Der Herausgeber von Downcodes erfuhr, dass Meta kürzlich einen neuen mehrsprachigen Multi-Turn-Dialogbefehl nach dem Fähigkeitsbewertungs-Benchmark-Test Multi-IF veröffentlicht hat. Der Benchmark deckt acht Sprachen ab und enthält 4501 Drei-Runden-Dialogaufgaben mit dem Ziel, große Dialoge umfassender zu bewerten Sprachmodelle (LLM) Leistung in praktischen Anwendungen. Im Gegensatz zu bestehenden Bewertungsstandards, die sich hauptsächlich auf Single-Turn-Dialoge und einsprachige Aufgaben konzentrieren, konzentriert sich Multi-IF auf die Untersuchung der Fähigkeit des Modells in komplexen Multi-Turn- und Mehrsprachenszenarien und bietet so eine klarere Richtung für die Verbesserung von LLM.
Meta hat kürzlich einen neuen Benchmark-Test namens Multi-IF veröffentlicht, der darauf ausgelegt ist, die Fähigkeit zur Befehlsfolge von großen Sprachmodellen (LLM) in Gesprächen mit mehreren Runden und mehrsprachigen Umgebungen zu bewerten. Dieser Benchmark deckt acht Sprachen ab und enthält 4501 Dialogaufgaben mit drei Runden, wobei der Schwerpunkt auf der Leistung aktueller Modelle in komplexen Szenarien mit mehreren Runden und mehreren Sprachen liegt.
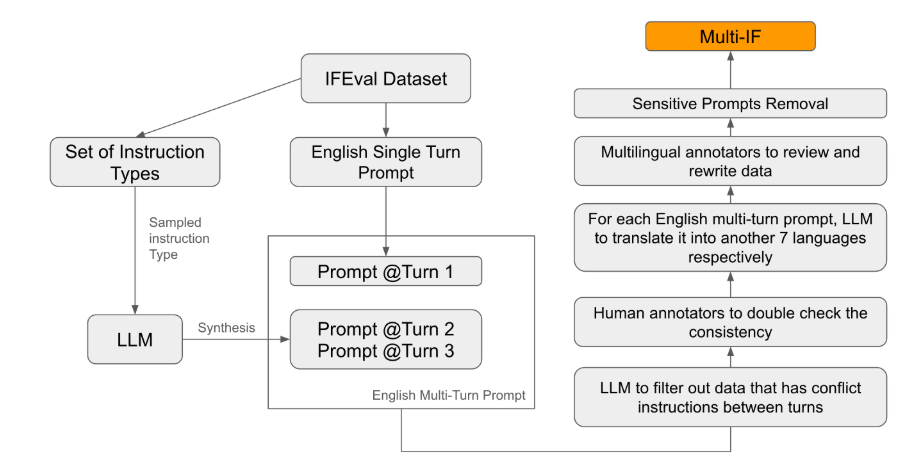
Unter den bestehenden Bewertungsstandards konzentrieren sich die meisten auf Single-Turn-Dialoge und einsprachige Aufgaben, die die Leistung des Modells in praktischen Anwendungen nur schwer vollständig widerspiegeln können. Die Einführung von Multi-IF soll diese Lücke schließen. Das Forschungsteam generierte komplexe Dialogszenarien, indem es eine einzelne Anweisungsrunde auf mehrere Anweisungsrunden erweiterte, und stellte sicher, dass jede Anweisungsrunde logisch kohärent und progressiv war. Darüber hinaus wird durch Schritte wie automatische Übersetzung und manuelles Korrekturlesen auch die Mehrsprachenunterstützung des Datensatzes erreicht.
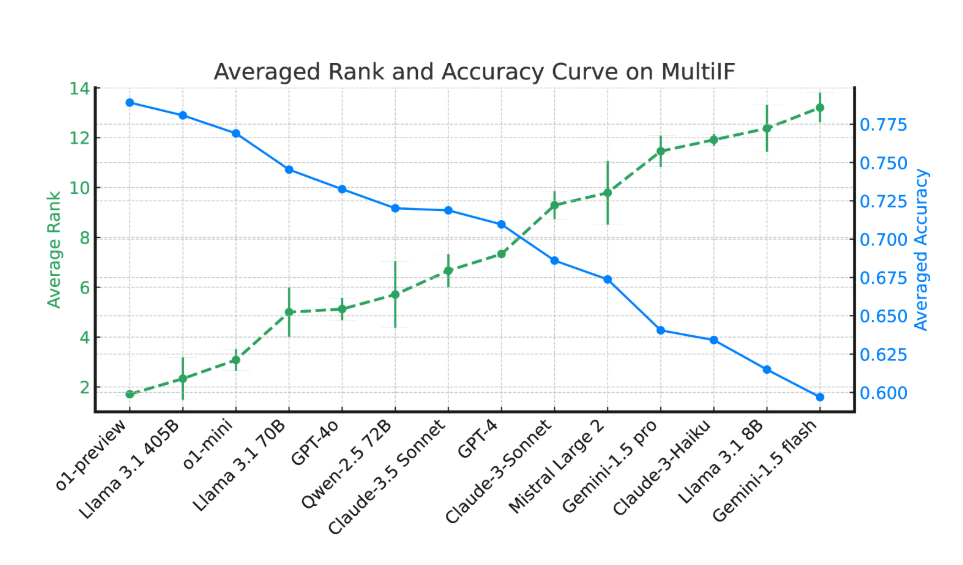
Experimentelle Ergebnisse zeigen, dass die Leistung der meisten LLMs über mehrere Dialogrunden hinweg deutlich abnimmt. Am Beispiel des o1-preview-Modells betrug die durchschnittliche Genauigkeit in der ersten Runde 87,7 %, sank jedoch in der dritten Runde auf 70,7 %. Insbesondere in Sprachen mit nicht-lateinischen Schriften wie Hindi, Russisch und Chinesisch ist die Leistung des Modells im Allgemeinen geringer als die von Englisch, was bei mehrsprachigen Aufgaben zu Einschränkungen führt.
Bei der Bewertung von 14 hochmodernen Sprachmodellen schnitten o1-preview und Llama3.1405B mit durchschnittlichen Genauigkeitsraten von 78,9 % bzw. 78,1 % in drei Befehlsrunden am besten ab. Über mehrere Dialogrunden hinweg zeigte sich jedoch bei allen Modellen ein allgemeiner Rückgang ihrer Fähigkeit, Anweisungen zu befolgen, was die Herausforderungen widerspiegelt, mit denen die Modelle bei komplexen Aufgaben konfrontiert sind. Das Forschungsteam führte außerdem die „Instruction Forgetting Rate“ (IFR) ein, um das Phänomen des Instruction Forgetting des Modells in mehreren Dialogrunden zu quantifizieren. Die Ergebnisse zeigen, dass Hochleistungsmodelle in dieser Hinsicht relativ gut abschneiden.
Die Veröffentlichung von Multi-IF bietet Forschern einen herausfordernden Maßstab und fördert die Entwicklung von LLM in Globalisierung und mehrsprachigen Anwendungen. Die Einführung dieses Benchmarks deckt nicht nur die Mängel aktueller Modelle bei Mehrrunden- und Mehrsprachenaufgaben auf, sondern gibt auch eine klare Richtung für zukünftige Verbesserungen vor.
Papier: https://arxiv.org/html/2410.15553v2
Die Veröffentlichung des Multi-IF-Benchmark-Tests bietet eine wichtige Referenz für die Erforschung großer Sprachmodelle im Multi-Turn-Dialog und in der Mehrsprachenverarbeitung und weist auch den Weg für zukünftige Modellverbesserungen. Es wird erwartet, dass in Zukunft immer leistungsfähigere LLMs entstehen werden, um die Herausforderungen komplexer, mehrstufiger und mehrsprachiger Aufgaben besser bewältigen zu können.