Der Herausgeber von Downcodes erklärt Ihnen die neuesten Forschungsergebnisse der Princeton University und der Yale University! Diese Forschung untersucht eingehend die Denkfähigkeiten der „Chain of Thought (CoT)“ großer Sprachmodelle (LLM) und zeigt, dass CoT-Argumentation keine einfache Anwendung logischer Regeln ist, sondern eine komplexe Verschmelzung mehrerer Faktoren wie Gedächtnis, Wahrscheinlichkeit und Lärmbegründung. Die Forscher wählten die Aufgabe zum Knacken von Shift-Chiffren und führten eine eingehende Analyse von drei LLMs durch: GPT-4, Claude3 und Llama3.1. Schließlich entdeckten sie drei Schlüsselfaktoren, die den CoT-Inferenzeffekt beeinflussen, und schlugen den Inferenzmechanismus von LLM vor. neue Erkenntnisse.
Forscher der Princeton University und der Yale University haben kürzlich einen Bericht über die Denkfähigkeiten der „Chain of Thought (CoT)“ großer Sprachmodelle (LLM) veröffentlicht und damit das Geheimnis des CoT-Denkens gelüftet: Es handelt sich nicht um rein symbolisches Denken, das auf logischen Regeln basiert, sondern Es kombiniert mehrere Faktoren wie Gedächtnis, Wahrscheinlichkeit und Rauschdenken.
Als Testaufgabe nutzten die Forscher das Knacken der Shift-Chiffre und analysierten die Leistung von drei LLMs: GPT-4, Claude3 und Llama3.1. Eine Schiebechiffre ist eine einfache Kodierung, bei der jeder Buchstabe durch einen Buchstaben ersetzt wird, der im Alphabet um eine festgelegte Anzahl von Stellen nach vorne verschoben wird. Verschieben Sie beispielsweise das Alphabet um drei Stellen nach vorne, und CAT wird zu FDW.
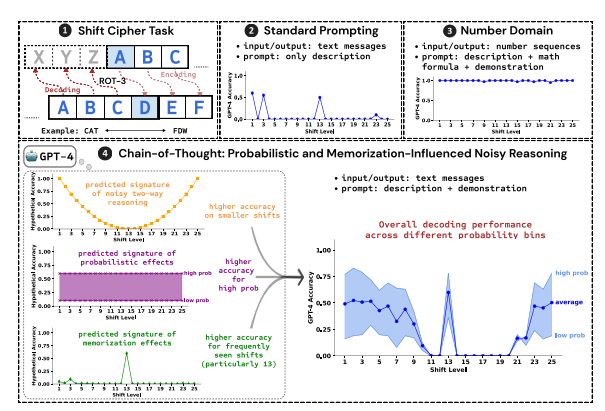
Die Forschungsergebnisse zeigen, dass die drei Schlüsselfaktoren, die den CoT-Argumentation-Effekt beeinflussen, folgende sind:
Probabilistisch: LLM bevorzugt die Generierung von Ausgaben mit höherer Wahrscheinlichkeit, auch wenn die Inferenzschritte zu Antworten mit geringerer Wahrscheinlichkeit führen. Wenn der Inferenzschritt beispielsweise auf STAZ verweist, STAY jedoch ein gebräuchlicheres Wort ist, führt LLM möglicherweise eine „Selbstkorrektur“ durch und gibt STAY aus.
Speicher: LLM merkt sich während des Vortrainings eine große Menge an Textdaten, was sich auf die Genauigkeit seiner CoT-Inferenz auswirkt. Beispielsweise ist Rot-13 die gebräuchlichste Schichtverschlüsselung, und die Genauigkeit von LLM auf Rot-13 ist deutlich höher als bei anderen Arten von Schichtverschlüsselungsmethoden.
Rauschinferenz: Der Inferenzprozess von LLM ist nicht ganz genau, es gibt jedoch ein gewisses Maß an Rauschen. Mit zunehmender Verschiebungsmenge der Verschiebungsverschlüsselung nehmen auch die für die Dekodierung erforderlichen Zwischenschritte zu, und die Auswirkungen der Rauschinferenz werden deutlicher, was dazu führt, dass die Genauigkeit von LLM abnimmt.
Die Forscher fanden außerdem heraus, dass die CoT-Argumentation von LLM auf Selbstkonditionierung beruht, das heißt, LLM muss explizit Text als Kontext für nachfolgende Argumentationsschritte generieren. Wenn der LLM angewiesen wird, „still zu denken“, ohne Text auszugeben, wird seine Denkfähigkeit erheblich eingeschränkt. Darüber hinaus hat die Wirksamkeit der Demonstrationsschritte nur geringe Auswirkungen auf die CoT-Argumentation. Selbst wenn es Fehler in den Demonstrationsschritten gibt, kann der CoT-Argumentationseffekt von LLM dennoch stabil bleiben.
Diese Studie zeigt, dass die CoT-Argumentation von LLM keine perfekte symbolische Argumentation ist, sondern mehrere Faktoren wie Gedächtnis, Wahrscheinlichkeit und Rauschdenken einbezieht. LLM zeigt die Eigenschaften sowohl eines Gedächtnismasters als auch eines Wahrscheinlichkeitsmasters während des CoT-Argumentationsprozesses. Diese Forschung hilft uns, ein tieferes Verständnis der Argumentationsfähigkeiten von LLM zu erlangen und liefert wertvolle Erkenntnisse für die Entwicklung leistungsfähigerer KI-Systeme in der Zukunft.
Papieradresse: https://arxiv.org/pdf/2407.01687
Dieser Forschungsbericht bietet uns eine wertvolle Referenz zum Verständnis des Argumentationsmechanismus der „Denkkette“ großer Sprachmodelle und bietet auch eine neue Richtung für den Entwurf und die Optimierung zukünftiger KI-Systeme. Der Herausgeber von Downcodes wird weiterhin auf die neuesten Entwicklungen im Bereich der künstlichen Intelligenz achten und Ihnen weitere spannende Inhalte bieten!