Das Forschungsteam des Computing Innovation Institute der Zhejiang-Universität hat einen Durchbruch bei der Lösung des Problems der unzureichenden Fähigkeit großer Sprachmodelle zur Verarbeitung tabellarischer Daten erzielt und ein neues Modell TableGPT2 auf den Markt gebracht. Mit seinem einzigartigen Tabellen-Encoder kann TableGPT2 verschiedene Tabellendaten effizient verarbeiten und so revolutionäre Veränderungen für datengesteuerte Anwendungen wie Business Intelligence (BI) mit sich bringen. Der Herausgeber von Downcodes wird die Innovation und zukünftige Entwicklungsrichtung von TableGPT2 ausführlich erläutern.
Der Aufstieg großer Sprachmodelle (LLMs) hat revolutionäre Veränderungen bei Anwendungen der künstlichen Intelligenz mit sich gebracht. Sie weisen jedoch offensichtliche Mängel bei der Verarbeitung tabellarischer Daten auf. Um dieses Problem anzugehen, hat ein Forschungsteam des Computing Innovation Institute der Zhejiang-Universität ein neues Modell namens TableGPT2 auf den Markt gebracht, das tabellarische Daten direkt und effizient integrieren und verarbeiten kann und so neue Wege für Business Intelligence (BI) und andere datengesteuerte Anwendungen eröffnet Anwendungen. Neue Möglichkeiten.
Die Kerninnovation von TableGPT2 liegt in seinem einzigartigen Tabellenencoder, der speziell für die Erfassung der Strukturinformationen und Zellinhaltsinformationen der Tabelle entwickelt wurde und dadurch die Fähigkeit des Modells verbessert, Fuzzy-Abfragen, fehlende Spaltennamen und unregelmäßige Tabellen zu verarbeiten, die in der Realität häufig vorkommen -Weltanwendungen. TableGPT2 basiert auf der Qwen2.5-Architektur und wurde einer umfangreichen Vorschulung und Feinabstimmung unterzogen, die mehr als 593.800 Tabellen und 2,36 Millionen hochwertige Abfragetabellen-Ausgabetupel umfasst, was ein beispielloses Ausmaß an Tabellenbezügen darstellt Daten in früheren Untersuchungen.
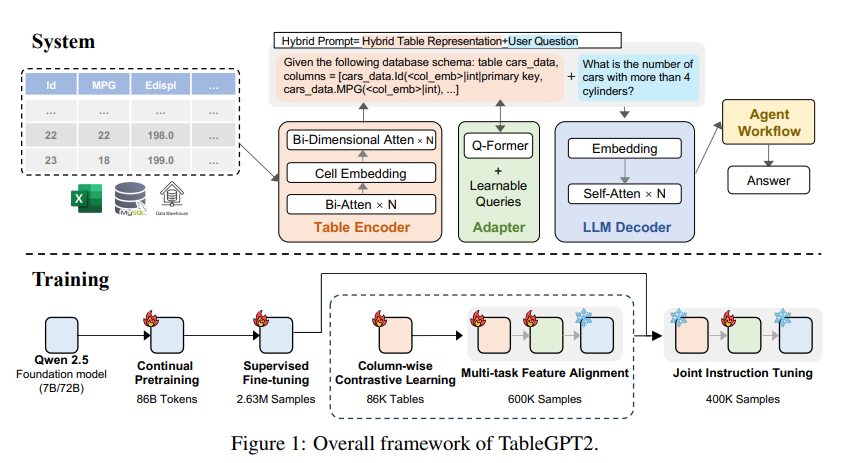
Um die Codierungs- und Argumentationsfunktionen von TableGPT2 zu verbessern, führten die Forscher ein kontinuierliches Pre-Training (CPT) durch, bei dem 80 % der Daten sorgfältig annotierter Code sind, um sicherzustellen, dass sie über starke Codierungsfunktionen verfügen. Darüber hinaus sammelten sie eine große Menge an Inferenzdaten und Lehrbüchern mit domänenspezifischem Wissen, um die Inferenzfähigkeiten des Modells zu verbessern. Die endgültigen CPT-Daten enthalten 86 Milliarden streng gefilterte Token, die TableGPT2 die erforderlichen Codierungs- und Argumentationsfunktionen zur Bewältigung komplexer BI-Aufgaben und anderer damit zusammenhängender Aufgaben bereitstellen.
Um die Einschränkungen von TableGPT2 bei der Anpassung an bestimmte BI-Aufgaben und -Szenarien zu beseitigen, führten die Forscher eine überwachte Feinabstimmung (Supervised Fine Tuning, SFT) durch. Sie erstellten einen Datensatz, der eine Vielzahl kritischer und realer Szenarien abdeckte, darunter mehrere Gesprächsrunden, komplexe Argumentation, Werkzeugnutzung und stark geschäftsorientierte Abfragen. Der Datensatz kombiniert manuelle Annotation mit einem von Experten gesteuerten automatisierten Annotationsprozess, um die Qualität und Relevanz der Daten sicherzustellen. Der SFT-Prozess unter Verwendung von insgesamt 2,36 Millionen Beispielen verfeinerte das Modell weiter, um den spezifischen Anforderungen von BI und anderen Umgebungen mit Tabellen gerecht zu werden.
TableGPT2 führt außerdem auf innovative Weise einen semantischen Tabellenencoder ein, der die gesamte Tabelle als Eingabe verwendet und einen kompakten Satz von Einbettungsvektoren für jede Spalte generiert. Diese Architektur ist an die einzigartigen Eigenschaften tabellarischer Daten angepasst und erfasst effektiv die Beziehungen zwischen Zeilen und Spalten durch einen bidirektionalen Aufmerksamkeitsmechanismus und einen hierarchischen Merkmalsextraktionsprozess. Darüber hinaus wird eine säulenkontrastive Lernmethode angewendet, um das Modell zum Erlernen sinnvoller, strukturbewusster tabellarischer semantischer Darstellungen zu ermutigen.
Um TableGPT2 nahtlos in Datenanalysetools auf Unternehmensebene zu integrieren, haben die Forscher außerdem ein Agent-Workflow-Laufzeit-Framework entwickelt. Das Framework besteht aus drei Kernkomponenten: Laufzeithinweis-Engineering, sicherer Code-Sandbox und Agentenbewertungsmodul, die zusammen die Fähigkeiten und Zuverlässigkeit des Agenten verbessern. Workflows unterstützen komplexe Datenanalyseaufgaben durch modulare Schritte (Eingabenormalisierung, Agentenausführung und Toolaufruf), die zusammenarbeiten, um die Agentenleistung zu verwalten und zu überwachen. Durch die Integration von Retrieval Augmented Generation (RAG) für einen effizienten kontextbezogenen Abruf und Code-Sandboxing für eine sichere Ausführung stellt das Framework sicher, dass TableGPT2 genaue, kontextsensitive Einblicke in reale Probleme liefert.
Die Forscher führten eine umfassende Bewertung von TableGPT2 anhand einer Vielzahl weit verbreiteter Tabellen- und Allzweck-Benchmarks durch. Die Ergebnisse zeigen, dass TableGPT2 beim Tabellenverständnis, der Verarbeitung und dem Denken eine durchschnittliche Leistungsverbesserung von 35,20 % für ein 7-Milliarden-Parameter-Modell aufweist Die durchschnittliche Leistung des 100-Millionen-Parameter-Modells stieg um 49,32 %, während die allgemeine Leistung weiterhin stark blieb. Für eine faire Bewertung verglichen sie TableGPT2 nur mit Benchmark-neutralen Open-Source-Modellen wie Qwen und DeepSeek, um eine ausgewogene, vielseitige Leistung des Modells bei einer Vielzahl von Aufgaben zu gewährleisten, ohne dass ein einzelner Benchmark-Test übermäßig angepasst wurde. Sie haben außerdem einen neuen Benchmark, RealTabBench, eingeführt und teilweise veröffentlicht, der den Schwerpunkt auf unkonventionelle Tabellen, anonyme Felder und komplexe Abfragen legt, um eine bessere Übereinstimmung mit realen Szenarien zu gewährleisten.
Obwohl TableGPT2 in Experimenten eine Leistung auf dem neuesten Stand erreicht, bestehen bei der Bereitstellung von LLM in realen BI-Umgebungen immer noch Herausforderungen. Die Forscher stellten fest, dass zukünftige Forschungsrichtungen Folgendes umfassen:
Domänenspezifische Codierung: Ermöglicht LLM die schnelle Anpassung unternehmensspezifischer domänenspezifischer Sprachen (DSLs) oder Pseudocodes, um den spezifischen Anforderungen der Unternehmensdateninfrastruktur besser gerecht zu werden.
Multi-Agent-Design: Entdecken Sie, wie Sie mehrere LLMs effektiv in ein einheitliches System integrieren können, um die Komplexität realer Anwendungen zu bewältigen.
Vielseitige Tabellenverarbeitung: Verbessern Sie die Fähigkeit des Modells, unregelmäßige Tabellen wie zusammengeführte Zellen und inkonsistente Strukturen, die in Excel und Pages häufig vorkommen, zu verarbeiten, um verschiedene Formen tabellarischer Daten in der realen Welt besser verarbeiten zu können.
Die Einführung von TableGPT2 markiert den bedeutenden Fortschritt von LLM bei der Verarbeitung tabellarischer Daten und eröffnet neue Möglichkeiten für Business Intelligence und andere datengesteuerte Anwendungen. Ich glaube, dass TableGPT2 im Zuge der weiteren Vertiefung der Forschung in Zukunft eine immer wichtigere Rolle im Bereich der Datenanalyse spielen wird.
Papieradresse: https://arxiv.org/pdf/2411.02059v1
Das Aufkommen von TableGPT2 hat einen neuen Aufbruch in den Bereich der Business Intelligence gebracht. Seine effizienten Tabellendatenverarbeitungsfunktionen und seine starke Skalierbarkeit deuten darauf hin, dass die Datenanalyse in Zukunft intelligenter und komfortabler sein wird. Wir freuen uns darauf, dass TableGPT2 in Zukunft häufiger eingesetzt wird und allen Lebensbereichen einen Mehrwert bietet.