Das Verständnis extrem langer Videos war schon immer ein schwieriges Problem für multimodale große Sprachmodelle (MLLM). Bestehende Modelle sind schwierig, Videodaten zu verarbeiten, die die maximale Kontextlänge überschreiten, und Informationsdämpfung und hohe Rechenkosten stellen ebenfalls eine große Herausforderung dar. Der Herausgeber von Downcodes erfuhr, dass das Zhiyuan Research Institute und mehrere Universitäten ein ultralanges visuelles Sprachmodell namens Video-XL vorgeschlagen haben, das darauf ausgelegt ist, Probleme beim Verstehen von Videos auf Stundenebene effizient zu lösen. Die Kerntechnologie dieses Modells ist die „Latente Zusammenfassung des visuellen Kontexts“, die die Kontextmodellierungsfunktionen von LLM geschickt nutzt, um lange visuelle Darstellungen in eine kompaktere Form zu komprimieren, ähnlich wie das Zusammenfassen einer ganzen Kuh in einer Schüssel mit Rindfleischessenz, wodurch das Modell erstellt wird effizienter. Nehmen Sie wichtige Informationen auf.
Derzeit haben multimodale große Sprachmodelle (MLLM) erhebliche Fortschritte im Bereich des Videoverständnisses gemacht, aber die Verarbeitung extrem langer Videos ist immer noch eine Herausforderung. Dies liegt daran, dass MLLM in der Regel Schwierigkeiten hat, Tausende von visuellen Tokens zu verarbeiten, die die maximale Kontextlänge überschreiten, und dass es durch die Token-Aggregation zu einem Informationsverlust kommt. Gleichzeitig verursacht eine große Anzahl an Video-Tags auch einen hohen Rechenaufwand.
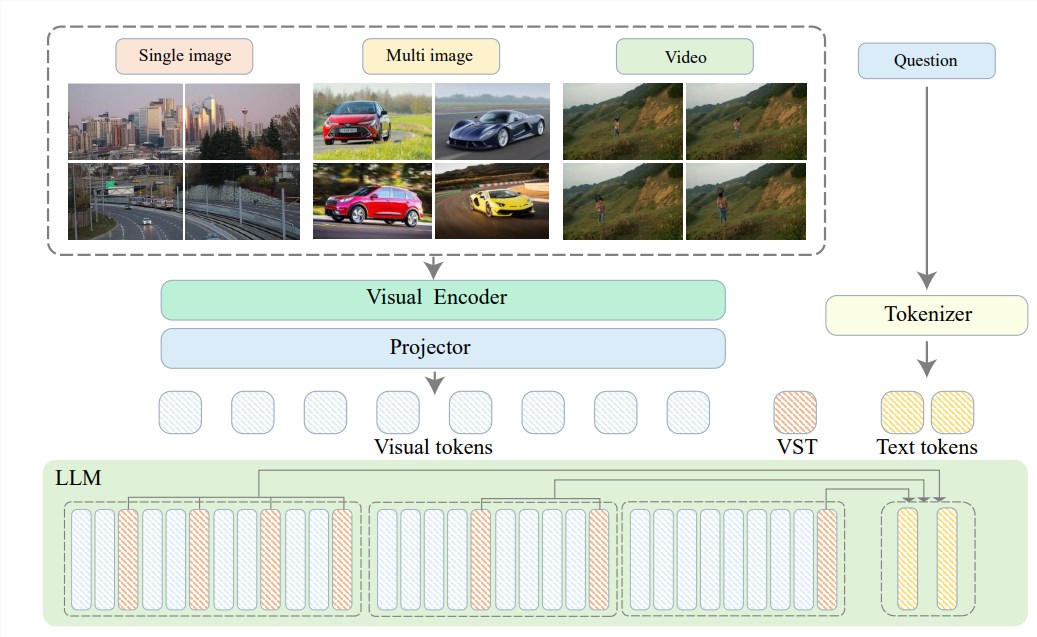
Um diese Probleme zu lösen, hat das Zhiyuan Research Institute gemeinsam mit der Shanghai Jiao Tong University, der Renmin University of China, der Peking University, der Beijing University of Posts and Telecommunications und anderen Universitäten Video-XL vorgeschlagen, ein Ultra-High-Definition-System für Effizientes Videoverständnis auf Stundenebene. Der Kern von Video-XL liegt in der „Visual Context Latent Summarization“-Technologie, die die inhärenten Kontextmodellierungsfunktionen von LLM nutzt, um lange visuelle Darstellungen effektiv in eine kompaktere Form zu komprimieren.
Vereinfacht ausgedrückt geht es darum, den Videoinhalt in eine schlankere Form zu komprimieren, genau wie das Kondensieren einer ganzen Kuh in einer Schüssel mit Rindfleischessenz, was für das Modell leichter zu verdauen und aufzunehmen ist.
Diese Komprimierungstechnologie verbessert nicht nur die Effizienz, sondern bewahrt auch effektiv die wichtigsten Informationen des Videos. Wissen Sie, lange Videos sind oft mit vielen überflüssigen Informationen gefüllt, wie das Fußtuch einer alten Dame, lang und stinkend. Video-XL kann diese nutzlosen Informationen präzise eliminieren und nur die wesentlichen Teile beibehalten, wodurch sichergestellt wird, dass das Modell beim Verständnis langer Videoinhalte nicht den Überblick verliert.
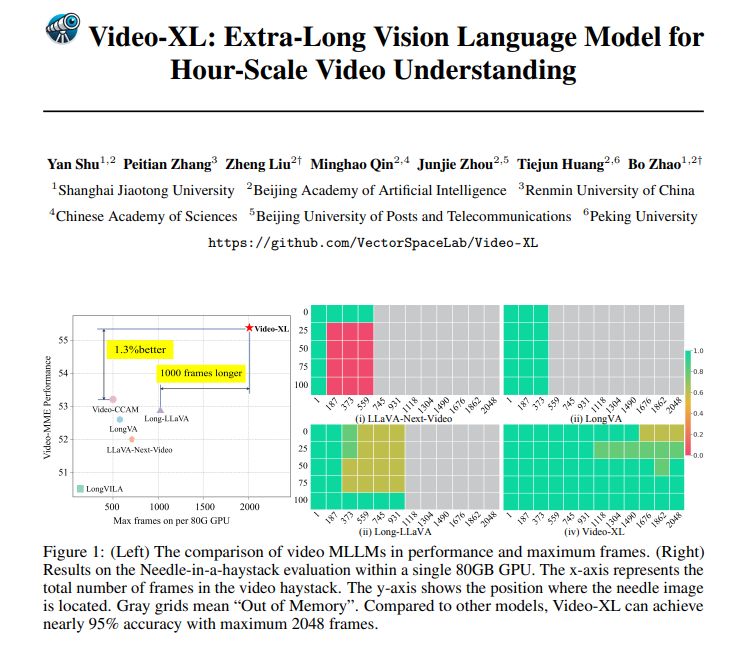
Video-XL ist nicht nur theoretisch großartig, sondern auch in der Praxis durchaus leistungsfähig. Video-XL hat in mehreren Benchmarks zum Verstehen langer Videos führende Ergebnisse erzielt, insbesondere im VNBench-Test, wo seine Genauigkeit fast 10 % höher ist als die der besten vorhandenen Methoden.
Noch beeindruckender ist, dass Video-XL ein erstaunliches Gleichgewicht zwischen Effizienz und Effektivität schafft und 2048 Videobilder auf einer einzigen 80-GB-GPU verarbeiten kann, während die Genauigkeit der „Nadel im Heuhaufen“-Bewertung immer noch bei nahezu 95 % liegt.
Auch Video-XL hat breite Anwendungsaussichten. Es ist nicht nur in der Lage, allgemeine lange Videos zu verstehen, sondern auch spezifische Aufgaben wie die Zusammenfassung von Filmen, die Erkennung von Überwachungsanomalien und die Erkennung von Werbeplatzierungen.
Dies bedeutet, dass Sie beim Ansehen von Filmen in Zukunft keine langen Handlungsstränge mehr ertragen müssen. Sie können Video-XL direkt verwenden, um eine optimierte Zusammenfassung zu erstellen, was Zeit und Aufwand spart, oder Sie können es zur Überwachung von Überwachungsaufnahmen und zur automatischen Identifizierung ungewöhnlicher Ereignisse verwenden , was viel effizienter ist als die manuelle Nachverfolgung.
Projektadresse: https://github.com/VectorSpaceLab/Video-XL
Papier: https://arxiv.org/pdf/2409.14485
Video-XL hat bahnbrechende Fortschritte auf dem Gebiet der Verarbeitung ultralanger Videos gemacht und bietet eine neue Lösung für die Verarbeitung langer Videos, auf die es sich zu freuen lohnt.