Das neueste multimodale Sprachmodell BLIP-3-Video, das vom Salesforce AI-Forschungsteam veröffentlicht wurde, bietet eine Lösung für die effiziente Verarbeitung der wachsenden Videodaten. Dieses Modell zielt darauf ab, die Effizienz und Wirkung des Videoverständnisses zu verbessern. Es wird häufig in Bereichen wie autonomes Fahren und Unterhaltung eingesetzt und bringt Innovationen in alle Lebensbereiche. Der Herausgeber von Downcodes wird die Kerntechnologie und die hervorragende Leistung von BLIP-3-Video ausführlich erläutern.
Vor Kurzem hat das AI-Forschungsteam von Salesforce ein neues multimodales Sprachmodell auf den Markt gebracht: BLIP-3-Video. Mit der rasanten Zunahme von Videoinhalten ist die effiziente Verarbeitung von Videodaten zu einem dringend zu lösenden Problem geworden. Die Entstehung dieses Modells zielt darauf ab, die Effizienz und Effektivität des Videoverständnisses zu verbessern und eignet sich für verschiedene Branchen, vom autonomen Fahren bis zur Unterhaltung.
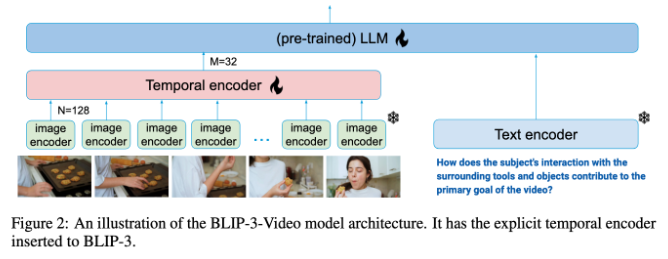
Herkömmliche Videoverständnismodelle verarbeiten Videos oft Bild für Bild und generieren eine große Menge an visuellen Informationen. Dieser Vorgang verbraucht nicht nur viele Rechenressourcen, sondern schränkt auch die Verarbeitung langer Videos erheblich ein. Da die Menge an Videodaten immer größer wird, wird dieser Ansatz immer ineffizienter. Daher ist es von entscheidender Bedeutung, eine Lösung zu finden, die die wichtigsten Informationen des Videos erfasst und gleichzeitig den Rechenaufwand reduziert.
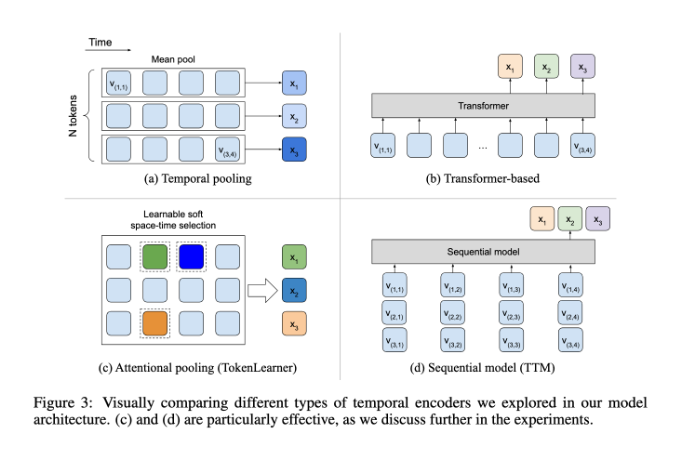
In dieser Hinsicht schneidet BLIP-3-Video recht gut ab. Dieses Modell reduziert erfolgreich die Menge der im Video erforderlichen visuellen Informationen auf 16 bis 32 visuelle Markierungen, indem es einen „zeitlichen Encoder“ einführt. Dieses innovative Design verbessert die Recheneffizienz erheblich und ermöglicht es dem Modell, komplexe Videoaufgaben zu geringeren Kosten auszuführen. Dieser zeitliche Encoder verwendet einen lernbaren raumzeitlichen Aufmerksamkeitspooling-Mechanismus, der die wichtigsten Informationen aus jedem Frame extrahiert und sie in einen kompakten Satz visueller Markierungen integriert.
Auch BLIP-3-Video schneidet sehr gut ab. Durch den Vergleich mit anderen groß angelegten Modellen ergab die Studie, dass die Genauigkeit dieses Modells bei Aufgaben zur Beantwortung von Videofragen mit der von Topmodellen vergleichbar ist. Beispielsweise benötigt das Tarsier-34B-Modell 4608 Marker, um 8 Videobilder zu verarbeiten, während BLIP-3-Video nur 32 Marker benötigt, um einen MSVD-QA-Benchmark-Score von 77,7 % zu erreichen. Dies zeigt, dass BLIP-3-Video den Ressourcenverbrauch erheblich reduziert und gleichzeitig eine hohe Leistung beibehält.
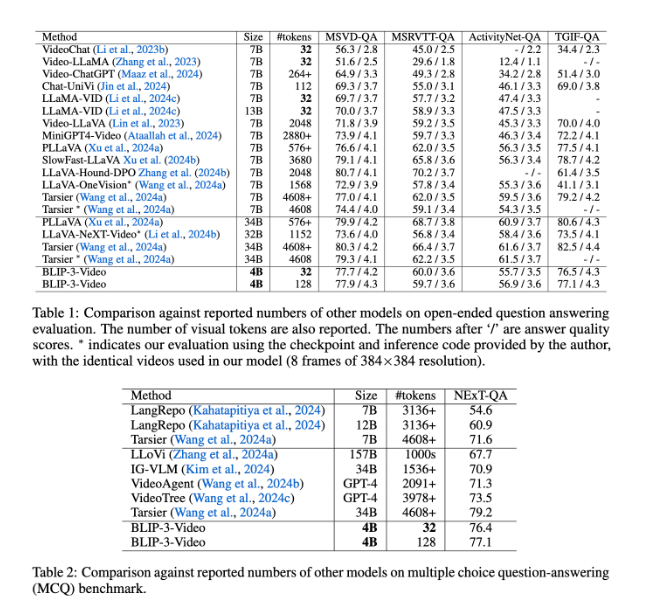
Darüber hinaus ist die Leistung von BLIP-3-Video bei Multiple-Choice-Frage- und Antwortaufgaben nicht zu unterschätzen. Im NExT-QA-Datensatz erreichte das Modell eine hohe Punktzahl von 77,1 % und im TGIF-QA-Datensatz erreichte es ebenfalls eine Genauigkeit von 77,1 %. Diese Daten belegen die Effizienz von BLIP-3-Video bei der Bewältigung komplexer Videoprobleme.

BLIP-3-Video eröffnet mit seinem innovativen Timing-Encoder neue Möglichkeiten in der Videoverarbeitung. Die Einführung dieses Modells verbessert nicht nur die Effizienz des Videoverständnisses, sondern bietet auch mehr Möglichkeiten für zukünftige Videoanwendungen.
Projekteingang: https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
BLIP-3-Video bietet mit seinen effizienten Videoverarbeitungsfunktionen eine neue Richtung für die zukünftige Entwicklung der Videotechnologie. Seine hervorragende Leistung bei Video-Frage-und-Antwort-Aufgaben und Multiple-Choice-Frage-und-Antwort-Aufgaben zeigt sein enormes Potenzial zur Ressourceneinsparung und Leistungsverbesserung. Wir freuen uns darauf, dass BLIP-3-Video in weiteren Bereichen eine Rolle spielt und den Fortschritt der Videotechnologie vorantreibt.