Wir haben im vorherigen Abschnitt alle Informationen der Webseite gecrawlt. Jetzt müssen wir den benötigten Inhalt im HTML-Code finden. Daher müssen wir die Website entsprechend dem Problem eingeben und die Informationen auf der Webseite analysieren.
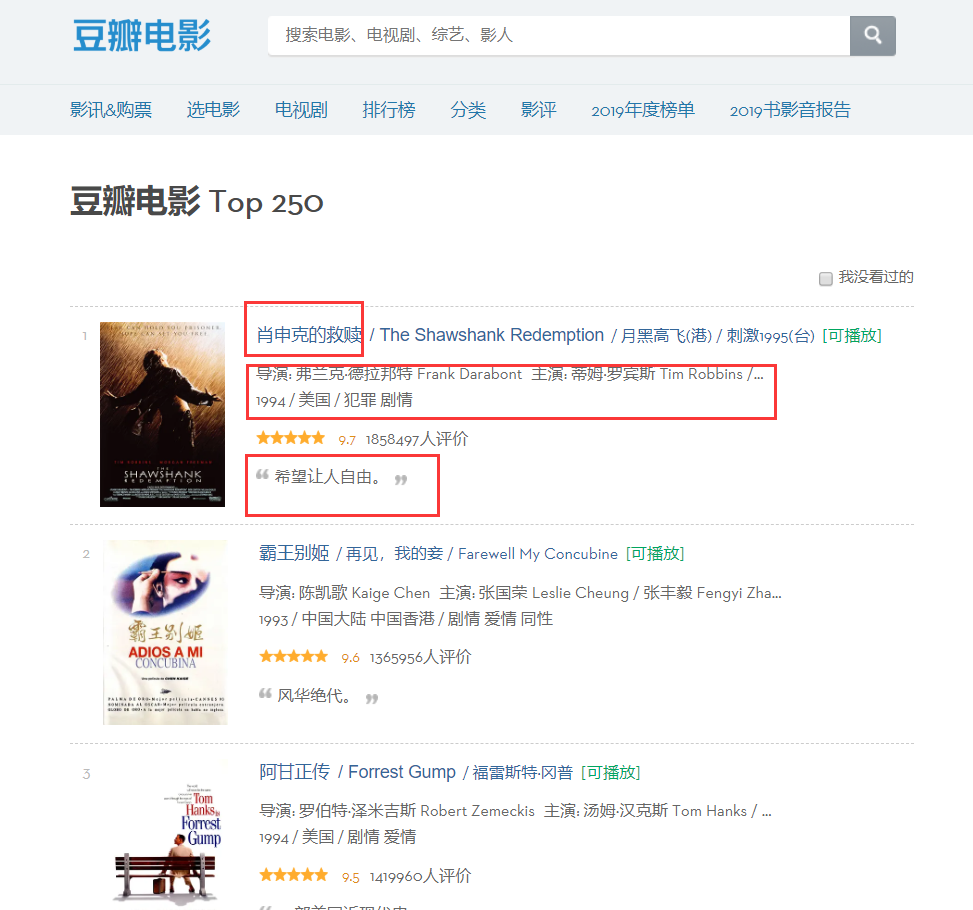
Auf der Seite können Sie feststellen, dass die Informationen, die wir crawlen müssen, in verschiedenen Partitionen vorhanden sind. Überprüfen Sie daher die Elemente der Seite. Klicken Sie mit der rechten Maustaste auf die Seite, um den Quellcode der Webseite zu überprüfen, oder drücken Sie F12.

Bevor wir die Webseite analysieren, geben wir nach dem Parsen zunächst die Speichermethode an. Hier verwenden wir eine Liste zum Speichern aller Informationen, und dann entspricht jedes Element in der Liste einem Wörterbuch, und jedes Wörterbuch entspricht mehreren Arten von Informationen.
movies=[]#Definieren Sie zunächst eine Liste zum Speichern aller Informationen
Durch Analyse können wir feststellen, dass die Position des Titels der erste „Span“ im ersten „a“ unter dem „div“ mit dem Namen „hd“ ist, sodass wir den Namen jedes Films über den folgenden Code sperren können in ein Wörterbuch.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#Ein Element im WörterbuchAuf die gleiche Weise kann der Quellcode des Namens des Regisseurs anhand der Positionierung gefunden werden. Dieser Quellcode enthält jedoch viele Informationen, sodass wir ihn durch reguläre Ausdrücke filtern müssen.
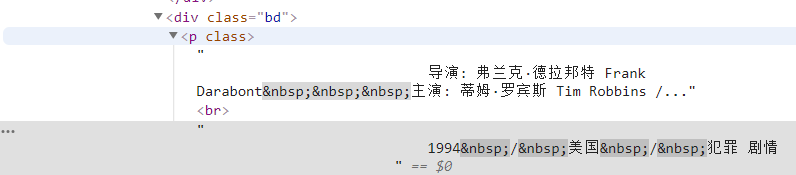
info=each.find('div',class_='bd').p.text.strip()Zuerst finden wir den gesamten Inhalt unter diesem Tag und filtern dann irrelevante Informationen mithilfe regulärer Ausdrücke heraus.
info=info.replace('n',)#Wagenrückläufe filtern info=info.replace(,)#Leerzeichen filtern info=info.replace(xa0,)#Geschützte Leerzeichen filtern Director=re.findall( r '[Regisseur:].+[Hauptdarsteller:]',info)[0]director=director[3:len(director)-6]Definieren Sie es dann als Element im Wörterbuch.
movie['director']=director#Ein Element im Wörterbuch
Wir können feststellen, dass sich der Filmtyp auch in diesem „p“-Tag befindet, und wir erhalten diese Informationen auch direkt über reguläre Ausdrücke.
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Als Element im Wörterbuch hinzufügenSperren Sie abschließend die Bewertungsinformationen.
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()Speichern Sie es dann weiterhin in Form eines Wörterbuchs.
movie['star']=star
Fügen Sie schließlich dieses Wörterbuch zur Liste hinzu und durchlaufen Sie die Ausgabe.
movies.append(movie)#Fügen Sie das Wörterbuch zur Liste hinzu füriinmovies:#Durchlaufen Sie die Ausgabe print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Simulate browser to access 'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537.36' , 'Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 mal r=requests.get(res,headers = headers,timeout=10)#Legen Sie die Zeitüberschreitung fest Suppe=BeautifulSoup(r.text,html.parser)#Legen Sie die Analysemethode fest, es können auch andere Methoden verwendet werden. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text.strip()movie['rank']=rankinfo=each.find('div', class_='bd').p.text.strip()info=info.replace('n',)info=info.replace(,)info=info.replace(xa0,)director=re.findall( r'[Regisseur:].+[Starring:]',info)[0]director=director[3:len(director)-6]movie['director']=directorrelease_date=re.findall(r'[0- 9]{4}',info)[0]movie['release_date']=release_dateplot=re.findall(r'[0-9]*[/].+[/].+',info)[0] plot=plot[1:]plot=plot[plot.index('/')+1:]plot=plot[plot.index('/')+1:]movie['plot']=plotstar=each. find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print (ich)Konsole:

In diesem Beispiel lernen wir hauptsächlich, wie BeautifulSoup uns dabei helfen kann, sie schnell zu finden und sie dann mit regulären Ausdrücken zu kombinieren, um den Abgleich der Informationen abzuschließen speichert diese Daten in der Datenbank.