
[Verwandte Empfehlungen: JavaScript-Video-Tutorials, Web-Frontend]
Egal welche Programmiersprache Sie verwenden, Strings sind ein wichtiger Datentyp. Folgen Sie mir, um mehr über JavaScript Strings zu erfahren!
Ein String ist ein String, der aus Zeichen besteht. Wenn Sie C und Java studiert haben, sollten Sie wissen, dass die Zeichen selbst auch zu einem unabhängigen Typ werden können. Allerdings gibt es JavaScript keinen einzelnen Zeichentyp, sondern nur Zeichenfolgen der Länge 1 .
JavaScript Strings verwenden eine feste UTF-16 -Codierung. Unabhängig davon, welche Codierung wir beim Schreiben des Programms verwenden, wird sie nicht beeinträchtigt.
: einfache Anführungszeichen, doppelte Anführungszeichen und Backticks.
let single = 'abcdefg';//Einfache Anführungszeichen let double = "asdfghj";//Doppelte Anführungszeichen let backti = `zxcvbnm`;//Backticks
Einfache und doppelte Anführungszeichen haben den gleichen Status, wir machen keinen Unterschied.
Backtickszur String-Formatierung
ermöglichen es uns, Strings elegant mit ${...} zu formatieren, anstatt String-Additionen zu verwenden.
let str = `Ich bin ${Math.round(18.5)} Jahre alt.`;console.log(str) ;

Durch mehrzeilige String-
Backticks kann sich der String auch über mehrere Zeilen erstrecken, was sehr nützlich ist, wenn wir mehrzeilige Strings schreiben.
let ques = `Ist der Autor gutaussehend? A. Sehr hübsch; B. So gutaussehend; C. Super gutaussehend;`;console.log(ques);
Ergebnisse der Codeausführung:
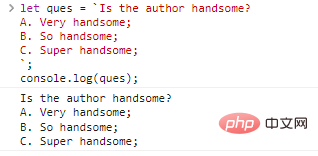
Sieht es nicht so aus, als wäre daran nichts auszusetzen? Dies kann jedoch nicht mit einfachen und doppelten Anführungszeichen erreicht werden. Wenn Sie das gleiche Ergebnis erzielen möchten, können Sie Folgendes schreiben:
let ques = 'Ist der Autor gutaussehend?nA. Sehr gutaussehend;nB. Super gutaussehend;'; console.log(ques);
Der obige Code enthält ein Sonderzeichen n , das in unserem Programmierprozess am häufigsten vorkommt.
n auch „Newline-Zeichen“ genannt, unterstützt einfache und doppelte Anführungszeichen zur Ausgabe mehrzeiliger Zeichenfolgen. Wenn die Engine eine Zeichenfolge ausgibt und auf n trifft, wird die Ausgabe in einer anderen Zeile fortgesetzt, wodurch eine mehrzeilige Zeichenfolge realisiert wird.
Obwohl n aus zwei Zeichen besteht, belegt es nur eine Zeichenposition. Dies liegt daran, dass ein Escape-Zeichen in der Zeichenfolge ist und die durch das Escape-Zeichen geänderten Zeichen zu Sonderzeichen werden.
Sonderzeichenliste
| Sonderzeichenbeschreibung | |
|---|---|
n | Zeilenzeichen, das zum Beginn einer neuen Zeile des Ausgabetexts verwendet wird. |
r | bewegt den Cursor an den Zeilenanfang. In Windows Systemen wird rn zur Darstellung eines Zeilenumbruchs verwendet, was bedeutet, dass der Cursor zuerst an den Zeilenanfang und dann verschoben werden muss in die nächste Zeile wechseln, bevor in eine neue Zeile gewechselt werden kann. Andere Systeme können n direkt verwenden. |
' " | Einfache und doppelte Anführungszeichen, hauptsächlich weil einfache und doppelte Anführungszeichen Sonderzeichen sind. Wenn wir einfache und doppelte Anführungszeichen in einer Zeichenfolge verwenden möchten, müssen wir sie maskieren. |
\ | Backslash, auch weil |
b f v | , Seitenvorschub, vertikale Beschriftung – es wird nicht mehr verwendet. |
xXX | ist beispielsweise ein hexadezimales Unicode Zeichen, das als XX codiert ist : x7A bedeutet. z (Die hexadezimale Unicode Kodierung von z ist 7A |
uXXXX | Unicode XXXX u00A9 |
( 1-6 hexadezimale Zeichen u{X...X} | UTF-32 Kodierung ist das Unicode Symbol von X...X . |
Zum Beispiel:
console.log('Ich bin Student.');// 'console.log(""Ich liebe U. "");/ / "console.log("\n ist ein neues Zeilenzeichen.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// Code Ausführungsergebnisse:
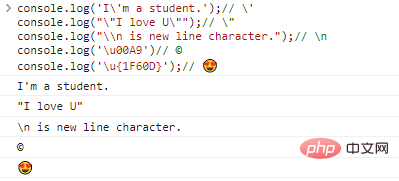
Mit der Existenz des Escape-Zeichens können wir theoretisch jedes beliebige Zeichen ausgeben, solange wir die entsprechende Kodierung finden.
Vermeiden Sie die Verwendung von ' und "
für einfache und doppelte Anführungszeichen in Zeichenfolgen. Wir können doppelte Anführungszeichen geschickt in einfachen Anführungszeichen verwenden, einfache Anführungszeichen in doppelten Anführungszeichen verwenden oder einfache und doppelte Anführungszeichen direkt in Backticks verwenden. Vermeiden Sie die Verwendung von Escape-Zeichen, zum Beispiel:
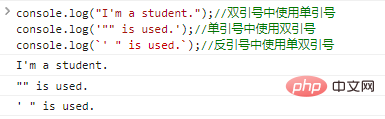
console.log("Ich bin Student.");
//Einfache Anführungszeichen innerhalb doppelter Anführungszeichen verwenden console.log('"" wird verwendet.');
//Doppelte Anführungszeichen innerhalb einfacher Anführungszeichen verwenden console.log(`' " wird verwendet.`);
//Die Ergebnisse der Codeausführung unter Verwendung einfacher und doppelter Anführungszeichen in Backticks lauten wie folgt:
Über die .length Eigenschaft der Zeichenfolge können wir die Länge der Zeichenfolge ermitteln:
console.log("HelloWorldn".length);//11 n belegt hier nur ein Zeichen.
Im Kapitel „Methoden grundlegender Typen“ haben wir untersucht, warum grundlegende Typen in
JavaScriptEigenschaften und Methoden haben. Erinnern Sie sich noch?
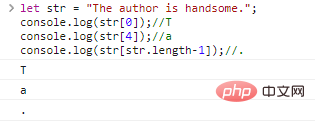
string ist eine Zeichenkette über [字符下标] 0
let str = „Der Autor ist gutaussehend.“; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//
Ergebnisse der Codeausführung:
Wir können auch die Funktion charAt(post) verwenden, um Zeichen zu erhalten:
let str = "Der Autor ist gutaussehend.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.Der
Ausführungseffekt der beiden ist genau der gleiche, der einzige Unterschied besteht darin, auf Zeichen außerhalb der Grenzen zuzugreifen:
let str = "01234"; console.log(str[ 9]);//undefinedconsole.log(str.charAt(9));//"" (leere Zeichenfolge)
Wir können auch for ..of verwenden, um die Zeichenfolge zu durchlaufen:
for(let c of '01234'){
console.log(c);} ,
JavaScript er definiert ist. Beispiel:
let str = "Const";str[0] = 'c' ;console.log(str);
Ergebnisse:
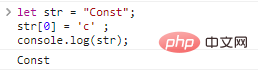
Wenn Sie eine andere Zeichenfolge erhalten möchten, können Sie nur eine neue erstellen:
let str = "Const";str = str.replace('C','c');console.log(str); Es scheint, dass wir Die Zeichenfolge wurde geändert. Tatsächlich wurde die ursprüngliche Zeichenfolge nicht geändert. Wir erhalten die neue Zeichenfolge, die von der replace zurückgegeben wird.
wandelt die Groß-/Kleinschreibung einer Zeichenfolge oder die Groß-/Kleinschreibung eines einzelnen Zeichens in einer Zeichenfolge um.
Die Methoden für diese beiden Zeichenfolgen sind relativ einfach, wie im Beispiel gezeigt:
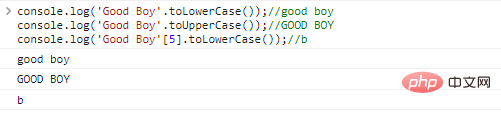
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Good Boy'.toUpperCase());//GOOD
BOYconsole.log('Good Boy'[5].toLowerCase());//b Ergebnisse der Codeausführung:
Die Funktion .indexOf(substr,idx) beginnt an der idx -Position der Zeichenfolge, sucht nach der Position der Teilzeichenfolge substr und gibt den Index des ersten Zeichens zurück Teilzeichenfolge, wenn erfolgreich, oder -1 wenn fehlgeschlagen.
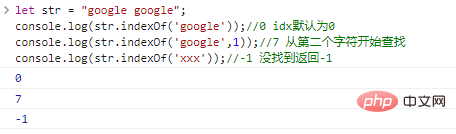
let str = "google google";console.log(str.indexOf('google'));
//0 idx ist standardmäßig 0console.log(str.indexOf('google',1));
//7 Durchsuchen Sie console.log(str.indexOf('xxx')); beginnend mit dem zweiten Zeichen.
//-1 nicht gefunden gibt -1 Codeausführungsergebnis zurück:
Wenn wir die Positionen aller Teilstrings im String abfragen möchten, können wir eine Schleife verwenden:
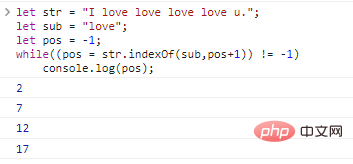
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf (sub,pos+1)) != -1)
console.log(pos); Die Ergebnisse der Codeausführung sind wie folgt:
.lastIndexOf(substr,idx) sucht rückwärts nach Teilzeichenfolgen und findet zunächst die letzte passende Zeichenfolge:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx ist standardmäßig 0 da indexOf() und lastIndexOf() -1 zurückgeben, wenn die Abfrage nicht erfolgreich ist, und ~-1 === 0 . Das heißt, die Verwendung ~ ist nur dann wahr, wenn das Abfrageergebnis nicht -1 ist, sodass wir Folgendes tun können:
let str = "google google";if(~indexOf('google',str)){
...} Normalerweise empfehlen wir nicht, eine Syntax zu verwenden, bei der die Syntaxmerkmale nicht klar wiedergegeben werden können, da dies Auswirkungen auf die Lesbarkeit hat. Glücklicherweise erscheint der obige Code nur in der alten Version des Codes. Er wird hier erwähnt, damit beim Lesen des alten Codes nicht jeder verwirrt wird.
Ergänzung:
~ist der bitweise Negationsoperator. Beispiel: Die binäre Form der Dezimalzahl2ist0010und die binäre Form von~2ist1101(Komplement), also-3.Eine einfache Art zu verstehen,
~nist äquivalent zu-(n+1), zum Beispiel:~2 === -(2+1) === -3
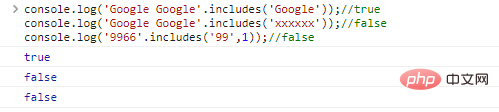
.includes(substr,idx) wird verwendet, um zu bestimmen idx ob sich substr in der Zeichenfolge befindet.
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google'. Includes('xxxxxx'));//falseconsole.log('9966'.includes('99',1));//false Code-Ausführungsergebnisse:
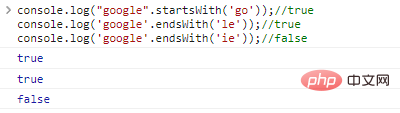
.startsWith('substr') und .endsWith('substr') bestimmen jeweils, ob die Zeichenfolge mit substr beginnt oder endet.
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));//falsches Code-Ausführungsergebnis:
.substr() , .substring() , .slice() werden alle verwendet, um Teilzeichenfolgen von Zeichenfolgen abzurufen, ihre Verwendung ist jedoch unterschiedlich.
.substr(start,len)
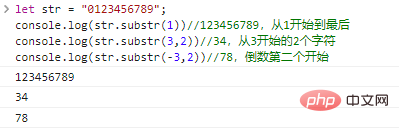
gibt eine Zeichenfolge zurück, die aus len -Zeichen besteht, beginnend mit start . Wenn len weggelassen wird, wird sie bis zum Ende der ursprünglichen Zeichenfolge abgefangen. start kann eine negative Zahl sein, die das start von hinten nach vorne angibt.
let str = "0123456789";console.log(str.substr(1))//123456789, beginnend mit 1 bis zum Ende console.log(str.substr(3,2))//34, 2 beginnend mit 3 Zeichen console.log(str.substr(-3,2))//78, das vorletzte Startcode
-Ausführungsergebnis:
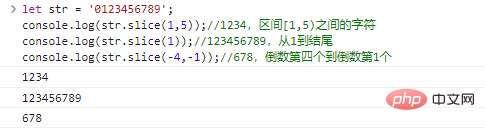
.slice(start,end)
gibt die Zeichenfolge zurück, die am start beginnt und am end endet (exklusiv). start und end können negative Zahlen sein, die die vorletzten start/end Endzeichen angeben.
let str = '0123456789';console.log(str.slice(1,5));//1234, Zeichen zwischen dem Intervall [1,5) console.log(str.slice(1));//123456789 , Von 1 bis zum Ende console.log(str.slice(-4,-1));//678, das viertletzte
Codeausführungsergebnis:
.substring(start,end)
ist fast die gleiche wie .slice() . Der Unterschied besteht an zwei Stellen:
end > start0beispielsweise als 0 betrachtet.
let str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3));//012, -1 wird als Make 0-
Codeausführungsergebnis behandelt:
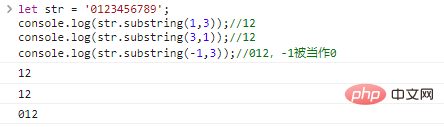
Vergleichen Sie die Unterschiede zwischen den drei:
| Methodenbeschreibungsparameter.slice | ( | start |
|---|---|---|
.slice(start,end) | [start,end) | kann negativ sein.substring |
.substring(start,end) | [start,end) | Der negative Wert 0 |
.substr(start,len) | Es gibt | viele |
für len, daher wird empfohlen, sich an
.slice()zu erinnern, das flexibler ist als die anderen beiden.
Wir haben den Vergleich von Zeichenfolgen bereits im vorherigen Artikel erwähnt. Hinter jedem Zeichen steht ein Code, und ASCII Code ist eine wichtige Referenz.
Zum Beispiel:
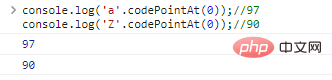
console.log('a'>'Z');// Der Vergleich zwischen echten Zeichen ist im Wesentlichen ein Vergleich zwischen Kodierungen, die Zeichen darstellen. JavaScript verwendet UTF-16 , um 16 zu kodieren. Wenn Sie die Art des Vergleichs wissen möchten, müssen Sie .codePointAt(idx) verwenden, um die Zeichenkodierung zu erhalten:
console.log('a '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 Code-Ausführungsergebnisse:
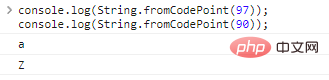
Verwenden Sie String.fromCodePoint(code) um die Codierung in Zeichen umzuwandeln:
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
Die Ergebnisse der Codeausführung sind wie folgt:
Dieser Vorgang kann mit dem Escape-Zeichen u wie folgt erreicht werden:
console.log('u005a');//Z, 005a ist die hexadezimale Notation von 90 console.log('u0061');//a, 0061 Es ist die hexadezimale Notation von 97. Lassen Sie uns die im Bereich [65,220] codierten Zeichen untersuchen:
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); Die Ergebnisse des Codeausführungsteils sind wie folgt:

Das Bild oben zeigt nicht alle Ergebnisse, probieren Sie es also einfach aus.
basiert auf dem internationalen Standard ECMA-402 . JavaScript hat eine spezielle Methode ( .localeCompare() ) implementiert, um verschiedene Zeichenfolgen mit str1.localeCompare(str2) zu vergleichen:
str1 < str2 , wird eine negative Zahl zurückgegebenstr1 > str2 , gib eine positive Zahl zurück;str1 == str2 , gib 0 zurück,zum Beispiel:
console.log("abc".localeCompare('def'));//-1 Warum nicht direkt Vergleichsoperatoren verwenden?
Dies liegt daran, dass es für englische Zeichen einige spezielle Schreibweisen gibt. Beispielsweise ist á eine Variante von a :
console.log('á' < 'z');// Obwohl false auch a ist, ist es größer als z ! !
Zu diesem Zeitpunkt müssen Sie .localeCompare() verwenden:
console.log('á'.localeCompare('z'));//-1 str.trim() entfernt Leerzeichen vor und nach dem string, str.trimStart() , str.trimEnd() löscht die Leerzeichen am Anfang und Ende;
let str = " 999 "; //999
str.repeat(n) Wiederholungen die Zeichenfolge n -mal;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) ersetzt die erste Teilzeichenfolge, str.replaceAll() wird verwendet, um alle zu ersetzen substrings;
let str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6ist immer noch Es gibt viele andere Methoden und wir können das Handbuch für mehr Wissen besuchen.
JavaScript verwendet UTF-16 65536 16 von Zeichenfolgen, d. h. zwei Bytes ( 16 Bit) werden zur Darstellung eines Zeichens verwendet Gebräuchliche Zeichen sind natürlich nicht enthalten, es reicht jedoch nicht für seltene Zeichen (Chinesisch), emoji , seltene mathematische Symbole usw.
In diesem Fall müssen Sie längere Ziffern ( 32 Bit) erweitern und verwenden, um Sonderzeichen darzustellen, zum Beispiel:
console.log(''.length);//2console.log('?'.length);//2 Code Ausführungsergebnis:
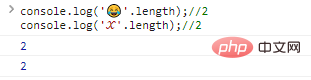
Das hat zur Folge, dass wir sie mit herkömmlichen Methoden nicht verarbeiten können. Was passiert, wenn wir jedes Byte einzeln ausgeben?
console.log(''[0]);console.log(''[1]); Ergebnisse der Codeausführung:
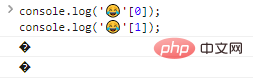
Wie Sie sehen, werden einzelne Ausgabebytes nicht erkannt.
Glücklicherweise können String.fromCodePoint() und .codePointAt() diese Situation bewältigen, da sie kürzlich hinzugefügt wurden. In älteren Versionen von JavaScript können Sie zum Konvertieren von Kodierungen und Zeichen nur String.fromCharCode() und .charCodeAt() verwenden, diese sind jedoch nicht für Sonderzeichen geeignet.
Wir können mit Sonderzeichen umgehen, indem wir den Codierungsbereich eines Zeichens beurteilen, um festzustellen, ob es sich um ein Sonderzeichen handelt. Wenn der Code eines Zeichens zwischen 0xd800~0xdbff liegt, dann ist es der erste Teil des 32 Bit-Zeichens und sein zweiter Teil sollte zwischen 0xdc00~0xdfff liegen.
Zum Beispiel:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02 Code-Ausführungsergebnis:

Im Englischen gibt es viele buchstabenbasierte Varianten, zum Beispiel: Der Buchstabe a kann das Grundzeichen von àáâäãåā sein. Nicht alle dieser Variantensymbole werden in UTF-16 -Kodierung gespeichert, da es zu viele Variationskombinationen gibt.
Um alle Variantenkombinationen zu unterstützen, werden auch mehrere Unicode Zeichen verwendet, um ein einzelnes Variantenzeichen darzustellen. Während des Programmiervorgangs können wir Basiszeichen plus „dekorative Symbole“ verwenden, um Sonderzeichen auszudrücken:
console.log('au0307 '. );//ȧ
console.log('au0308');//ȧ
console.log('au0309');//ȧ
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');// Ergebnisse der Codeausführung:
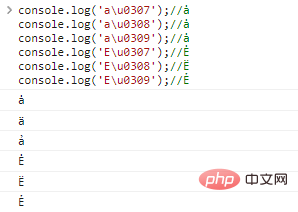
Ein einfacher Buchstabe kann auch mehrere Dekorationen haben, zum Beispiel:
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');// Ẹ̇Ergebnisse der Codeausführung:
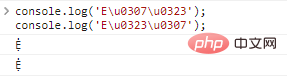
Hier besteht das Problem, dass die Dekorationen unterschiedlich angeordnet sind, die tatsächlich angezeigten Zeichen jedoch gleich sind.
Wenn wir diese beiden Darstellungen direkt vergleichen, erhalten wir das falsche Ergebnis:
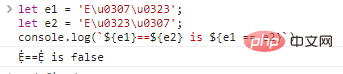
let e1 = 'Eu0307u0323';
sei e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`) Ergebnisse der Codeausführung:
Um diese Situation zu lösen, gibt es einen ** Unicode Normalisierungsalgorithmus, der die Zeichenfolge in ein universelles ** Format konvertieren kann , implementiert durch str.normalize() :
let e1 = 'Eu0307u0323';
sei e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} ist ${e1.normalize() == e2.normalize()}`)
Ergebnisse der Codeausführung:

[Verwandte Empfehlungen: JavaScript-Video-Tutorials, Web-Frontend]
Das Obige ist der detaillierte Inhalt der gängigen Grundmethoden von JavaScript-Strings. Weitere Informationen finden Sie in anderen verwandten Artikeln auf der chinesischen PHP-Website!