Deep RL Keras
1.0.0
Modulare Implementierung der populären Lernalgorithmen der tiefen Verstärkung in Keras:
Diese Implementierung erfordert Keras 2.1.6 sowie das Openai -Fitnessstudio.
$ pip install gym keras==2.1.6Der Schauspieler-kritische Algorithmus ist eine modellfreie, nicht-polizistische Methode, bei der der Kritiker als Wertfunktionsanbieter fungiert, und der Akteur als Richtlinienfunktionsanbieter. Beim Training prognostiziert der Kritiker den TD-Error und führt das Lernen sowohl selbst als auch des Schauspielers. In der Praxis approximieren wir den TD-Error mit der Vorteilsfunktion. Für mehr Stabilität verwenden wir ein gemeinsam genutztes Rechenkonstruktion in beiden Netzwerken sowie eine N-Schritt-Formulierung der ermäßigten Belohnungen. Wir berücksichtigen auch einen Entropie -Regularisierungsbegriff ("weiches" Lernen), um die Erkundung zu fördern. Während A2C einfach und effizient ist, wird es aufgrund der langen Berechnungszeit schnell unlösbar.
In ähnlicher Weise wie der A2C -Algorithmus enthält die Implementierung von A3C asynchrone Gewichtsaktualisierungen, die eine viel schnellere Berechnung ermöglichen. Wir verwenden mehrere Agenten, um asynchronen Gradienten -Ascents über mehrere Threads durchzuführen. Wir testen A3C in der Atari -Breakout -Umgebung.
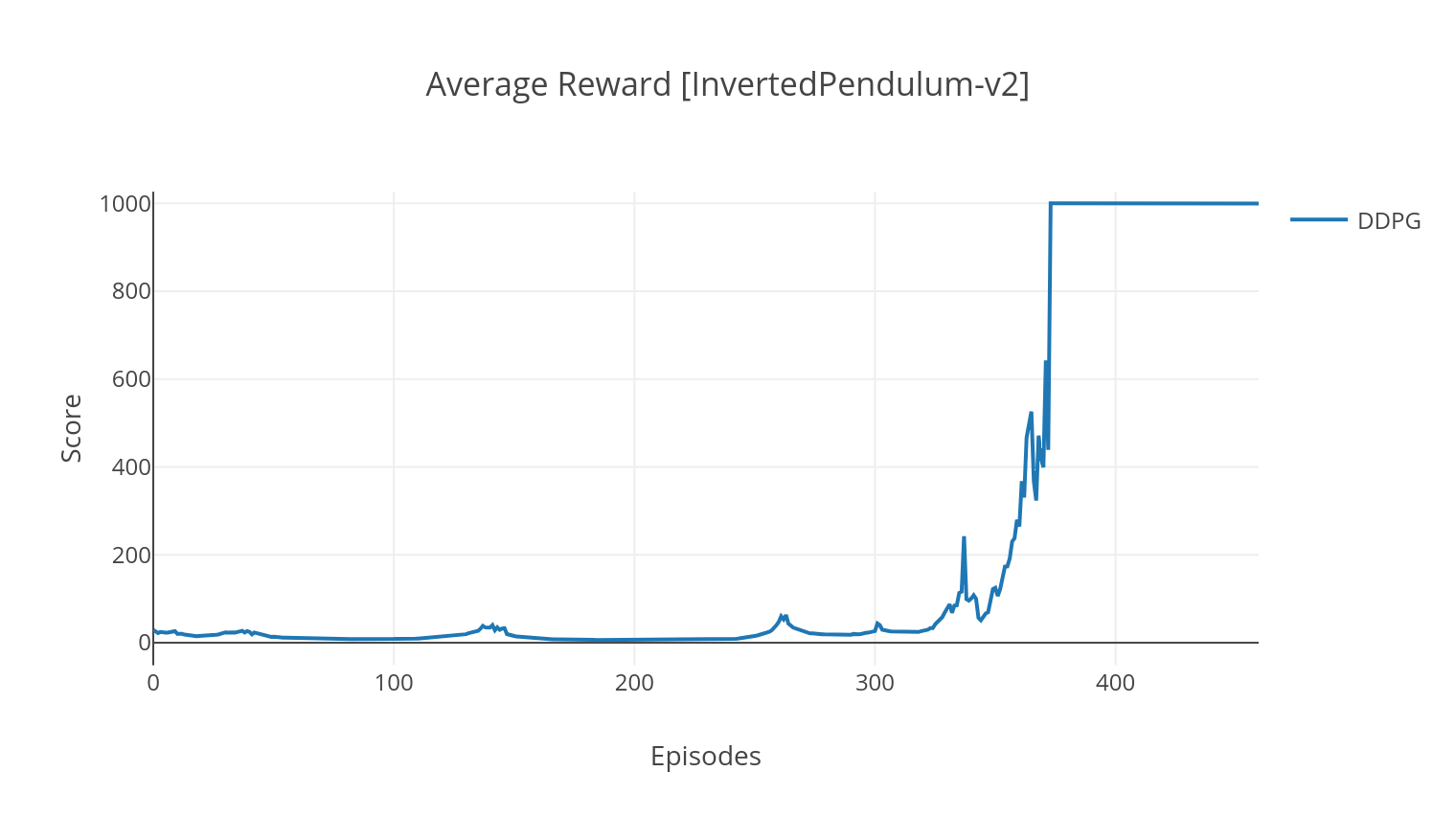
Der DDPG-Algorithmus ist ein modellfreier Off-Policy-Algorithmus für kontinuierliche Aktionsräume. Ähnlich wie bei A2C ist es ein Schauspieler-kritischer Algorithmus, bei dem der Akteur auf einer deterministischen Zielpolitik geschult wird, und der Kritiker sagt Q-Werte voraus. Um die Varianz zu verringern und die Stabilität zu erhöhen, verwenden wir die Wiederholungserfahrung und separate Zielnetzwerke. Darüber hinaus fördern wir, wie von OpenAI angedeutet, die Erkundung durch Parameterraumrauschen (im Gegensatz zu herkömmlichen Rauschen des Aktionsraums). Wir testen DDPG an der Mondlander -Umgebung.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2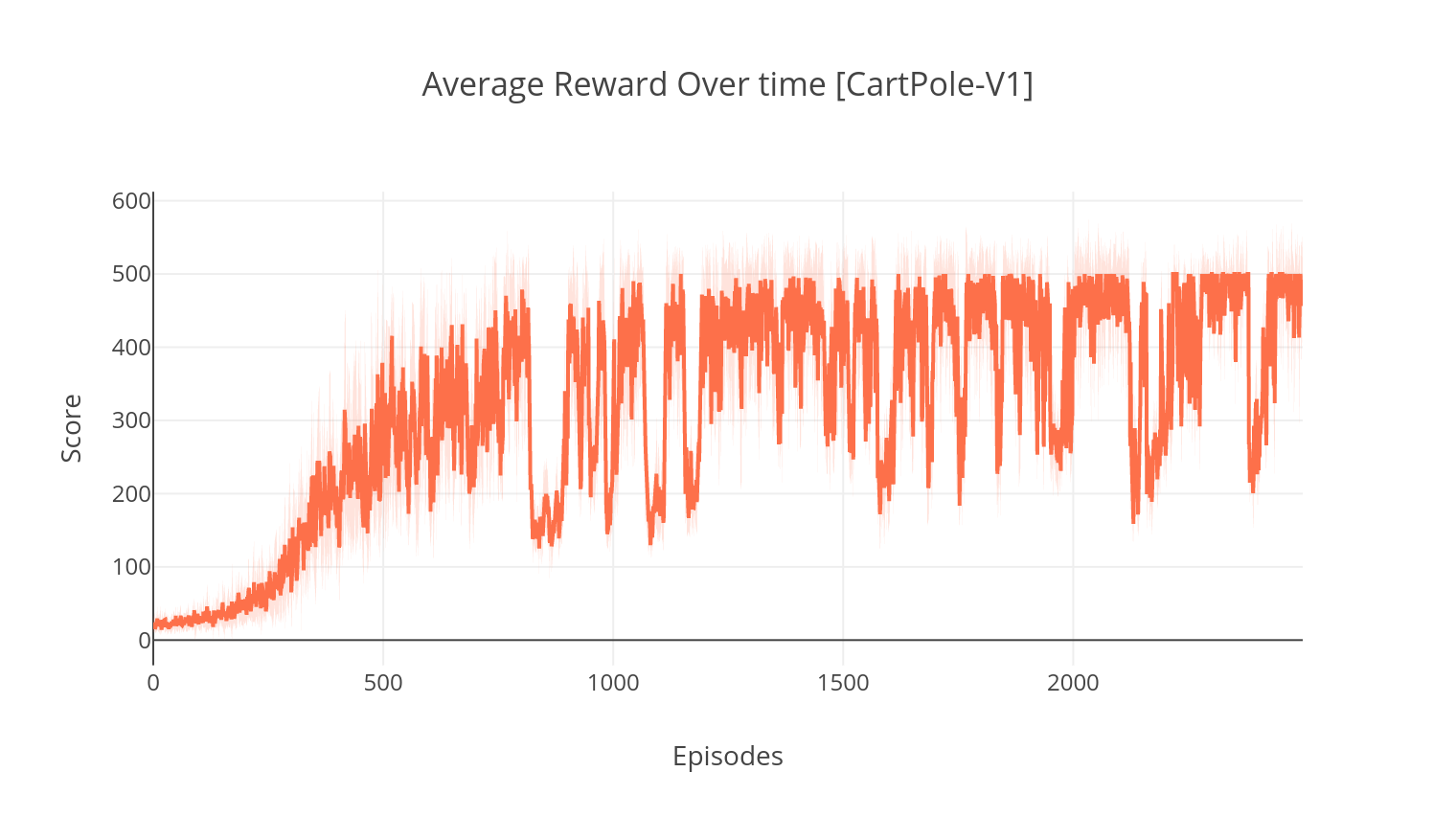
Der DQN-Algorithmus ist ein Q-Learning-Algorithmus, der ein tiefes neuronales Netzwerk als q-Wert-Funktions-Approxator verwendet. Wir schätzen die Zielwerte für Ziele, indem wir die Bellman-Gleichung nutzen, und sammeln Erfahrungen durch eine Epsilon-Greedy-Richtlinie. Für mehr Stabilität probieren wir vergangene Erfahrungen zufällig (Erfahrung Wiederholung). Eine Variante des DQN-Algorithmus ist das Doppel-DQN (oder DDQN). Für eine genauere Schätzung unserer Q-Werte verwenden wir ein zweites Netzwerk, um die Überschätzungen der Q-Werte durch das ursprüngliche Netzwerk zu trennen. Dieses Zielnetz wird bei jedem Trainingsschritt langsamer TAU aktualisiert.
Wir können unseren DDQN -Algorithmus weiter verbessern, indem wir priorisierte Erfahrungen Replay (Per) hinzufügen, was darauf abzielt, die gesammelte Erfahrung eine wichtige Abtastung durchzuführen. Die Erfahrung wird von seinem TD-Error eingestuft und in einer Sumtree-Struktur gespeichert, die mit dem höchsten Fehler ein effizientes Abrufen der (s, a, r, s ') Übergänge ermöglicht.
In der Duelling-Variante des DQN integrieren wir eine Zwischenschicht in das Q-Network, um sowohl den Zustandswert als auch die staatlich abhängige Vorteilsfunktion abzuschätzen. Nach der Neuformulierung (siehe Ref) stellt sich heraus, dass wir den geschätzten Q-Wert als Zustandswert ausdrücken können, zu dem wir die Vorteilsschätzung hinzufügen und seinen Mittelwert subtrahieren. Diese Faktorisierung staatlichunabhängiger und staatlich abhängiger Werte hilft, das Lernen über Handlungen hinweg zu entwirren und liefert bessere Ergebnisse.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling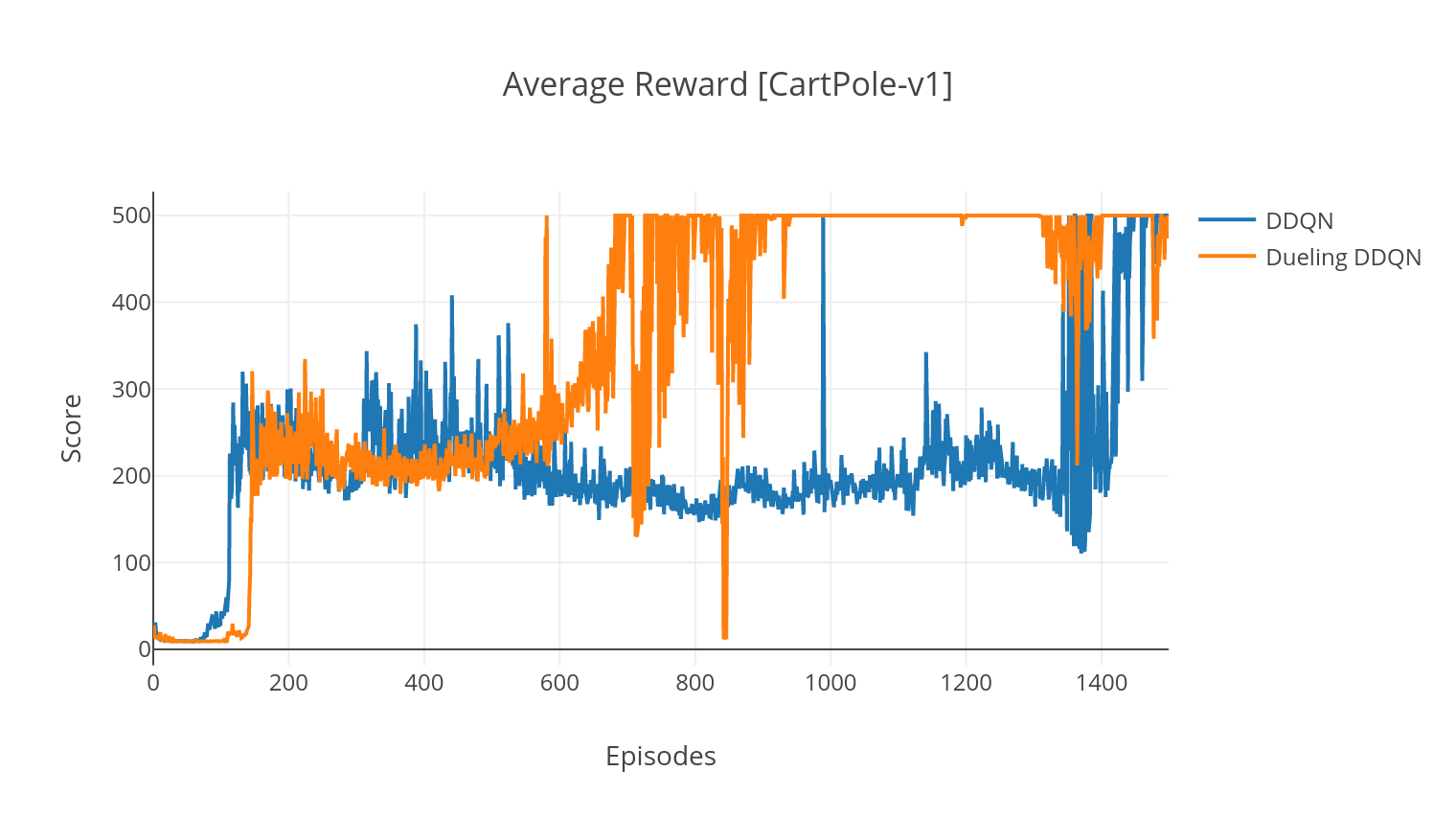
| Argument | Beschreibung | Werte |
|---|---|---|
| --Typ | Art des RL -Algorithmus zum Laufen | Wählen Sie aus {A2C, A3C, DDQN, DDPG} |
| --env | Geben Sie die Umgebung an | BreakoutnoFrameskip-V4 (Standard) |
| --nb_episodes | Anzahl der Folgen zu laufen | 5000 (Standard) |
| -batch_size | Stapelgröße (DDQN, DDPG) | 32 (Standard) |
| -konsecutive_frames | Anzahl der gestapelten aufeinanderfolgenden Rahmen | 4 (Standard) |
| -IS_ATARI | Ob die Umgebung ein Atari -Spiel mit Pixeleingabe ist | - - |
| --with_per | Ob die priorisierte Erfahrung wiederholt (mit DDQN) | - - |
| -Duellieren | Ob Sie Duell -Netzwerke verwenden (mit DDQN) | - - |
| --N_Threads | Anzahl der Threads (A3C) | 16 (Standard) |
| -Gather_Stats | Ob die in 10 Spiele gemachten Statistiken von Punkten berechnet werden sollen (langsam siehe unten) | - - |
| --machen | Ob Sie die Umwelt während des Trainings machen sollen | - - |
| --gpu | GPU -Index | 0 |
Alle Modelle werden unter <algorithm_folder>/models/ beim Abschlusstraining gespeichert. Sie können sie visualisieren, dass sie in derselben Umgebung ausgeführt wurden, in der sie geschult wurden, indem Sie das Skript load_and_run.py ausführen. Für DQN -Modelle sollten Sie den Pfad zum gewünschten Modell im Argument --model_path angeben. Für Schauspieler-kritische Modelle müssen Sie beide Gewichtsdateien in den Argumenten --actor_path und --critic_path angeben.
Mit Tensorboard können Sie die Punktzahl des Agenten im Training überwachen. Beim Training wird ein Protokollordner mit dem Namen der ausgewählten Umgebung erstellt. Um beispielsweise dem A2C-Fortschritt auf Cartpole-V1 zu folgen, rennen Sie einfach:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ Beim Training mit dem Argument --gather_stats wird eine Protokolldatei generiert, die in jeder Folge im Durchschnitt über 10 Spiele enthält: logs.csv . Mit Plotly können Sie die durchschnittliche Belohnung pro Episode visualisieren. Dazu müssen Sie zuerst Plotly installieren und eine kostenlose Lizenz erhalten.
pip3 install plotlyUm Ihre Anmeldeinformationen einzurichten, führen Sie aus:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )Um die Ergebnisse zu zeichnen, rennen Sie schließlich:
python3 utils/plot_results.py < path_to_your_log_file >

