/glid-3-xl.git
git clone https://github.com/timojl/clipseg.gitSie sollten die folgende Ordnerstruktur haben:
dalle/
|
|-- Real-ESRGAN/
|-- SwinIR/
|-- clipseg/
|-- dalle-flow/
|-- glid-3-xl/
|-- latent-diffusion/
|-- stable-diffusion/
cd dalle-flow
python3 -m virtualenv env
source env/bin/activate && cd -
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install numpy tqdm pytorch_lightning einops numpy omegaconf
pip install https://github.com/crowsonkb/k-diffusion/archive/master.zip
pip install git+https://github.com/AmericanPresidentJimmyCarter/[email protected]
pip install basicsr facexlib gfpgan
pip install realesrgan
pip install https://github.com/AmericanPresidentJimmyCarter/xformers-builds/raw/master/cu116/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl &&
cd latent-diffusion && pip install -e . && cd -
cd stable-diffusion && pip install -e . && cd -
cd SwinIR && pip install -e . && cd -
cd glid-3-xl && pip install -e . && cd -
cd clipseg && pip install -e . && cd -Es gibt Paarmodelle, die wir für Glid-3-XL herunterladen müssen, wenn Sie das verwenden:
cd glid-3-xl
wget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd - Sowohl clipseg als auch RealESRGAN müssen einen korrekten Cache -Ordnerpfad festlegen, in der Regel etwas wie $ home/.
cd dalle-flow
pip install -r requirements.txt
pip install jax~=0.3.24 Jetzt stehen Sie unter dalle-flow/ Führen Sie den folgenden Befehl aus:
# Optionally disable some generative models with the following flags when
# using flow_parser.py:
# --disable-dalle-mega
# --disable-glid3xl
# --disable-swinir
# --enable-stable-diffusion
python flow_parser.py
jina flow --uses flow.tmp.ymlSie sollten diesen Bildschirm sofort sehen:

Beim ersten Start dauert es ~ 8 Minuten für das Herunterladen des Dall · Mega -Modells und anderer notwendiger Modelle. Die Verfahrensläufe sollten nur ~ 1 Minute dauern, um die Erfolgsnachricht zu erreichen.
Wenn alles fertig ist, werden Sie sehen:
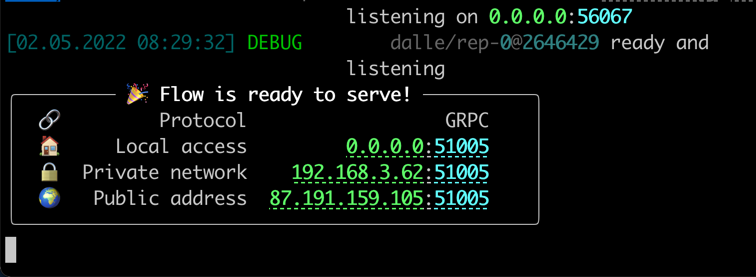
Glückwunsch! Jetzt sollten Sie den Kunden ausführen können.
Sie können den Serverfluss so ändern und erweitern, wie Sie möchten, z. B. das Modell ändern, die Persistenz hinzufügen oder sogar automatisch postieren, um Instagram/Opensea zu postieren. Mit Jina und Docarray können Sie Dall · E Flow Cloud-nativ und bereit für die Produktion machen.
Um die Verwendung von VRAM zu verringern, können Sie den CLIP-as-service als externer Testamentsvollstrecker verwenden, der frei unter grpcs://api.clip.jina.ai:2096 erhältlich ist.
Stellen Sie zunächst sicher
jina auth token create < name of PAT > -e < expiration days > Anschließend müssen Sie die verwandten Konfigurationen ( host , port , external , tls und grpc_metadata ) von flow.yml ändern.
...
- name : clip_encoder
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [gateway]
...
- name : rerank
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
uses_requests :
' / ' : rank
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [dalle, diffusion] Sie können auch den flow_parser.py verwenden, um den Fluss automatisch zu generieren und auszuführen, indem Sie den CLIP-as-service als externer Ausführungskraft verwenden:
python flow_parser.py --cas-token " <your access token>'
jina flow --uses flow.tmp.yml
Euen grpc_metadataist erst nach Jinav3.11.0erhältlich. Wenn Sie eine ältere Version verwenden, upgraden Sie bitte auf die neueste Version.
Jetzt können Sie den kostenlosen CLIP-as-service in Ihrem Fluss verwenden.
Dall · E Flow wird von Jina AI unterstützt und unter Apache-2.0 lizenziert. Wir stellen aktiv KI-Ingenieure ein, Lösungsingenieure, um das nächste Neural-Such-Ökosystem in Open-Source zu bauen.


