Sind Sie neugierig auf die Technologie hinter KI-Produkten wie ChatGPT und Wenxinyiyan? Sie alle basieren auf großen Sprachmodellen (LLM). Der Herausgeber von Downcodes bringt Ihnen das Funktionsprinzip von LLM auf einfache und leicht verständliche Weise näher. Selbst wenn Sie nur über ein Mathematikniveau der zweiten Klasse verfügen, können Sie es leicht verstehen! Wir beginnen mit den Grundkonzepten neuronaler Netze und erläutern nach und nach Modelltraining, fortgeschrittene Techniken und Kerntechnologien wie GPT und Transformer-Architektur, damit Sie ein klares Verständnis von LLM haben.
Haben Sie von fortschrittlicher KI wie ChatGPT und Wen Xinyiyan gehört? Die Kerntechnologie dahinter ist das „Large Language Model“ (LLM). Finden Sie es kompliziert und schwer zu verstehen? Keine Sorge, auch wenn Sie erst über ein Mathematikniveau der zweiten Klasse verfügen, können Sie das Funktionsprinzip von LLM nach der Lektüre dieses Artikels leicht verstehen!
Neuronale Netze: Die Magie der Zahlen
Zunächst müssen wir wissen, dass ein neuronales Netzwerk wie ein Supercomputer ist und nur Zahlen verarbeiten kann. Sowohl Eingabe als auch Ausgabe müssen Zahlen sein. Wie sorgen wir also dafür, dass der Text verstanden wird?
Das Geheimnis besteht darin, Wörter in Zahlen umzuwandeln! Wir können beispielsweise jeden Buchstaben durch eine Zahl darstellen, z. B. a=1, b=2 usw. Auf diese Weise kann das neuronale Netzwerk den Text „lesen“.
Trainieren des Modells: Lassen Sie das Netzwerk Sprache „lernen“.
Bei digitalem Text besteht der nächste Schritt darin, das Modell zu trainieren und das neuronale Netzwerk die Regeln der Sprache „lernen“ zu lassen.
Der Trainingsprozess gleicht einem Ratespiel. Wir zeigen dem Netzwerk einen Text, beispielsweise „Humpty Dumpty“, und bitten es, den nächsten Buchstaben zu erraten. Wenn es richtig rät, geben wir ihm eine Belohnung; wenn es falsch rät, geben wir ihm eine Strafe. Durch ständiges Raten und Anpassen kann das Netzwerk den nächsten Buchstaben mit zunehmender Genauigkeit vorhersagen und schließlich vollständige Sätze wie „Humpty Dumpty saß auf einer Wand“ produzieren.
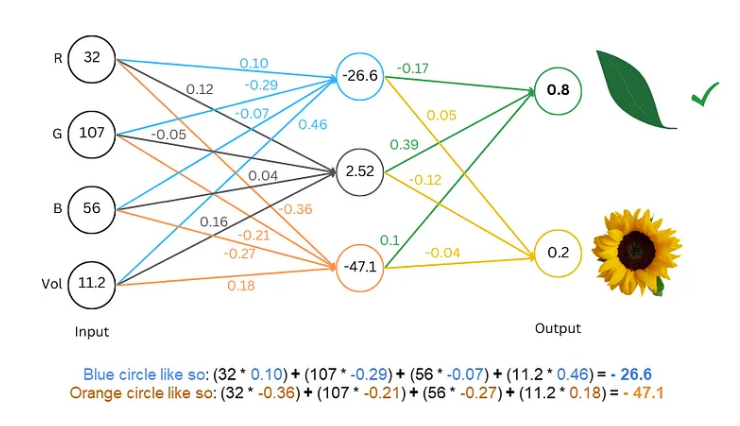
Fortgeschrittene Techniken: Machen Sie das Modell „intelligenter“
Um das Modell „intelligenter“ zu machen, haben Forscher viele fortschrittliche Techniken erfunden, wie zum Beispiel:
Worteinbettung: Anstatt einfache Zahlen zur Darstellung von Buchstaben zu verwenden, verwenden wir eine Reihe von Zahlen (Vektoren) zur Darstellung jedes Wortes, die die Bedeutung des Wortes vollständiger beschreiben können.
Unterwort-Segmentierer: Teilen Sie Wörter in kleinere Einheiten (Unterwörter) auf, z. B. die Aufteilung von „Katzen“ in „Katze“ und „s“, wodurch der Wortschatz reduziert und die Effizienz verbessert werden kann.
Selbstaufmerksamkeitsmechanismus: Wenn das Modell das nächste Wort vorhersagt, passt es die Gewichtung der Vorhersage basierend auf allen Wörtern im Kontext an, genau wie wir beim Lesen die Bedeutung des Wortes basierend auf dem Kontext verstehen.
Restverbindung: Um Trainingsschwierigkeiten zu vermeiden, die durch zu viele Netzwerkschichten verursacht werden, haben Forscher die Restverbindung erfunden, um das Erlernen des Netzwerks zu erleichtern.
Mehrkopf-Aufmerksamkeitsmechanismus: Durch die parallele Ausführung mehrerer Aufmerksamkeitsmechanismen kann das Modell den Kontext aus verschiedenen Perspektiven verstehen und die Genauigkeit von Vorhersagen verbessern.
Positionskodierung: Damit das Modell die Reihenfolge von Wörtern verstehen kann, fügen Forscher Positionsinformationen zu Worteinbettungen hinzu, so wie wir beim Lesen auf die Reihenfolge von Wörtern achten.
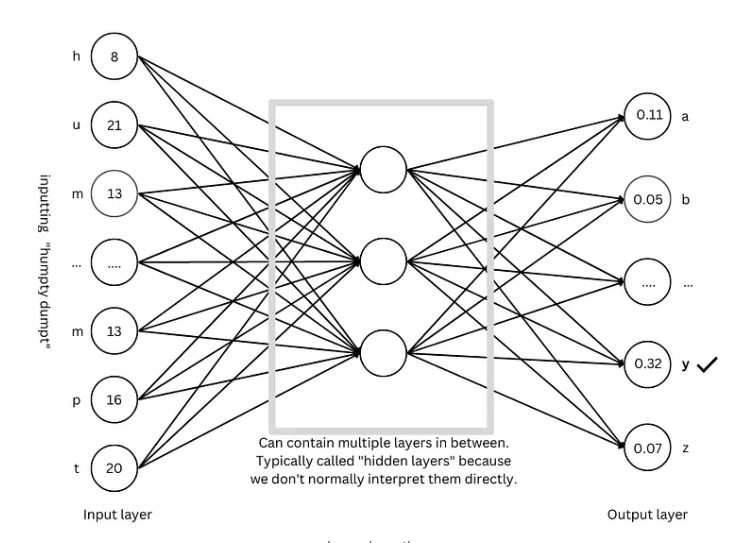
GPT-Architektur: die „Blaupause“ für große Sprachmodelle
Die GPT-Architektur ist derzeit eine der beliebtesten großen Sprachmodellarchitekturen. Sie ist wie eine „Blaupause“, die den Entwurf und das Training des Modells leitet. Die GPT-Architektur kombiniert geschickt die oben genannten fortschrittlichen Techniken, um dem Modell ein effizientes Lernen und Generieren von Sprache zu ermöglichen.
Transformer-Architektur: Die „Revolution“ der Sprachmodelle
Die Transformer-Architektur stellt in den letzten Jahren einen großen Durchbruch auf dem Gebiet der Sprachmodelle dar. Sie verbessert nicht nur die Genauigkeit der Vorhersage, sondern verringert auch die Schwierigkeit des Trainings und legt damit den Grundstein für die Entwicklung umfangreicher Sprachmodelle. Die GPT-Architektur entwickelte sich ebenfalls auf Basis der Transformer-Architektur.
Referenz: https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
Ich hoffe, dass die Erklärung des Herausgebers von Downcodes Ihnen helfen kann, die Funktionsprinzipien großer Sprachmodelle zu verstehen. Natürlich entwickelt sich die LLM-Technologie immer noch weiter. Dieser Artikel ist nur die Spitze des Eisbergs. Immer tiefergehende Inhalte erfordern, dass Sie weiter lernen und erforschen.