Das Training großer Modelle ist zeitaufwändig und arbeitsintensiv. Die Verbesserung der Effizienz und die Reduzierung des Energieverbrauchs sind zu einem zentralen Thema im KI-Bereich geworden. AdamW ist als Standardoptimierer für das Transformer-Vortraining nach und nach nicht mehr in der Lage, mit immer größeren Modellen zurechtzukommen. Der Herausgeber von Downcodes stellt Ihnen einen neuen Optimierer vor, der von einem chinesischen Team entwickelt wurde – C-AdamW. Mit seiner „vorsichtigen“ Strategie reduziert er den Energieverbrauch erheblich und sorgt gleichzeitig für Trainingsgeschwindigkeit und -stabilität und bringt große Vorteile für das Training großer Modelle . Um den Wandel zu revolutionieren.
In der Welt der KI scheint es die goldene Regel zu sein, hart zu arbeiten, um Wunder zu erreichen. Je größer das Modell, je mehr Daten und je stärker die Rechenleistung, desto näher scheint es dem Heiligen Gral der Intelligenz zu sein. Allerdings steht hinter dieser rasanten Entwicklung auch ein enormer Druck auf Kosten und Energieverbrauch.
Um das KI-Training effizienter zu gestalten, haben Wissenschaftler nach leistungsfähigeren Optimierern wie einem Coach gesucht, der die Parameter des Modells so steuert, dass es kontinuierlich optimiert und letztendlich den besten Zustand erreicht. AdamW ist als Standardoptimierer für das Transformer-Vortraining seit vielen Jahren der Branchenmaßstab. Angesichts des immer größeren Modellmaßstabs schien AdamW seinen Fähigkeiten jedoch auch nicht mehr gewachsen zu sein.
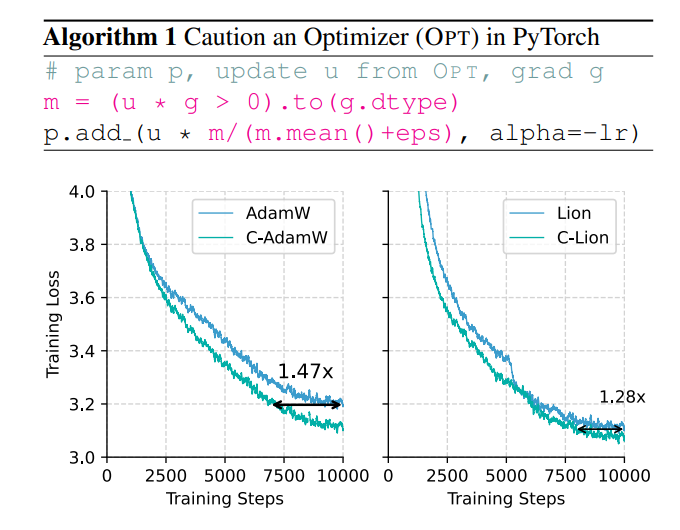
Gibt es nicht eine Möglichkeit, die Trainingsgeschwindigkeit zu erhöhen und gleichzeitig den Energieverbrauch zu senken? Keine Sorge, ein rein chinesisches Team ist hier mit seiner Geheimwaffe C-AdamW!
Der vollständige Name von C-AdamW ist Cautious AdamW, und sein chinesischer Name ist Cautious AdamW. Klingt das nicht sehr buddhistisch? Ja, die Kernidee von C-AdamW ist, zweimal nachzudenken, bevor man handelt.

Stellen Sie sich vor, dass die Parameter des Modells wie eine Gruppe energiegeladener Kinder sind, die immer herumlaufen wollen. AdamW ist wie ein engagierter Lehrer, der versucht, sie in die richtige Richtung zu führen. Aber manchmal sind Kinder zu aufgeregt und rennen in die falsche Richtung, was Zeit und Energie verschwendet.
Zu diesem Zeitpunkt ist C-AdamW wie ein weiser Ältester mit einem Paar durchdringender Augen, der genau erkennen kann, ob die Aktualisierungsrichtung korrekt ist. Wenn die Richtung falsch ist, ruft C-AdamW entschieden einen Stopp auf, um zu verhindern, dass das Modell weiter in die falsche Richtung fährt.
Diese vorsichtige Strategie stellt sicher, dass jede Aktualisierung die Verlustfunktion effektiv reduzieren kann, wodurch die Konvergenz des Modells beschleunigt wird. Experimentelle Ergebnisse zeigen, dass C-AdamW die Trainingsgeschwindigkeit im Lama- und MAE-Vortraining auf das 1,47-fache erhöht!
Noch wichtiger ist, dass C-AdamW nahezu keinen zusätzlichen Rechenaufwand erfordert und mit einer einfachen einzeiligen Änderung des vorhandenen Codes implementiert werden kann. Dies bedeutet, dass Entwickler C-AdamW problemlos auf verschiedene Modelltrainings anwenden und die Geschwindigkeit und Leidenschaft genießen können!
Das Tolle an C-AdamW ist, dass es Adams Hamilton-Funktion beibehält und die Konvergenzgarantie gemäß der Lyapunov-Analyse nicht zerstört. Das bedeutet, dass C-AdamW nicht nur schneller ist, sondern auch seine Stabilität gewährleistet ist und es zu keinen Problemen wie Trainingsabstürzen kommt.
Buddhist zu sein bedeutet natürlich nicht, dass man nicht unternehmungslustig ist. Das Forschungsteam erklärte, dass es weiterhin umfangreichere ϕ-Funktionen erforschen und Masken im Merkmalsraum statt im Parameterraum anwenden werde, um die Leistung von C-AdamW weiter zu verbessern.
Es ist absehbar, dass C-AdamW zum neuen Favoriten im Bereich Deep Learning wird und das Training großer Modelle revolutionär verändert!
Papieradresse: https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
Das Aufkommen von C-AdamW liefert neue Ideen zur Lösung der Probleme der Trainingseffizienz und des Energieverbrauchs großer Modelle. Seine hohe Effizienz, Stabilität und benutzerfreundlichen Eigenschaften machen es für die Anwendung sehr vielversprechend. Es wird erwartet, dass C-AdamW in Zukunft in weiteren Bereichen eingesetzt werden kann und die kontinuierliche Entwicklung der KI-Technologie vorantreibt. Der Herausgeber von Downcodes wird weiterhin auf relevante technologische Fortschritte achten, also bleiben Sie dran!