JARVIS ChatGPT
1.0.0
Ein sprachbasierter interaktiver Assistent, der mit einer Vielzahl von synthetischen Stimmen ausgestattet ist (einschließlich Jarvis 'Stimme von Ironman)
 Bild von Midjourney KI
Bild von Midjourney KI
Haben Sie schon einmal davon geträumt, hyper-intelligent-System-Tipps zu fragen, um Ihre Rüstung zu verbessern? Jetzt kannst du! Nun, vielleicht nicht der Rüstungsteil ... Dieses Projekt nutzt Openai Whisper, Openai Chatgpt und IBM Watson.
Projektmotivation:
Oft kommen Ideen im schlimmsten Moment und sie verblassen, bevor Sie die Zeit haben, sie besser zu erkunden. Ziel dieses Projekts ist es, ein System zu entwickeln, das in der Quasi-Real-Zeit Tipps und Meinungen über alles gibt, was Sie fragen. Der ultimative Assistent kann von jedem autorisierten Mikrofon in Ihrem Haus oder Ihrem Telefon zugegriffen werden. Er sollte ständig im Hintergrund ausgeführt werden. Wenn Sie beschworen werden, sollte es in der Lage sein, aussagekräftige Antworten (mit einer schlechten Stimme) sowie die Schnittstelle mit dem PC oder einem Server zu generieren und Dateien zu speichern/zu lesen/zu schreiben, auf die später zugegriffen werden kann. Es sollte in der Lage sein, Forschung zu betreiben, Material aus dem Internet zu sammeln (Inhalte aus HTML -Seiten extrahieren, YouTube -Videos transkribieren, wissenschaftliche Arbeiten finden ...) und Zusammenfassungen, die als Kontext verwendet werden können, um fundierte Entscheidungen zu treffen. Außerdem könnte es mit einigen externen Geräten (IoT) verkaufen, aber das ist extra.
DEMO:
Ich kann Finnaly den ersten Entwurf des Forschungsmodus teilen. Diese Modalität wurde für Menschen angenommen, die sich oft mit Forschungsarbeiten befassten.
PS: Dieser Modus ist nicht super stabil und muss bearbeitet werden
PPS: Dieses Projekt wird für einige Zeit eingestellt, da ich bis 2024 an meiner These arbeiten werde. Es gibt jedoch bereits so viele Dinge, die verbessert werden können, damit ich zurück bin!
HAFTUNGSAUSSCHLUSS:
Das Projekt könnte Ihr OpenAI -Guthaben konsumieren, was zu einer unerwünschten Abrechnung führt.
Ich übernehme keine Verantwortung für unerwünschte Anklagen.
Berücksichtigen Sie, dass Einschränkungen des Kreditverbrauchs auf Ihrem OpenAI -Konto festgelegt werden.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 );Sie können sich auf das neue
setup.batverlassen.
Hauptskript , das Sie ausführen sollten: openai_api_chatbot.py Wenn Sie die neueste Version der OpenAI -API in dem Demos -Ordner verwenden möchten, finden Sie einige Anleitungen für die im Projekt verwendeten Pakete. Wenn Sie Fehler haben, können Sie diese Dateien zuerst überprüfen, um das Problem anzusprechen. Meistens wird im Assistantordner: get_audio.py gespeichert, um alle Funktionen für die MIC -Interaktionen zu verarbeiten, tools.py implementiert einige grundlegende Aspekte des virtuellen Assistenten, voice.py beschreibt eine (sehr) grobe Sprachklasse. Agents.py GEFAHREN Sie den Langchain -Teil des Systems (hier können Sie Werkzeuge aus den Toolkits der Agenten hinzufügen oder entfernen)
Die verbleibenden Skripte sind ergänzend für die Sprachgenerierung und sollten nicht bearbeitet werden.
Sie können setup.bat ausführen, wenn Sie unter Windows/Linux ausgeführt werden. Das Skript führt jeden Schritt der manuellen Installation nacheinander aus. Beziehen Sie sich auf diejenigen, falls das Verfahren fehlschlagen sollte.
Die automatische Installation wird auch die Vicuna -Installation (Vicuna Installation Guide) ausführen
pip install -r venv_requirements.txt ; Dies könnte einige Zeit dauern; Wenn Sie Konflikte in bestimmten Paketen begegnen, installieren Sie sie manuell ohne die ==<version> ;whisper_edits finden, in den whisper Ihrer Umgebung ( venv lib Site-Packages Whisper ) . Diese Änderungen werden dem Whisper-Modell nur ein Attribut hinzufügen, um auf die Dimension leichter zuzugreifen.demos/tts_demo.py ausführen). cd Vicuna
call vicuna.ps1
env.txt -Datei ein und benennen Sie sie in .env um (ja, entfernen Sie die TXT -Erweiterung).torch.cuda.is_available() und torch.cuda.get_device_name(0) in Pyhton; .tests.py rennen.py. Diese Datei versucht, grundlegende Vorgänge auszuführen, die Fehler aufnehmen können.VirtualAssistant.__init__() ; 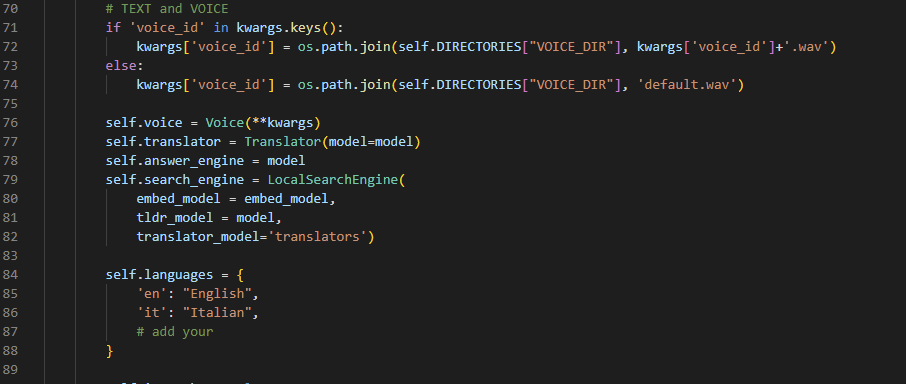
__main__() bei whisper_model = whisper.load_model("large") ein; Aber ich hoffe, Ihr GPU -Gedächtnis ist ebenfalls groß. openai_api_chatbot.py ):Beim Ausführen werden viele Informationen angezeigt. Ich bin ständig bemüht, die Lesbarkeit der Ausführung zu verbessern. Das gesamte Projekt ist eine riesige Beta, die geringfügige Abweichungen von den folgenden Bildschirmen vergeben. Wie auch immer, das passiert allgemein, wenn Sie "Run" treffen:
Jarvis sagen, um den Assistenten zu beschwören. Zu diesem Zeitpunkt beginnt ein Gespräch und Sie können in jeder gewünschten Sprache sprechen (wenn Sie Schritt 2 befolgen). Das Gespräch endet, wenn Sie 1) Sagen Sie ein Stoppwort 2) Sagen Sie etwas mit einem Wort (wie "OK") 3, wenn Sie mehr als 30 Sekunden aufhören 
chat_history mit Ihrer Frage, sendet eine Anfrage mit der API und aktualisiert die Geschichte, sobald es eine vollständige Antwort von CHATGPT erhält (dies kann bis zu 5-10 Sekunden dauern. Erwägen Sie, eine kurze Antwort ausdrücklich zu fragen, ob Sie sich eilig haben).say() führt Sprachverdoppel aus, um mit Jarvis/jemandes Stimme zu sprechen. Wenn das Argument nicht in englischer Sprache ist, sendet IBM Watson die Antwort von einem ihrer schönen Text-zu-Sprache-Modelle. Wenn alles fehlschlägt, stützen sich die Funktionen auf pyttsx3, was eine schnelle, aber nicht so coole Alternative ist.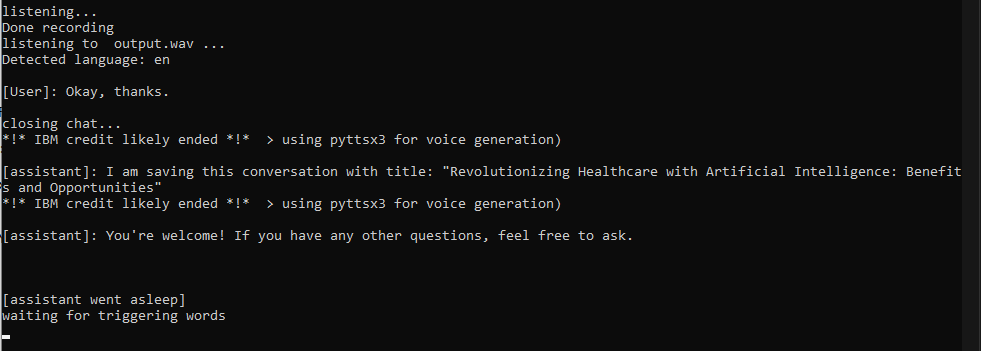
Ich machte einige Eingabeaufforderungen und schloss das Gespräch
Nicht ideal, das ich kenne, aber vorerst funktioniert
VirtualAssistant -Klasse mit Speicher und lokalem Speicherzugriff Derzeit arbeiten an:
Follow:
Weitere Einblicke finden Sie im UpdateHistory.md des Projekts.
Viel Spaß!
Kategorien: Installieren, allgemeine, Laufzeit
Das Problem ist das Flüstern. Sie sollten es manuell mit pip install whisper-openai
pip install --upgrade openai . Anforderungen werden nicht jedes Commit aktualisiert. Dies kann jedoch Fehler erzeugen, Sie können die fehlenden Module schnell installieren. Gleichzeitig hält sie die Umgebung von Konflikten sauber, wenn ich neue Pakete probiere (und ich versuche viele davon).
Dies bedeutet, dass das von Ihnen ausgewählte Modell für Ihren CUDA -Gerätespeicher zu groß ist. Leider können Sie nicht viel dagegen tun, außer ein kleineres Modell zu laden. Wenn das kleinere Modell Sie nicht befriedigt, möchten Sie möglicherweise "klarer" sprechen oder längere Aufforderungen stellen, um das Modell genauer vorhersagen zu lassen, was Sie sagen. Das klingt unpraktisch, aber in meinem Fall hat mein englischsprachiger Englisch stark verbessert :)
Dies ist ein Fehler, der noch vorhanden ist. Erwarten Sie nicht, jemals lange Gespräche mit Ihrem Assistenten zu führen, da er einfach genügend Erinnerung hat, um sich irgendwann an das gesamte Gespräch zu erinnern. Ein Fix befindet sich in der Entwicklung, es könnte darin bestehen, einen Ansatz mit Schiebern zu verfolgen, auch wenn dies zu einer Wiederholung einiger Konzepte führen könnte.
Im Moment (April 2023) arbeite ich fast ununterbrochen daran. Ich werde wahrscheinlich im Sommer eine Pause machen, weil ich an meiner These arbeiten werde.
Wenn Sie Fragen haben, können Sie mich kontaktieren, indem Sie ein Problem ansprechen, und ich werde mein Bestes tun, um so schnell wie möglich zu helfen.
Gianmarco Guarnier


