lang2sql
1.0.0
Dieses Repo bietet eine Schritt-für-Schritt-Anleitung und eine Vorlage zum Einrichten einer natürlichen Sprache für SQL-Codegenerator mit der OPNEAI-API.
Das Tutorial ist auch auf Medium erhältlich.
Letztes Update: 7. Januar 2024
Die schnelle Entwicklung von natürlichen Sprachmodellen, insbesondere Großsprachmodellen (LLMs), hat zahlreiche Möglichkeiten für verschiedene Bereiche vorgestellt. Eine der häufigsten Anwendungen ist die Verwendung von LLMs für die Codierung. Zum Beispiel sind OpenAIs Chatgpt und Metas Code Lama LLMs, die Codegeneratoren auf der neuesten Natürlichkeit natürliche Sprache bieten. Ein potenzieller Anwendungsfall ist eine natürliche Sprache für den SQL-Codegenerator, mit dem nichttechnische Fachleute mit einfachen Datenanfragen unterstützt werden und es den Datenteams hoffentlich ermöglichen könnte, sich auf datenintensive Aufgaben zu konzentrieren. Dieses Tutorial konzentriert sich auf die Einrichtung einer Sprache für den SQL -Codegenerator mithilfe der OpenAI -API.
Eine mögliche Anwendung ist ein Chatbot, der auf Benutzeranfragen mit relevanten Daten reagieren kann (Abbildung 1). Der Chatbot kann mit einer Python -Anwendung in einen Slack -Kanal integriert werden, der die folgenden Schritte ausführt:
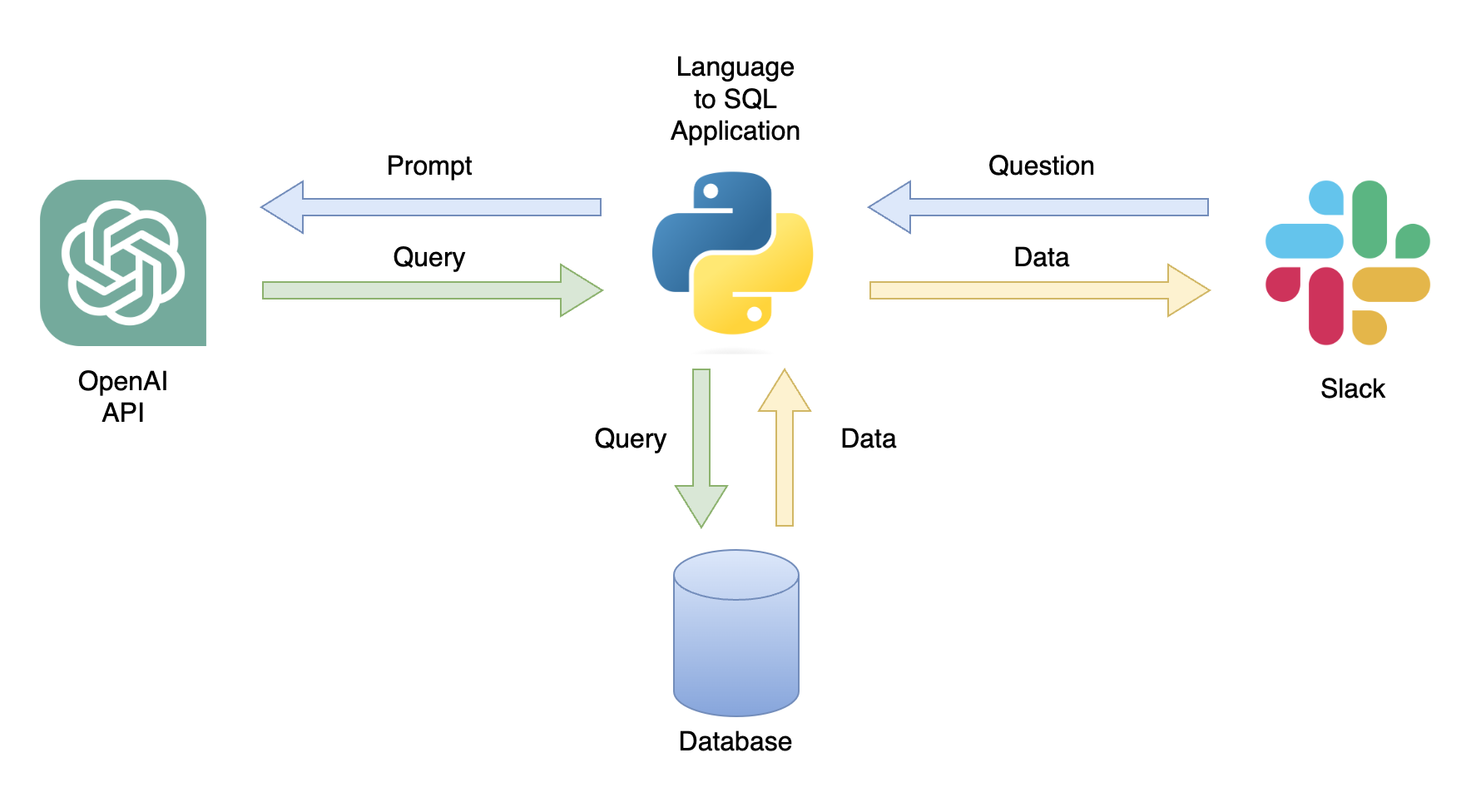
In diesem Tutorial erstellen wir eine schrittweise Python-Anwendung, die Benutzerfragen in SQL-Abfragen umwandelt.
Dieses Tutorial bietet eine Schritt-für-Schritt-Anleitung zum Einrichten einer Python-Anwendung, die allgemeine Fragen mithilfe der OpenAI-API in SQL-Abfragen umwandelt. Dies beinhaltet die folgende Funktionalität:
Abbildung 2 unten beschreibt die allgemeine Architektur einer einfachen Sprache für SQL -Codegenerator.
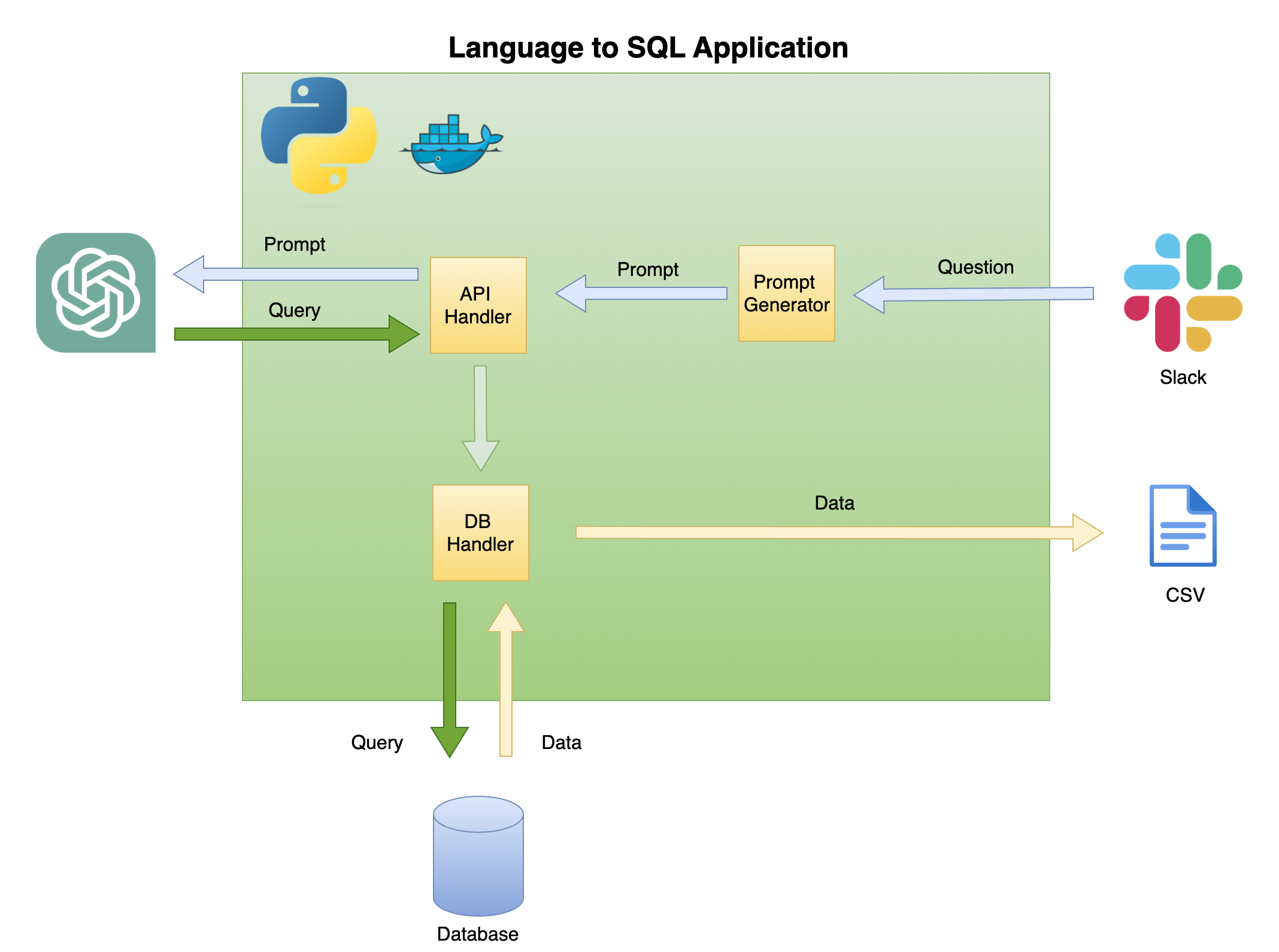
Der Umfang und der Fokus dieses Tutorials liegen auf der Green Box - Erstellen Sie die folgende Funktionalität:
Frage zur Aufforderung - Verwandeln Sie die Frage in ein Eingabeaufforderungformat:
API -Handler - Eine Funktion, die mit der OpenAI -API funktioniert:
DB -Handler - Eine Funktion, die die SQL -Abfrage an die Datenbank sendet und die erforderlichen Daten zurückgibt
Die Hauptvoraussetzung für dieses Tutorial ist das Grundkenntnis von Python. Dies beinhaltet die folgende Funktionalität:
Darüber hinaus sind Grundkenntnisse über SQL und Zugriff auf die OpenAI -API erforderlich.
Obwohl dies nicht erforderlich ist, ist es hilfreich, grundlegende Kenntnisse über Docker zu haben, da das Tutorial in einer Docker -Umgebung mithilfe der Dev Container -Erweiterung von VSCODE erstellt wurde. Wenn Sie keine Erfahrung mit Docker oder der Erweiterung haben, können Sie das Tutorial weiterhin ausführen, indem Sie eine virtuelle Umgebung erstellen und die erforderlichen Bibliotheken installieren (wie unten beschrieben). Das Kenntnis der schnellen Technik und der OpenAI -API ist ebenfalls von Vorteil.
Ich habe ein detailliertes Tutorial über das Festlegen einer python -dockerisierten Umgebung mit VSCODE und der Dev Containers -Erweiterung erstellt:
https://github.com/ramikrispin/vscode-python
Um eine natürliche Sprache für die SQL -Codegenerierung einzurichten, verwenden wir die folgenden Python -Bibliotheken:
pandas - Daten während des gesamten Prozesses verarbeitenduckdb - um die Arbeit mit der Datenbank zu simulierenopenai - Mit der OpenAI -API zusammenarbeitentime und os - CSV -Dateien und Formatfelder ladenDieses Repository enthält die erforderlichen Einstellungen, um eine dockerisierte Umgebung mit den Tutorialanforderungen in VSCODE und der Dev Containers -Erweiterung zu starten. Weitere Details finden Sie im nächsten Abschnitt.
Alternativ können Sie eine virtuelle Umgebung einrichten und die Tutorial -Anforderungen installieren, indem Sie die folgenden Anweisungen unter Verwendung der Anweisungen im Abschnitt Virtual Umgebung befolgen.
Dieses Tutorial wurde in einer dockerisierten Umgebung mit VSCODE und der Dev Containers -Erweiterung erstellt. Um es mit VSCODE auszuführen, müssen Sie die Erweiterung der Entwicklercontainer installieren und Docker -Desktop (oder gleichwertig) öffnen. Die Einstellungen der Umgebung sind im Ordner .devcontainer verfügbar:
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
Der devcontainer.json verfügt über die Build -Anweisungen und die VSCODE -Einstellungen für diese dockerisierte Umgebung:
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
Wo das build -Argument die docker build -Methode definiert und die Argumente für den Build festlegt. In diesem Fall setzen wir die Python -Version auf 3.10 und die virtuelle Konda -Umgebung auf ang2sql . Das Argument METHOD definiert die Art der Umgebung - entweder openai , um die Anforderungsbibliotheken für dieses Tutorial mithilfe der OpenAI -API oder transformers zu installieren, um die Umgebung für die Umarmung von API (das für dieses Tutorial aus dem Spielraum herauszukommen) festgelegt wird.
Das remoteEnv -Argument ermöglicht die Einstellung von Umgebungsvariablen. Wir werden es verwenden, um den OpenAI -API -Schlüssel festzulegen. In diesem Fall habe ich die Variable lokal als OPENAI_KEY festgelegt und lade sie mit dem localEnv -Argument.
Wenn Sie mehr über die Einrichtung einer Python -Entwicklungsumgebung mit VSCODE und Docker erfahren möchten, überprüfen Sie dieses Tutorial.
Wenn Sie die Tutorial Dockerized -Umgebung nicht verwenden, können Sie mit dem folgenden Skript eine lokale virtuelle Umgebung aus der Befehlszeile erstellen:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
HINWEIS: Ich habe conda verwendet und es sollte auch mit jeder anderen virutalen Umgebungsmethode funktionieren.
Wir verwenden die Variablen ENV_NAME und PYTHON_VER , um die virtuelle Umgebung bzw. die Python -Version festzulegen.
Um zu bestätigen, dass Ihre Umgebung ordnungsgemäß festgelegt ist, bestätigen Sie die conda list um zu bestätigen, dass die erforderlichen Python -Bibliotheken installiert sind. Sie sollten die folgende Ausgabe erwarten:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
Wir werden die OpenAI-API verwenden, um mit der Text-Davinci-003-Engine auf ChatGPT zugreifen zu können. Dies erforderte ein aktives OpenAI -Konto und einen API -Schlüssel. Es ist unkompliziert, ein Konto und eine API -Taste festzulegen, die den Anweisungen im folgenden Link folgt:
https://openai.com/product
Sobald Sie den Zugriff auf die API und einen Schlüssel festgelegt haben, empfehle ich, den Schlüssel als Umgebungsvariable zu Ihrer .zshrc -Datei (oder eines anderen von Ihnen verwendeten Formats hinzuzufügen, um Umgebungsvariablen auf Ihrem Shell -System zu speichern). Ich habe meine API -Schlüssel unter der Umgebungsvariablen OPENAI_KEY gespeichert. Aus überzeugenden Gründen empfehle ich Ihnen, dieselbe Namenskonvention zu verwenden.
Um die Variable auf der .zshrc -Datei (oder in gleichwertigem) festlegen, fügen Sie der folgenden Zeile der Datei hinzu:
export OPENAI_KEY= " YOUR_API_KEY " Wenn Sie VSCODE verwenden oder aus dem Terminal ausgeführt werden, müssen Sie Ihre Sitzung neu starten, nachdem Sie die Variable zur .zshrc -Datei hinzugefügt haben.
Um die Datenbankfunktionalität zu simulieren, werden wir den Chicago Crime -Datensatz verwenden. Dieser Datensatz enthält ausführliche Informationen zu den in der Stadt Chicago seit 2001 aufgezeichneten Verbrechen. Mit fast 8 Millionen Datensätzen und 22 Spalten enthält der Datensatz Informationen wie die Kriminalitätsklassifizierung, den Standort, die Zeit, das Ergebnis usw. Die Daten können vom Chicago-Datenportal heruntergeladen werden. Da wir die Daten lokal als PANDAS -Datenrahmen speichern und mit Duckdb zur SQL -Abfrage simulieren, werden wir eine Teilmenge der Daten mit den letzten drei Jahren herunterladen.
Sie können die Daten aus der API ziehen oder eine CSV -Datei herunterladen. Um nicht jedes Mal, wenn ich das Skript ausführe, die API anzurufen, lade ich die Dateien herunter und speichere sie unter dem Datenordner. Nachfolgend finden Sie die Links zu den Datensätzen nach Jahr:
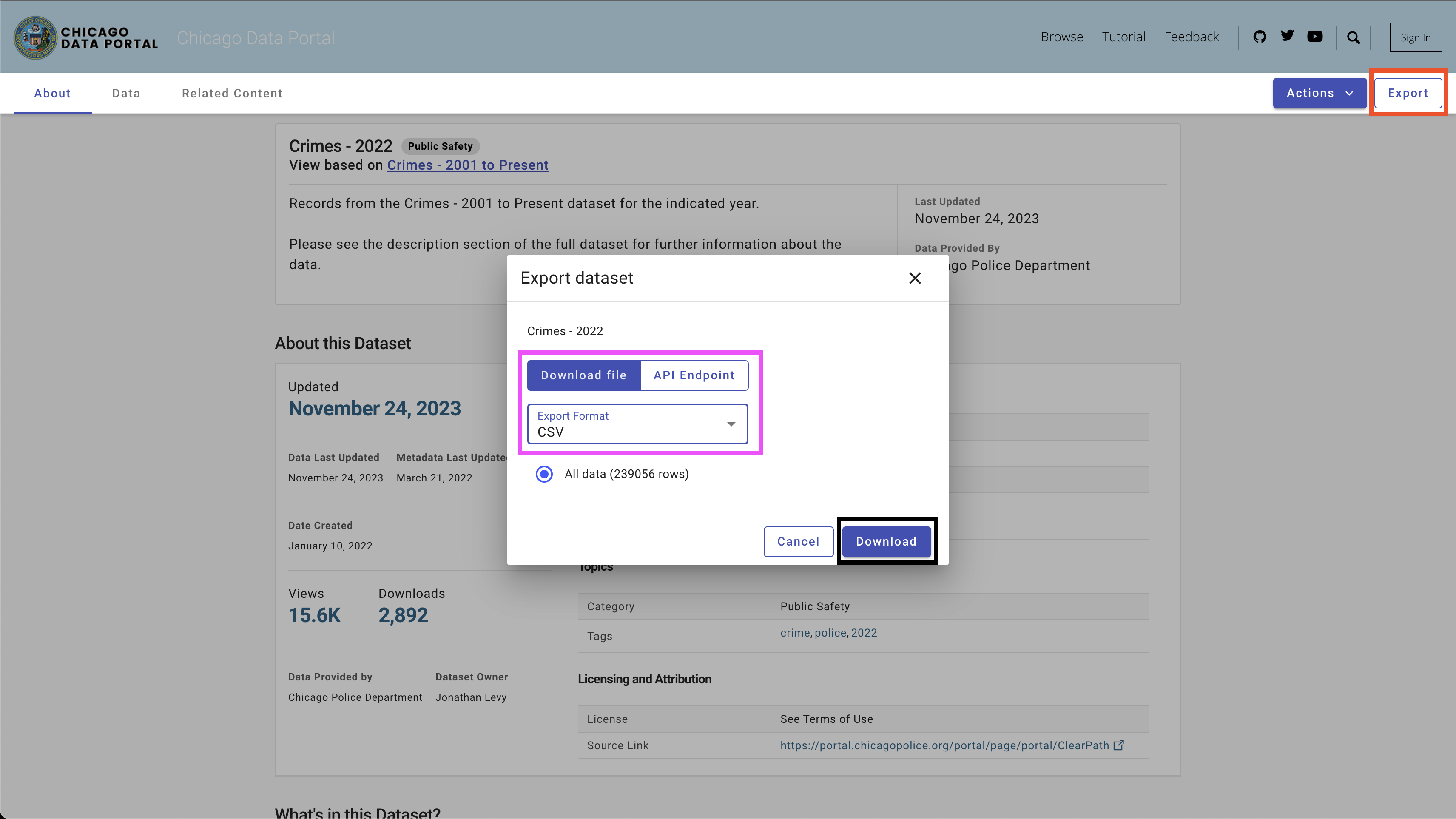
Um die Daten herunterzuladen, verwenden Sie die Schaltfläche Export oben rechts, wählen Sie die CSV -Option aus und klicken Sie auf die Schaltfläche Download , wie in Abbildung 4 angezeigt.
Ich habe die folgende Namenskonvention verwendet - chicago_crime_year.csv und die Dateien im data gespeichert. Jede Dateigröße ist nahe 50 MB. Daher habe ich sie der Git Ignore -Datei unter dem data hinzugefügt, und sie sind in diesem Repo nicht verfügbar. Nachdem Sie die Dateien heruntergeladen und ihre Namen eingestellt haben, sollten Sie die folgenden Dateien im Ordner haben:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
Hinweis: Zum Zeitpunkt des Erstellens dieses Tutorials werden die Daten für 2023 noch aktualisiert. Daher erhalten Sie möglicherweise etwas andere Ergebnisse, wenn Sie einige der Abfragen im folgenden Abschnitt ausführen.
Gehen wir mit dem aufregenden Teil über, bei dem ein SQL -Codegenerator eingerichtet wird. In diesem Abschnitt erstellen wir eine Python -Funktion, die die Frage eines Benutzers, die zugehörige SQL -Tabelle und den OpenAI -API -Schlüssel aufnimmt und die SQL -Abfrage ausgibt, die die Frage des Benutzers beantwortet.
Beginnen wir mit dem Laden des Chicago Crime -Datensatzes und der erforderlichen Python -Bibliotheken.
Erstens zuerst - laden wir die erforderlichen Python -Bibliotheken:
import pandas as pd
import duckdb
import openai
import time
import osWir werden das Betriebssystem und die Zeitbibliotheken verwenden, um CSV -Dateien zu laden und bestimmte Felder neu formatieren. Die Daten werden mit der Pandas -Bibliothek verarbeitet und wir werden SQL -Befehle mit der Duckdb -Bibliothek simulieren. Zuletzt werden wir mit der OpenAI -Bibliothek eine Verbindung zur OpenAI -API herstellen.
Als nächstes laden wir die CSV -Dateien aus dem Datenordner. Der folgende Code liest alle im Datenordner verfügbaren CSV -Dateien:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]Wenn Sie die entsprechenden Dateien für die Jahre 2021 bis 2023 heruntergeladen und dieselbe Namenskonvention verwendet haben, sollten Sie die folgende Ausgabe erwarten:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]Als nächstes werden wir alle Dateien lesen und laden und in einen Pandas -Datenrahmen anhängen:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headWenn Sie die Dateien korrekt geladen haben, sollten Sie die folgende Ausgabe erwarten:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) Hinweis: Beim Erstellen dieses Tutorials waren Teildaten für 2023 verfügbar. Das Anhängen der drei Dateien würde zu mehr Zeilen als gezeigt führen (648830 Zeilen).
Bevor wir uns mit dem Python -Code befassen, lasst uns innehalten und überprüfen, wie schnell das Engineering funktioniert und wie wir Chatgpt (und allgemein beliebige LLM) helfen können, die besten Ergebnisse zu erzielen. Wir werden in diesem Abschnitt die Chatgpt -Weboberfläche verwenden.
Ein Hauptfaktor für statistische und maschinelle Lernmodelle ist, dass die Ausgangsqualität von der Eingangsqualität abhängt. Wie der berühmte Satz sagt- Junk-in, Junk-out . In ähnlicher Weise hängt die Qualität der LLM -Ausgabe von der Qualität der Eingabeaufforderung ab.
Nehmen wir beispielsweise an, wir möchten die Anzahl der Fälle zählen, die eine Verhaftung hatten.
Wenn wir die folgende Eingabeaufforderung verwenden:
Create an SQL query that counts the number of records that ended up with an arrest.
Hier ist die Ausgabe von Chatgpt:
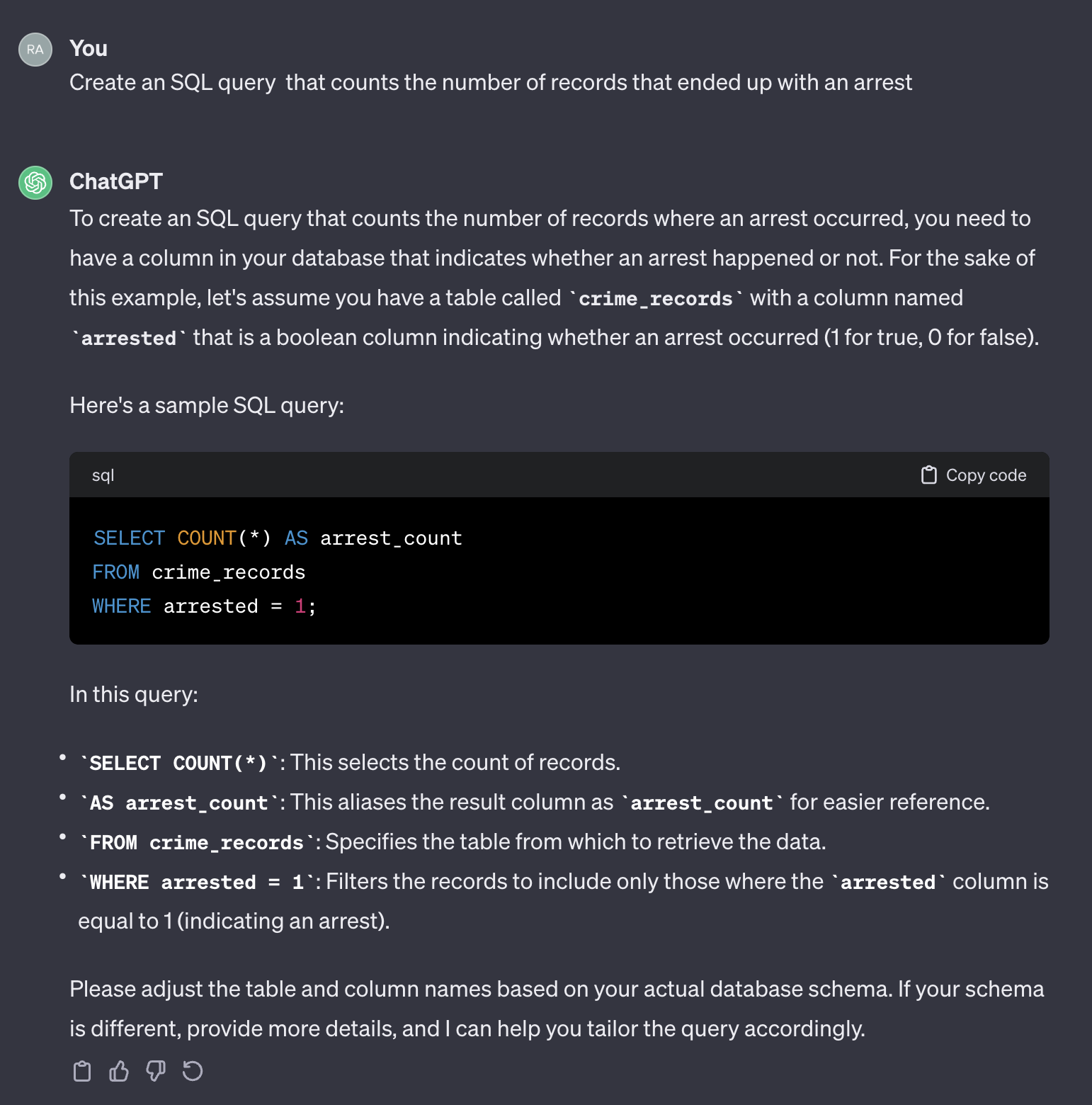
Es ist erwähnenswert, dass Chatgpt eine generische Antwort liefert. Obwohl es im Allgemeinen korrekt ist, ist es möglicherweise nicht praktisch, in einem automatisierten Prozess zu verwenden. Erstens übereinstimmen die Feldnamen in der Antwort nicht den in der tatsächlichen Tabelle, die wir abfragen müssen. Zweitens ist das Feld, das das Erliegen der Verhaftung darstellt, ein Boolescher ( true oder false ) anstelle einer Ganzzahl ( 0 oder 1 ).
Chatgpt wirkt in diesem Sinne wie ein Mensch. Es ist unwahrscheinlich, dass Sie eine genauere Antwort von einem Menschen erhalten, indem Sie dieselbe Frage in einem Codierungsformular wie dem Stack -Überlauf oder einer ähnlichen Plattform stellen. Angesichts der Tatsache, dass wir keinen Kontext oder zusätzliche Informationen über die Tabellenmerkmale bereitgestellt haben, wäre es unangemessen, dass Chatgpt die Feldnamen und ihre Werte erraten würde. Der Kontext ist ein entscheidender Faktor in jeder Eingabeaufforderung. Um diesen Punkt zu veranschaulichen, lassen Sie uns sehen, wie Chatgpt die folgende Eingabeaufforderung behandelt:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
Hier ist die Ausgabe von Chatgpt:
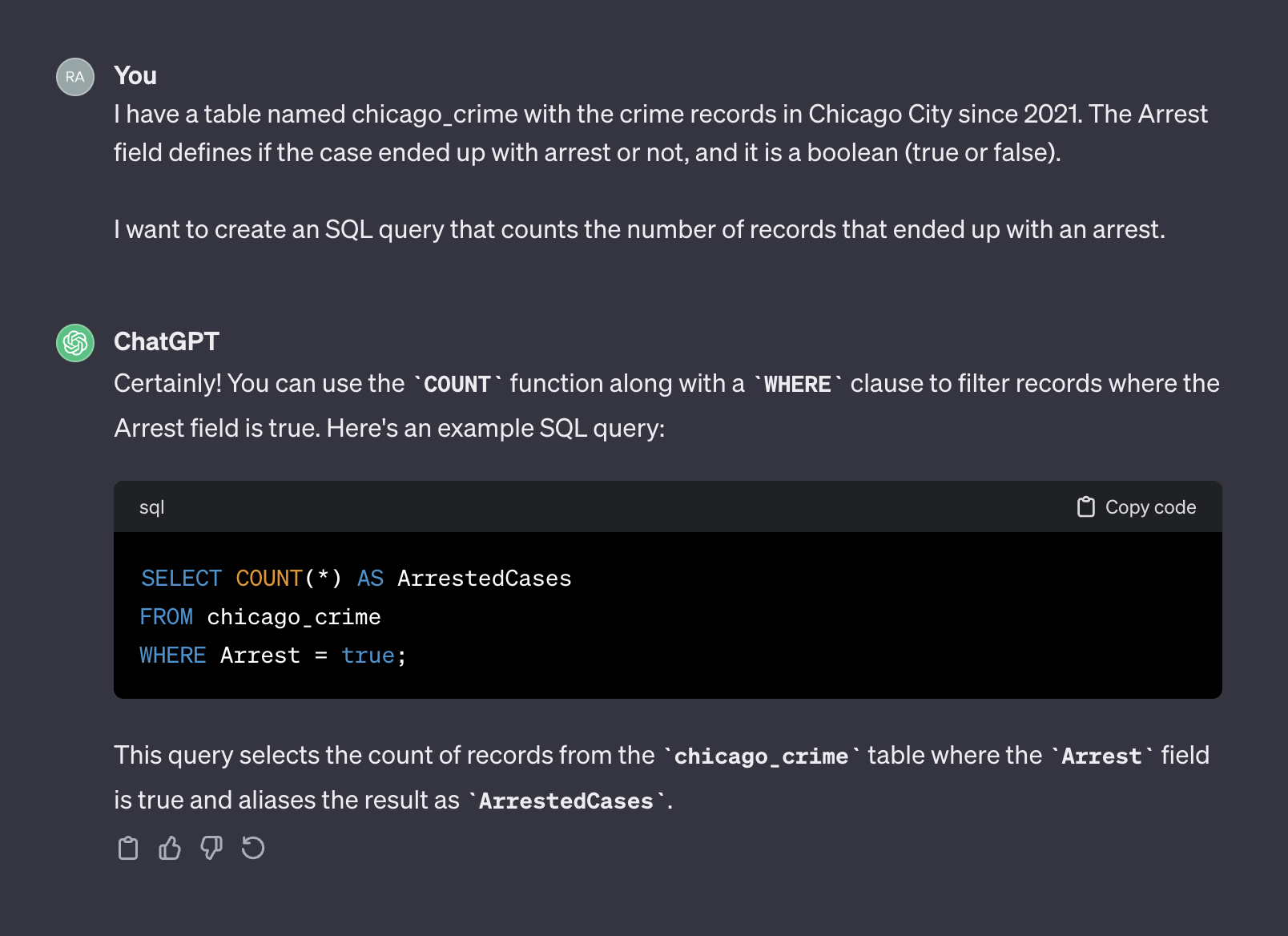
Nach dem Hinzufügen von Kontext gab Chatgpt diesmal eine korrekte Abfrage zurück, die wir verwenden können. Im Allgemeinen sollte die Eingabeaufforderung bei der Arbeit mit einem Textgenerator zwei Komponenten enthalten - Kontext und Anfrage. In der obigen Eingabeaufforderung stellt der erste Absatz den Kontext der Eingabeaufforderung dar:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
Wo der zweite Absatz die Anfrage darstellt:
I want to create an SQL query that counts the number of records that ended up with an arrest.
Die OpenAI -API bezieht sich auf den Kontext als system und Anfrage als user .
Die OpenAI -API -Dokumentation enthält eine Empfehlung, wie das system und user in einer Eingabeaufforderung festgelegt werden, wenn Sie um eine SQL -Code beantragt werden:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
Im nächsten Abschnitt werden wir das obige OpenAI-Beispiel verwenden und es in eine allgemeine Vorlage verallgemeinern.
Im vorherigen Abschnitt haben wir über die Bedeutung des schnellen Engineerings und darüber diskutiert, wie die Bereitstellung eines guten Kontextes die LLM -Antwortgenauigkeit verbessern kann. Darüber hinaus haben wir die von OpenAI empfohlene schnelle Struktur für die Erzeugung von SQL -Code gesehen. In diesem Abschnitt werden wir uns darauf konzentrieren, den Prozess der Erstellung von Aufforderungen für die SQL -Generation auf der Grundlage dieser Prinzipien zu verallgemeinern. Ziel ist es, eine Python -Funktion zu erstellen, die einen Tabellennamen und eine Benutzerfrage empfängt und die Eingabeaufforderung entsprechend erstellt. Für die Tabelle chicago_crime , die wir zuvor geladen haben, und die Frage, die wir im vorherigen Abschnitt gestellt haben, sollte die Funktion die folgende Eingabeaufforderung erstellen:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
Beginnen wir mit der schnellen Struktur. Wir werden das OpenAI -Format übernehmen und die folgende Vorlage verwenden:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" Wobei die system_template zwei Elemente empfangen hat:
Für dieses Tutorial werden wir die Duckdb -Bibliothek verwenden, um den Datenrahmen der Pandas zu verarbeiten, da es sich um eine SQL -Tabelle handelte und die Feldnamen und Attribute der Tabelle unter Verwendung der Funktion duckdb.sql extrahiert. Lassen Sie uns beispielsweise den Befehl DESCRIBE , um die Informationsinformationen von chicago_crime zu extrahieren:
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )Die die folgende Tabelle zurückgeben sollte:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘Hinweis: Die Informationen, die wir benötigen - Der Spaltenname und sein Attribut sind in den ersten beiden Spalten verfügbar. Daher müssen wir diese Säulen analysieren und mit dem folgenden Format kombinieren:
Column_Name Column_Attribute
Beispielsweise sollte die Spalte Case Number in das folgende Format übertragen:
Case Number VARCHAR
Die Funktion create_message unten orchestriert den Vorgang des Tabellennamens und der Frage und der Eingabeaufforderung mithilfe der obigen Logik:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m Die Funktion erstellt die Eingabeaufforderung Vorlage und gibt die system und user sowie die Spaltennamen und -attribute zurück. Lassen Sie uns beispielsweise die Anzahl der Verhaftungsfrage ausführen:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )Dies wird zurückkehren:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object Die Ausgabe der Funktion create_message wurde so konzipiert, dass sie in die OpenAI -API ChatCompletion.create -Funktionsargumente entspricht, die wir im nächsten Abschnitt überprüfen werden.
Dieser Abschnitt konzentriert sich auf die Funktionalität der Openai Python Library. Die OpenAI -Bibliothek ermöglicht einen nahtlosen Zugriff auf die OpenAI -REST -API. Wir werden die Bibliothek verwenden, um eine Verbindung zur API herzustellen und GET -Anfragen mit unserer Eingabeaufforderung zu senden.
Beginnen wir zunächst eine Verbindung zur API, indem wir unsere API mit der Funktion openai.api_key füttern:
openai . api_key = os . getenv ( 'OPENAI_KEY' ) HINWEIS: Wir haben die getenv -Funktion aus der os verwendet, um die Umgebungsvariable OpenAI_Key zu laden. Alternativ können Sie Ihren API -Schlüssel direkt füttern:
openai . api_key = "YOUR_OPENAI_API_KEY"Die OpenAI -API bietet Zugriff auf eine Vielzahl von LLMs mit unterschiedlichen Funktionen. Sie können die Funktion openai.model.list verwenden, um eine Liste der verfügbaren Modelle zu erhalten:
openai . Model . list () Um es in ein schönes Format zu verwandeln, können Sie es in einen pandas -Datenrahmen einwickeln:
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headUnd sollte die folgende Ausgabe erwarten:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
Für unseren Anwendungsfall, die Textgenerierung, werden wir das gpt-3.5-turbo Modell verwenden, das eine Verbesserung des GPT3-Modells darstellt. Das gpt-3.5-turbo -Modell stellt eine Reihe von Modellen dar, die immer wieder aktualisiert werden. Wenn die Modellversion nicht angegeben ist, wird die API auf die neueste stabile Version hinweisen. Beim Erstellen dieses Tutorials war das Standardmodell 3.5 gpt-3.5-turbo-0613 mit 4.096 Token und mit Daten bis September 2021 trainiert.
Um eine GET -Anfrage mit unserer Eingabeaufforderung zu senden, werden wir die Funktion ChatCompletion.create verwenden. Die Funktion hat viele Argumente, und wir werden die folgenden verwenden:
model - Die zu verwendende Modell -ID, eine vollständige Liste hier verfügbarmessages - Eine Liste von Nachrichten, die die bisherige Konversation umfassen (z. B. die Eingabeaufforderung)temperature - Verwalten Sie die Zufälligkeit oder den Determinismus des Prozessausgangs, indem Sie das Abtasttemperaturniveau festlegen. Das Temperaturniveau akzeptiert Werte zwischen 0 und 2. Wenn der Argumentwert höher ist, wird der Ausgang zufällig. Umgekehrt wird die Ausgabe deterministischer (reproduzierbar), wenn der Argumentwert näher an 0 ist, die Ausgabe wird deterministischer (reproduzierbar).max_tokens - die maximale Anzahl von Token, die im Fertigstellung generiert werden sollenDie vollständige Liste der auf dem API -Dokumentaiton verfügbaren Funktionsargumente.
Im folgenden Beispiel werden wir diesmal die gleiche Eingabeaufforderung wie die auf der ChatGPT -Webschnittstelle (dh Abbildung 5) verwenden, diesmal mit der API. Wir generieren die Eingabeaufforderung mit der Funktion create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) Lassen Sie uns die obige Eingabeaufforderung in die Struktur der ChatCompletion.create messages verwandeln:
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] Als nächstes senden wir die Eingabeaufforderung (dh das message ) mit der Funktion ChatCompletion.create an die API:
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) Wir werden das temperature auf 0 einstellen, um eine hohe Reproduzierbarkeit zu gewährleisten und die Anzahl der Token im Textabschluss auf 256 einzuschränken. Die Funktion gibt ein JSON -Objekt mit den Textabschluss, Metadaten und anderen Informationen zurück:
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}Mit den Reaktionsindien können wir die SQL -Abfrage extrahieren:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' Verwenden Sie die Funktion duckdb.sql , um den SQL -Code auszuführen:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Im nächsten Abschnitt werden wir alle Schritte verallgemeinern und funktionalisieren.
In den vorherigen Abschnitten haben wir das Eingabeaufforderungformat eingeführt, die Funktion create_message festgelegt und die Funktionalität der ChatCompletion.create -Funktion überprüft. In diesem Abschnitt nähen wir alles zusammen.
Eine Sache, die über den zurückgegebenen SQL -Code aus der ChatCompletion.create -Funktion beachtet werden muss. Dies könnte ein Problem sein, wenn der Variablenname in der Abfrage zwei oder mehr Wörter kombiniert. Beispielsweise führt die Verwendung einer Variablen wie Case Number oder Primary Type aus der chicago_crime innerhalb einer Abfrage ohne Zitate zu einem Fehler.
Wir werden die folgende Helferfunktion verwenden, um Zitaten zu den Variablen in der Abfrage hinzuzufügen, wenn die zurückgegebene Abfrage keine hat:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) Die Funktionseingaben sind die Abfrage und die Spaltennamen der entsprechenden Tabelle. Es schaltet sich über die Spaltennamen und fügt Zitate hinzu, wenn es in der Abfrage eine Übereinstimmung findet. Zum Beispiel können wir es mit der SQL -Abfrage ausführen, die wir aus der ChatCompletion.create -Funktionsausgabe analysieren:
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Sie können feststellen, dass es der Arrest Zitate hinzugefügt hat.
Wir können nun die lang2sql -Funktion vorstellen, die die drei bisher eingeführten Funktionen nutzt - create_message , ChatCompletion.create und add_quotes , um eine Benutzerfrage in einen SQL -Code zu übersetzen:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output Die Funktion empfängt als Eingänge den OpenAI -API -Schlüssel, den Tabellennamen und die Kernparameter der ChatCompletion.create -Funktion und gibt ein Objekt mit der Eingabeaufforderung, der API -Antwort und der Parsen -Abfrage zurück. Lassen Sie uns beispielsweise versuchen, dieselbe Abfrage neu auszuführen, die wir im vorherigen Abschnitt mit der lang2sql -Funktion verwendet haben:
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )Wir können die SQL -Abfrage aus dem Ausgabeobjekt extrahieren:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;Wir können die Ausgabe in Bezug auf die im vorherigen Abschnitt erhaltenen Ergebnisse testen:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Fügen wir nun der Frage zusätzliche Komplexität hinzu und stellen Sie Fälle, die im Jahr 2022 eine Verhaftung hatten:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) Wie Sie sehen können, hat das Modell das relevante Feld als Year korrekt identifiziert und die richtige Abfrage generiert:
print ( response . sql )Der SQL -Code:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;Testen der Abfrage in der Tabelle:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘Hier ist ein Beispiel für eine einfache Frage, die eine Gruppierung nach einer bestimmten Variablen erforderte:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Aus der Antwortausgabe können Sie sehen, dass der SQL -Code in diesem Fall korrekt ist:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "Dies ist die Ausgabe der Abfrage:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘Last but not least kann der LLM den Kontext (z. B. die Variable) identifizieren, auch wenn wir einen teilweisen variablen Namen angeben:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Es gibt den folgenden SQL -Code zurück:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;Dies ist die Ausgabe der Abfrage:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘In diesem Tutorial haben wir gezeigt, wie ein SQL -Codegenerator mit einigen Zeilen Python -Code erstellt und die OpenAI -API verwendet wird. Wir haben gesehen, dass die Qualität der Eingabeaufforderung für den Erfolg des resultierenden SQL -Codes von entscheidender Bedeutung ist. Zusätzlich zu dem von der Eingabeaufforderung bereitgestellten Kontext sollten die Feldnamen auch Informationen über die Eigenschaften des Feldes liefern, um der LLM die Relevanz des Feldes für die Benutzerfrage zu ermitteln.
Obwohl dieses Tutorial auf die Arbeit mit einer einzelnen Tabelle (z. B. keine Verknüpfungen zwischen Tabellen) beschränkt war, können einige LLMs, wie die auf OpenAI verfügbaren, komplexeren Fälle, einschließlich der Arbeit mit mehreren Tabellen und der Identifizierung der korrekten Verbindungsvorgänge. Die Anpassung der LANG2SQL -Funktion für mehrere Tabellen kann ein schöner nächster Schritt sein.
Dieses Tutorial ist unter einer Kreative Commons Attribution-Noncommercial-Sharealike 4.0 International Lizenz lizenziert.


