Der Herausgeber von Downcodes erfuhr, dass die Peking-Universität und andere wissenschaftliche Forschungsteams LLaVA-o1 veröffentlicht haben, ein bahnbrechendes multimodales Open-Source-Modell. Das Modell übertraf Konkurrenten wie Gemini, GPT-4o-mini und Llama in mehreren Benchmark-Tests, und sein „langsam denkender“ Argumentationsmechanismus ermöglichte ihm die Durchführung komplexerer Überlegungen, vergleichbar mit GPT-o1. Die Open Source von LLaVA-o1 wird der Forschung und Anwendung im Bereich der multimodalen KI neue Dynamik verleihen.
Kürzlich gaben die Universität Peking und andere wissenschaftliche Forschungsteams die Veröffentlichung eines multimodalen Open-Source-Modells namens LLaVA-o1 bekannt, das angeblich das erste visuelle Sprachmodell ist, das zu spontanem und systematischem Denken fähig ist, vergleichbar mit GPT-o1.
Das Modell schneidet bei sechs anspruchsvollen multimodalen Benchmarks gut ab, wobei seine 11B-Parameter-Version andere Konkurrenten wie Gemini-1.5-pro, GPT-4o-mini und Llama-3.2-90B-Vision-Instruct übertrifft.
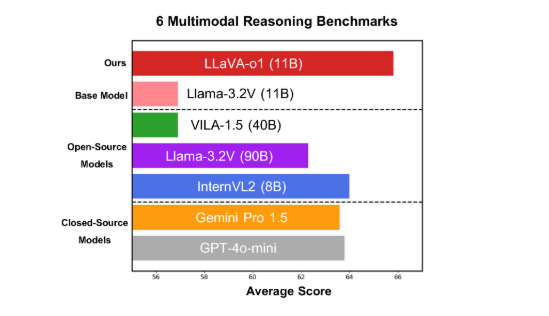
LLaVA-o1 basiert auf dem Llama-3.2-Vision-Modell und verwendet einen Denkmechanismus mit „langsamem Denken“, der komplexere Denkprozesse selbstständig durchführen kann und damit die traditionelle Denkketten-Promptmethode übertrifft.
Beim multimodalen Inferenz-Benchmark übertraf LLaVA-o1 sein Basismodell um 8,9 %. Das Besondere an dem Modell ist, dass sein Argumentationsprozess in vier Phasen unterteilt ist: Zusammenfassung, visuelle Erklärung, logisches Denken und Generierung von Schlussfolgerungen. In traditionellen Modellen ist der Argumentationsprozess oft relativ einfach und kann leicht zu falschen Antworten führen, während LLaVA-o1 durch strukturierte mehrstufige Argumentation eine genauere Ausgabe gewährleistet.
Wenn Sie beispielsweise das Problem „Wie viele Objekte bleiben nach Abzug aller kleinen hellen Kugeln und violetten Objekte übrig?“ lösen, fasst LLaVA-o1 zunächst das Problem zusammen, extrahiert dann Informationen aus dem Bild und führt dann eine schrittweise Argumentation durch , und geben Sie schließlich Antwort. Dieser abgestufte Ansatz verbessert die systematischen Argumentationsfähigkeiten des Modells und macht es effizienter bei der Bearbeitung komplexer Probleme.

Es ist erwähnenswert, dass LLaVA-o1 im Inferenzprozess eine Strahlsuchmethode auf Bühnenebene einführt. Dieser Ansatz ermöglicht es dem Modell, in jeder Inferenzphase mehrere Kandidatenantworten zu generieren und die beste Antwort auszuwählen, um mit der nächsten Inferenzphase fortzufahren, wodurch die Gesamtqualität der Inferenz erheblich verbessert wird. Mit überwachter Feinabstimmung und angemessenen Trainingsdaten schneidet LLaVA-o1 im Vergleich mit größeren oder Closed-Source-Modellen gut ab.
Die Forschungsergebnisse des Teams der Peking-Universität fördern nicht nur die Entwicklung multimodaler KI, sondern liefern auch neue Ideen und Methoden für zukünftige Modelle des visuellen Sprachverständnisses. Das Team erklärte, dass der Code, die Pre-Training-Gewichte und die Datensätze von LLaVA-o1 vollständig Open Source sein werden, und sie freuen sich darauf, dass weitere Forscher und Entwickler dieses innovative Modell gemeinsam erforschen und anwenden.
Papier: https://arxiv.org/abs/2411.10440
GitHub:https://github.com/PKU-YuanGroup/LLaVA-o1
Die Open Source von LLaVA-o1 wird zweifellos die technologische Entwicklung und Anwendungsinnovation im Bereich der multimodalen KI fördern. Sein effizienter Inferenzmechanismus und seine hervorragende Leistung machen es zu einer wichtigen Referenz für die zukünftige Forschung an visuellen Sprachmodellen und verdienen Aufmerksamkeit und Vorfreude. Wir freuen uns darauf, dass sich weitere Entwickler beteiligen und gemeinsam den Fortschritt der Technologie der künstlichen Intelligenz vorantreiben.