Der Open-Source-KI-Bereich hat in den letzten Jahren einen Boom erlebt, aber im Vergleich zu großen Technologieunternehmen besteht immer noch eine Lücke. Die Rechenleistung ist nur ein Aspekt, und der kritischere Aspekt ist der Mangel an Lösungen nach dem Training. Der neueste Durchbruch von AI2 (ehemals Allen Artificial Intelligence Institute) – das Tülu3-Post-Training-Programm – bietet eine leistungsstarke Waffe, um diese Lücke zu schließen. Der Herausgeber von Downcodes wird Ihnen ein detailliertes Verständnis dafür vermitteln, wie diese Technologie Open-Source-KI ermöglicht und große Sprachmodelle, die ursprünglich schwer zu kontrollieren waren, einfach zu verwenden und anzupassen macht.
Im Bereich der Open-Source-KI zeigt sich der Abstand zu großen Technologieunternehmen nicht nur in der Rechenleistung. AI2 (ehemals Allen Artificial Intelligence Institute) schließt diese Lücke durch eine Reihe bahnbrechender Initiativen. Sein neu veröffentlichtes Tülu3-Post-Training-Programm macht es möglich, ursprüngliche große Sprachmodelle in praktische KI-Systeme umzuwandeln.
Im Gegensatz zur allgemeinen Kognition können grundlegende Sprachmodelle nicht direkt nach dem Vortraining verwendet werden. Tatsächlich ist der Post-Training-Prozess das entscheidende Glied, das den endgültigen Wert des Modells bestimmt. In diesem Stadium wandelt sich das Modell von einem allwissenden Netzwerk ohne Urteilsvermögen zu einem praktischen Werkzeug mit einer spezifischen funktionalen Ausrichtung.
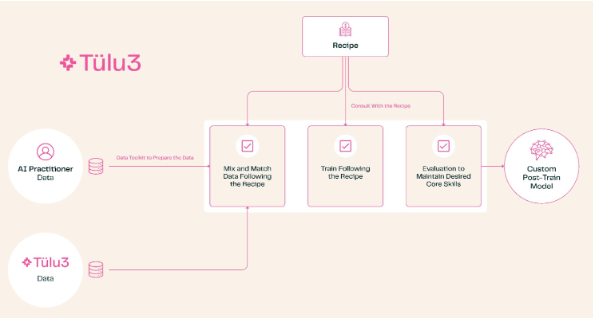
Lange Zeit haben große Unternehmen ihre Nachschulungsprogramme verschwiegen. Während jeder ein Modell mit der neuesten Technologie erstellen kann, sind spezielle Techniken nach dem Training erforderlich, um ein Modell in bestimmten Bereichen, wie etwa psychologischer Beratung oder Forschungsanalyse, nützlich zu machen. Selbst bei Projekten wie Metas Llama, das als Open Source beworben wird, sind die Quelle des ursprünglichen Modells und die gängigen Trainingsmethoden weiterhin streng vertraulich.
Das Aufkommen von Tülu3 ändert diese Situation. Dieses komplette Set an Post-Training-Lösungen deckt ein komplettes Spektrum an Prozessen ab, von der Themenauswahl bis zum Datenmanagement, vom Reinforcement Learning bis zur Feinabstimmung. Benutzer können die Modellfunktionen entsprechend ihren Anforderungen anpassen, z. B. die Mathematik- und Programmierfähigkeiten stärken oder die Priorität der Mehrsprachenverarbeitung verringern.
Der Test von AI2 zeigt, dass die Leistung des von Tülu3 trainierten Modells das Niveau der Top-Open-Source-Modelle erreicht hat. Dieser Durchbruch ist bedeutsam: Er bietet Unternehmen eine völlig autonome und kontrollierbare Wahlmöglichkeit. Insbesondere Institutionen, die mit sensiblen Daten umgehen, wie beispielsweise die medizinische Forschung, müssen nicht mehr auf APIs oder maßgeschneiderte Dienste von Drittanbietern angewiesen sein. Sie können den gesamten Schulungsprozess lokal durchführen, was Kosten spart und die Privatsphäre schützt.
AI2 hat diese Lösung nicht nur veröffentlicht, sondern auch die Führung bei der Anwendung auf seine eigenen Produkte übernommen. Obwohl die aktuellen Testergebnisse auf dem Llama-Modell basieren, planen sie die Einführung eines neuen Modells, das auf ihrem eigenen OLMo basiert und von Tülu3 trainiert wird und von Anfang bis Ende eine wirklich vollständig Open-Source-Lösung sein wird.
Diese Open-Source-Technologie zeigt nicht nur die Entschlossenheit von AI2, die Demokratisierung der KI voranzutreiben, sondern verleiht auch der gesamten Open-Source-KI-Community Auftrieb. Es bringt uns einem wirklich offenen und transparenten KI-Ökosystem einen Schritt näher.
Die Open Source von Tülu3 stellt einen großen Fortschritt im Bereich der Open-Source-KI dar. Sie senkt die Schwelle für KI-Anwendungen, fördert die Fairness und den Austausch von KI-Technologie und bietet unbegrenzte Möglichkeiten für die zukünftige KI-Entwicklung. Wir freuen uns auf die Entstehung weiterer ähnlicher Open-Source-Projekte, um gemeinsam ein florierenderes KI-Ökosystem aufzubauen.