Eine neue MIT-Studie hat bemerkenswerte Ähnlichkeiten zwischen der internen Struktur großer Sprachmodelle (LLMs) und dem menschlichen Gehirn aufgedeckt und eine hitzige Debatte auf dem Gebiet der künstlichen Intelligenz ausgelöst. Der Herausgeber von Downcodes wird die bahnbrechenden Ergebnisse dieser Forschung und ihre Bedeutung für die zukünftige Entwicklung der KI ausführlich erläutern. Durch eine eingehende Analyse des LLM-Aktivierungsraums entdeckten die Forscher dreistufige Strukturmerkmale. Die Entdeckung dieser Merkmale wird uns helfen, den Funktionsmechanismus von LLM besser zu verstehen und neue Richtungen für die Entwicklung zukünftiger KI-Technologie aufzuzeigen.
KI hat tatsächlich damit begonnen, „ein Gehirn wachsen zu lassen“?! Die neueste Forschung des MIT zeigt, dass die interne Struktur eines großen Sprachmodells (LLM) dem menschlichen Gehirn überraschend ähnlich ist!
Diese Studie führte mithilfe der Sparse-Autoencoder-Technologie eine eingehende Analyse des Aktivierungsraums von LLM durch und entdeckte drei Ebenen struktureller Merkmale, die erstaunlich sind:
Zunächst entdeckten die Forscher auf mikroskopischer Ebene die Existenz „kristalliner“ Strukturen. Die Gesichter dieser „Kristalle“ bestehen aus Parallelogrammen oder Trapezen, ähnlich bekannten Wortanalogien wie „Mann:Frau::König:Königin“.

Noch überraschender ist, dass diese „kristallinen“ Strukturen klarer werden, nachdem einige irrelevante Störfaktoren (wie die Wortlänge) durch lineare Diskriminanzanalysetechniken entfernt wurden.
Zweitens fanden Forscher auf der Mesoebene heraus, dass der Aktivierungsraum von LLM eine modulare Struktur aufweist, die den funktionellen Abteilungen des menschlichen Gehirns ähnelt.
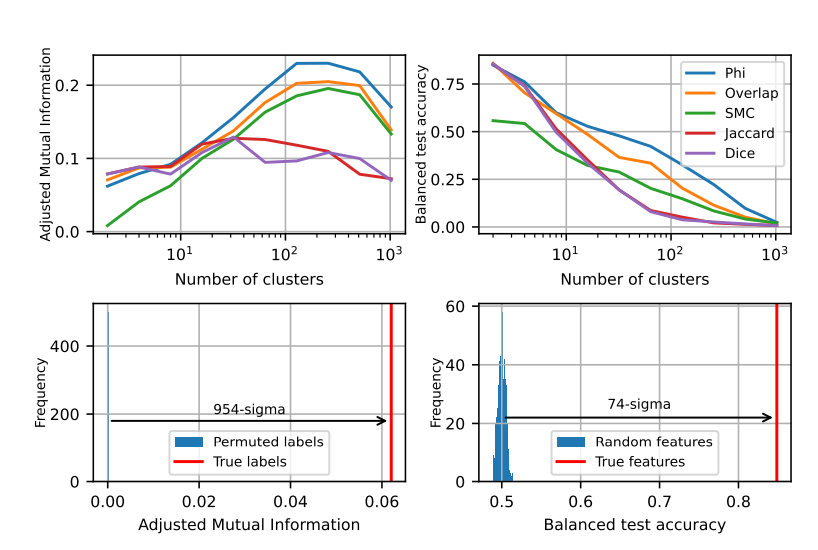
Beispielsweise gruppieren sich Funktionen im Zusammenhang mit Mathematik und Codierung zu einem „Lappen“, der den Funktionslappen des menschlichen Gehirns ähnelt. Durch die quantitative Analyse mehrerer Indikatoren bestätigten die Forscher die räumliche Lokalität dieser „Lappen“ und zeigten, dass gleichzeitig auftretende Merkmale auch räumlich stärker gebündelt sind, weit über das hinaus, was man von einer zufälligen Verteilung erwarten würde.
Auf der Makroebene stellten die Forscher fest, dass die Gesamtstruktur der LLM-Merkmalspunktwolke nicht isotrop ist, sondern eine Potenzgesetz-Eigenwertverteilung aufweist, und diese Verteilung ist in der mittleren Schicht am deutlichsten.
Die Forscher analysierten auch quantitativ die Clustering-Entropie verschiedener Ebenen und stellten fest, dass die Clustering-Entropie der mittleren Schicht niedriger war, was darauf hindeutet, dass die Merkmalsdarstellung konzentrierter war, während die Clustering-Entropie der frühen und späten Schichten höher war, was darauf hindeutet, dass die Feature-Repräsentation konzentrierter war Die Vertretung war stärker verstreut.
Diese Forschung bietet uns eine neue Perspektive zum Verständnis der internen Mechanismen großer Sprachmodelle und legt auch den Grundstein für die Entwicklung leistungsfähigerer und intelligenterer KI-Systeme in der Zukunft.
Dieses Forschungsergebnis ist spannend und vertieft nicht nur unser Verständnis von groß angelegten Sprachmodellen, sondern weist auch eine neue Richtung für die zukünftige Entwicklung der künstlichen Intelligenz auf. Der Herausgeber von Downcodes glaubt, dass die künstliche Intelligenz mit der kontinuierlichen Weiterentwicklung der Technologie ihr starkes Potenzial in mehr Bereichen zeigen und der menschlichen Gesellschaft eine bessere Zukunft bescheren wird.