Das wissenschaftliche Forschungseffizienz-Artefakt OpenScholar wird veröffentlicht und verändert die Erfahrung der Literaturrecherche für wissenschaftliche Forscher völlig! Der Herausgeber von Downcodes bietet Ihnen dieses KI-gesteuerte wissenschaftliche Forschungstool. Es verfügt über 450 Millionen Open-Access-Artikel und 237 Millionen Artikeleinbettungen. Es kann schnell und genau Dokumente zu Ihren wissenschaftlichen Forschungsfragen herausfiltern und vollständige Antworten auf Referenzen generieren. OpenScholar ist nicht nur leistungsstark, es kann auch lernen und sich selbst verbessern, die Qualität der Antworten kontinuierlich verbessern und letztendlich die perfektesten wissenschaftlichen Forschungsergebnisse präsentieren. Es kann auch zum Trainieren kleinerer und effizienterer Modelle verwendet werden, was revolutionäre Veränderungen auf dem Gebiet der wissenschaftlichen Forschung mit sich bringt!
Bleiben Sie lange wach, um Literatur zu rezensieren? Keine Panik! Die wissenschaftlichen Forschungsexperten von AI2 sind hier, um Sie mit ihrem neuesten Meisterwerk OpenScholar zu retten! wie im Park spazieren gehen!
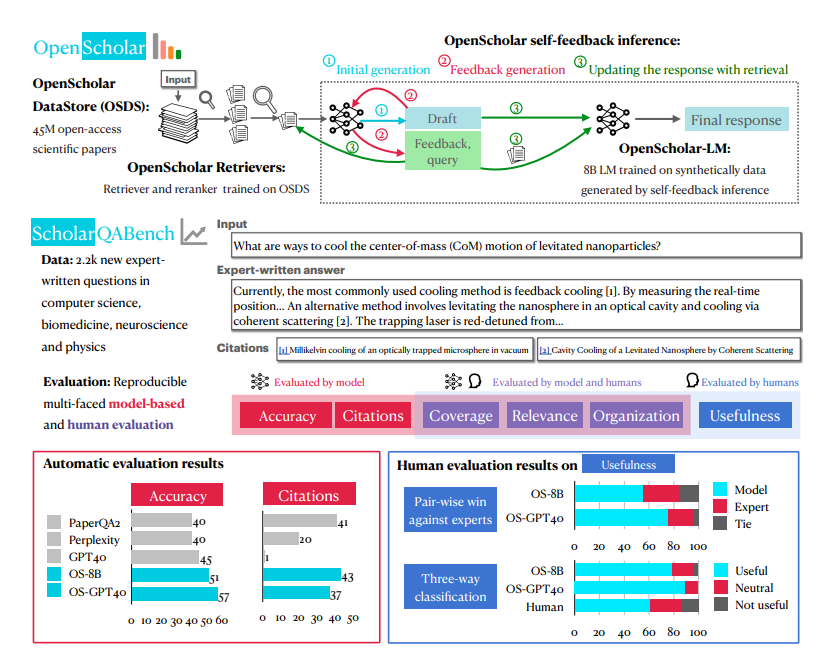
Die größte Geheimwaffe von OpenScholar ist ein System namens OpenScholar-Datastore (OSDS) mit 450 Millionen Open-Access-Artikeln und 237 Millionen eingebetteten Artikelabsätzen. Mit einer so starken Wissensbasis kann OpenScholar verschiedene wissenschaftliche Forschungsprobleme problemlos bewältigen.
Wenn Sie auf ein wissenschaftliches Forschungsproblem stoßen, sendet OpenScholar zunächst seine leistungsstarken Tools aus – den Such- und Nachsortierer, um die Artikelabsätze, die sich auf Ihr Problem beziehen, schnell aus OSDS herauszufiltern. Als nächstes enthält ein Sprachmodell (LM) die vollständige Antwort für die Referenz. Noch wirkungsvoller ist, dass OpenScholar die Antworten basierend auf Ihrem Feedback in natürlicher Sprache weiter verbessert und die fehlenden Informationen ergänzt, bis Sie zufrieden sind.
OpenScholar ist nicht nur allein leistungsstark, sondern kann auch dabei helfen, kleinere und effizientere Modelle zu trainieren. Die Forscher nutzten den Prozess von OpenScholar, um riesige Mengen hochwertiger Trainingsdaten zu generieren, und nutzten diese Daten, um ein Sprachmodell mit 8 Milliarden Parametern namens OpenScholar-8B sowie andere Abrufmodelle zu trainieren.
Um die Kampfwirksamkeit von OpenScholar umfassend zu testen, haben die Forscher außerdem eigens eine neue Testarena namens SCHOLARQABENCH geschaffen. In diesem Bereich werden verschiedene Aufgaben zur wissenschaftlichen Literaturrecherche durchgeführt, darunter geschlossene Klassifizierung, Multiple Choice und Langformgenerierung, die mehrere Bereiche wie Informatik, Biomedizin, Physik und Neurowissenschaften abdecken. Um die Fairness und Gerechtigkeit des Wettbewerbs sicherzustellen, nutzt SCHOLARQABENCH außerdem vielfältige Bewertungsmethoden, darunter Expertenbewertung, automatische Indikatoren und User Experience Tests.
Nach vielen Runden harter Konkurrenz stach OpenScholar endlich hervor! Experimentelle Ergebnisse zeigten, dass es bei verschiedenen Aufgaben gut abschnitt und sogar menschliche Experten übertraf. Dieses bahnbrechende Ergebnis wird sicherlich eine Revolution auf dem Gebiet der wissenschaftlichen Forschung auslösen und Wissenschaftler dazu bringen, sich zu verabschieden Arbeit der Literaturrecherche, die sich auf die Erforschung der Geheimnisse der Wissenschaft konzentriert!
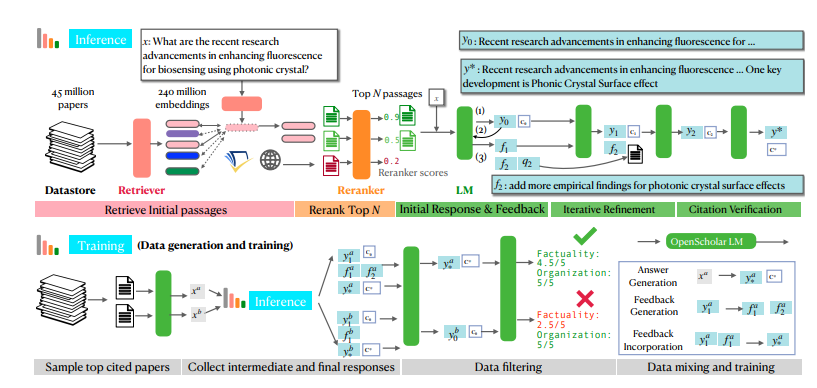
Die leistungsstarken Funktionen von OpenScholar profitieren vor allem von seinem einzigartigen verbesserten Argumentationsmechanismus zum Abrufen von Selbstfeedback. Vereinfacht ausgedrückt wird es sich zunächst selbst Fragen stellen, dann die Antworten basierend auf seinen eigenen Antworten kontinuierlich verbessern und Ihnen schließlich die perfekteste Antwort präsentieren. Ist es nicht erstaunlich?
Konkret ist der Selbst-Feedback-Begründungsprozess von OpenScholar in drei Schritte unterteilt: erste Antwortgenerierung, Feedback-Generierung und Feedback-Integration. Zunächst generiert das Sprachmodell eine erste Antwort auf Basis der abgerufenen Artikelpassagen. Dann wird es wie ein strenger Prüfer seine Antworten selbst kritisieren, Mängel identifizieren und ein Feedback in natürlicher Sprache generieren, wie zum Beispiel „Die Antwort enthält nur experimentelle Ergebnisse zu Frage- und Antwortaufgaben, bitte ergänzen Sie andere Arten von Aufgabenergebnissen.“ . Abschließend wird das Sprachmodell auf der Grundlage dieses Feedbacks die relevante Literatur erneut durchsuchen und alle Informationen integrieren, um eine vollständigere Antwort zu generieren.
Um kleinere, aber ebenso leistungsstarke Modelle zu trainieren, nutzten die Forscher auch den Selbstfeedback-Inferenzprozess von OpenScholar, um große Mengen hochwertiger Trainingsdaten zu generieren. Sie wählten zunächst die am häufigsten zitierten Artikel aus der Datenbank aus, generierten dann einige Informationsabfragefragen basierend auf den Zusammenfassungen dieser Artikel und nutzten schließlich den Inferenzprozess von OpenScholar, um qualitativ hochwertige Antworten zu generieren. Diese Antworten und die dabei generierten Feedback-Informationen stellen wertvolle Trainingsdaten dar. Die Forscher mischten diese Daten mit vorhandenen Daten zur Feinabstimmung allgemeiner Domänenanweisungen und Daten zur Feinabstimmung wissenschaftlicher Domänenanweisungen, um ein Sprachmodell mit 8 Milliarden Parametern namens OpenScholar-8B zu trainieren.
Um die Leistung von OpenScholar und anderen ähnlichen Modellen umfassender bewerten zu können, haben die Forscher außerdem einen neuen Benchmark namens SCHOLARQABENCH erstellt. Dieser Benchmark enthält 2.967 Fragen zur Literaturrecherche, die von Experten aus vier Bereichen verfasst wurden: Informatik, Physik, Biomedizin und Neurowissenschaften. Für jede Frage gibt es eine ausführliche Antwort, die von einem Experten verfasst wurde. Im Durchschnitt benötigt ein Experte für jede Antwort etwa eine Stunde. SCHOLARQABENCH verwendet außerdem einen vielschichtigen Bewertungsansatz, der automatisierte Metriken und manuelle Bewertungen kombiniert, um ein umfassenderes Maß für die Qualität der vom Modell generierten Antworten bereitzustellen.
Experimentelle Ergebnisse zeigen, dass die Leistung von OpenScholar auf SCHOLARQABENCH andere Modelle weit übertrifft und in einigen Aspekten sogar die von menschlichen Experten übertrifft. Im Bereich Informatik ist beispielsweise die korrekte Rate von OpenScholar-8B 5 % höher als die von GPT-4o, was 5 % höher ist! als der von GPT-4o ist 7 % höher. Darüber hinaus ist die Zitiergenauigkeit der von OpenScholar generierten Antworten mit der von menschlichen Experten vergleichbar, während GPT-4o zu 78–90 % aus dem Nichts erfunden wurde.
Das Aufkommen von OpenScholar ist zweifellos ein großer Segen für den Bereich der wissenschaftlichen Forschung. Es kann nicht nur wissenschaftlichen Forschern helfen, viel Zeit und Energie zu sparen, sondern auch die Qualität und Effizienz von Literaturrecherchen verbessern. Ich glaube, dass OpenScholar in naher Zukunft zu einem unverzichtbaren Assistenten für wissenschaftliche Forscher werden wird!
Papieradresse: https://arxiv.org/pdf/2411.14199
Projektadresse: https://github.com/AkariAsai/OpenScholar
Alles in allem hat OpenScholar mit seinen leistungsstarken Funktionen und seiner effizienten Leistung den wissenschaftlichen Forschern einen beispiellosen Komfort gebracht und die Effizienz der wissenschaftlichen Forschung erheblich verbessert. Es ist nicht nur ein Werkzeug, sondern auch eine Revolution auf dem Gebiet der wissenschaftlichen Forschung. Es lohnt sich, auf seine zukünftige Entwicklung und Anwendung zu blicken.