Der Herausgeber von Downcodes erfuhr, dass das chinesische Forschungsteam erfolgreich den größten öffentlichen multimodalen KI-Datensatz „Infinity-MM“ erstellt und auf der Grundlage dieses Datensatzes ein kleines Modell Aquila-VL-2B mit hervorragender Leistung trainiert hat. Das Modell erzielte in mehreren Benchmark-Tests hervorragende Ergebnisse und demonstrierte das enorme Potenzial synthetischer Daten zur Verbesserung der Leistung von KI-Modellen. Der Infinity-MM-Datensatz enthält verschiedene Arten von Daten wie Bildbeschreibungen und visuelle Anleitungsdaten. Sein Generierungsprozess nutzt Open-Source-KI-Modelle wie RAM++ und MiniCPM-V und wird einer mehrstufigen Verarbeitung unterzogen, um Datenqualität und -vielfalt sicherzustellen. Das Aquila-VL-2B-Modell basiert auf der LLaVA-OneVision-Architektur und verwendet Qwen-2.5 als Sprachmodell.
Kürzlich haben Forschungsteams mehrerer chinesischer Institutionen erfolgreich den „Infinity-MM“-Datensatz erstellt, der derzeit einer der größten öffentlichen multimodalen KI-Datensätze ist, und ein kleines neues Modell mit hervorragender Leistung trainiert – Aquila-VL-2B .
Der Datensatz enthält hauptsächlich vier Hauptdatenkategorien: 10 Millionen Bildbeschreibungen, 24,4 Millionen allgemeine visuelle Anleitungsdaten, 6 Millionen ausgewählte hochwertige Anleitungsdaten und 3 Millionen von GPT-4 und anderen KI-Modellen generierte Daten.
Auf der Generierungsseite nutzte das Forschungsteam bestehende Open-Source-KI-Modelle. Zunächst analysiert das RAM++-Modell das Bild, extrahiert wichtige Informationen und generiert anschließend relevante Fragen und Antworten. Darüber hinaus baute das Team ein spezielles Klassifizierungssystem auf, um die Qualität und Vielfalt der generierten Daten sicherzustellen.
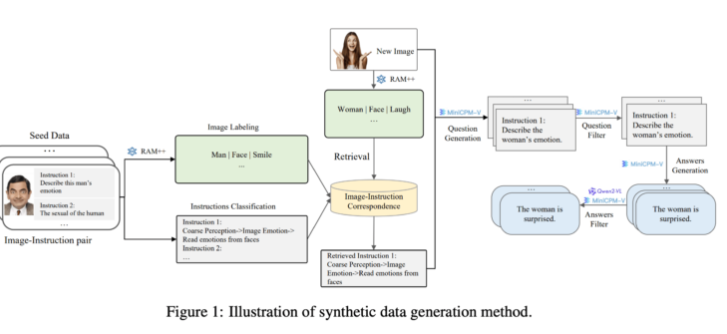
Diese Methode zur Generierung synthetischer Daten verwendet eine mehrstufige Verarbeitungsmethode, die RAM++- und MiniCPM-V-Modelle kombiniert, um durch Bilderkennung, Befehlsklassifizierung und Antwortgenerierung genaue Trainingsdaten für das KI-System bereitzustellen.
Das Aquila-VL-2B-Modell basiert auf der LLaVA-OneVision-Architektur, verwendet Qwen-2.5 als Sprachmodell und nutzt SigLIP für die Bildverarbeitung. Das Training des Modells ist in vier Phasen unterteilt, wodurch die Komplexität schrittweise erhöht wird. In der ersten Phase lernt das Modell grundlegende Bild-Text-Assoziationen; in den folgenden Phasen werden allgemeine Sehaufgaben, die Ausführung spezifischer Anweisungen und schließlich die Integration synthetisierter generierter Daten durchgeführt. Auch die Bildauflösung wird im Laufe des Trainings sukzessive verbessert.
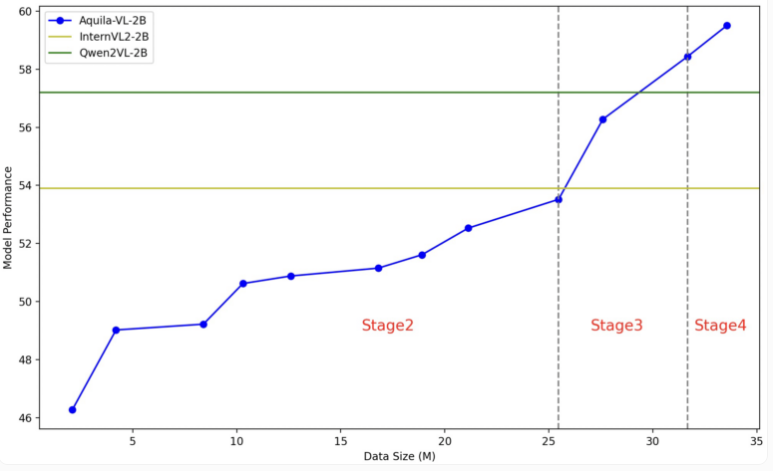
Im Test erreichte Aquila-VL-2B im multimodalen MMStar-basierten Test mit einem Score von 54,9 % das beste Ergebnis, bei einem Volumen von nur 2 Milliarden Parametern. Darüber hinaus schnitt das Modell bei mathematischen Aufgaben besonders gut ab und erreichte im MathVista-Test 59 % und übertraf damit ähnliche Systeme bei weitem.
Auch im allgemeinen Bildverständnistest schnitt Aquila-VL-2B mit einem HallusionBench-Score von 43 % und einem MMBench-Score von 75,2 % gut ab. Die Forscher sagten, dass die Hinzufügung synthetisch generierter Daten die Leistung des Modells erheblich verbessert hätte. Ohne die Verwendung dieser zusätzlichen Daten wäre die durchschnittliche Leistung des Modells um 2,4 % gesunken.
Diesmal beschloss das Forschungsteam, den Datensatz und das Modell der Forschungsgemeinschaft zugänglich zu machen. Der Trainingsprozess nutzte hauptsächlich Nvidia A100GPU und chinesische lokale Chips. Der erfolgreiche Start von Aquila-VL-2B zeigt, dass Open-Source-Modelle in der KI-Forschung allmählich mit dem Trend traditioneller Closed-Source-Systeme gleichziehen und insbesondere bei der Nutzung synthetischer Trainingsdaten gute Aussichten bieten.
Zugang zum Infinity-MM-Papier: https://arxiv.org/abs/2410.18558
Aquila-VL-2B-Projekteingang: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
Der Erfolg von Aquila-VL-2B beweist nicht nur Chinas technische Stärke im Bereich KI, sondern stellt auch wertvolle Ressourcen für die Open-Source-Community bereit. Seine effiziente Leistung und offene Strategie werden die Entwicklung multimodaler KI-Technologie vorantreiben, und es lohnt sich, auf seine zukünftigen Anwendungen in weiteren Bereichen gespannt zu sein.