Das Emu3-Team des Zhiyuan Research Institute hat das revolutionäre multimodale Modell Emu3 veröffentlicht, das die traditionelle multimodale Modellarchitektur untergräbt, nur auf der Grundlage der nächsten Token-Vorhersage trainiert und SOTA-Leistung bei Generierungs- und Wahrnehmungsaufgaben erreicht. Das Emu3-Team tokenisiert Bilder, Text und Videos geschickt in diskrete Räume und trainiert ein einzelnes Transformer-Modell auf gemischten multimodalen Sequenzen, wodurch die Vereinheitlichung multimodaler Aufgaben erreicht wird, ohne auf Diffusions- oder Kombinationsarchitekturen angewiesen zu sein, was mehrere modale Felder bietet neue Durchbrüche.
Das Emu3-Team vom Zhiyuan Research Institute hat ein neues multimodales Modell Emu3 veröffentlicht, das nur auf der Grundlage der nächsten Token-Vorhersage trainiert wird, das traditionelle Diffusionsmodell und die Kombinationsmodellarchitektur untergräbt und Ergebnisse sowohl bei Generierungs- als auch bei Wahrnehmungsaufgaben erzielt - Auf dem neuesten Stand der Technik.
Die Vorhersage des nächsten Tokens gilt seit langem als vielversprechender Weg zur künstlichen allgemeinen Intelligenz (AGI), hat jedoch bei multimodalen Aufgaben nur schlechte Ergebnisse erzielt. Derzeit wird der multimodale Bereich noch von Diffusionsmodellen (wie Stable Diffusion) und Kombinationsmodellen (wie der Kombination von CLIP und LLM) dominiert. Das Emu3-Team tokenisiert Bilder, Text und Videos in diskrete Räume und trainiert ein einzelnes Transformer-Modell von Grund auf auf gemischten multimodalen Sequenzen, wodurch multimodale Aufgaben vereinheitlicht werden, ohne auf Diffusion oder kombinatorische Architekturen angewiesen zu sein.
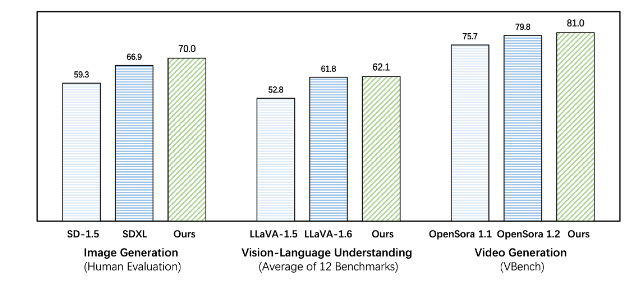
Emu3 übertrifft bestehende aufgabenspezifische Modelle sowohl bei Generierungs- als auch bei Wahrnehmungsaufgaben und übertrifft sogar Flaggschiffmodelle wie SDXL und LLaVA-1.6. Emu3 ist auch in der Lage, High-Fidelity-Videos zu generieren, indem es den nächsten Token in einer Videosequenz vorhersagt. Im Gegensatz zu Sora, das ein Videodiffusionsmodell verwendet, um Videos aus Rauschen zu generieren, generiert Emu3 Videos auf kausale Weise, indem es das nächste Token in der Videosequenz vorhersagt. Das Modell kann bestimmte Aspekte realer Umgebungen, Menschen und Tiere simulieren und vorhersagen, was angesichts des Kontexts des Videos als nächstes passieren wird.
Emu3 vereinfacht den Entwurf komplexer multimodaler Modelle und konzentriert den Fokus auf Token, wodurch ein enormes Skalierungspotenzial während des Trainings und der Inferenz freigesetzt wird. Die Forschungsergebnisse zeigen, dass die Next-Token-Vorhersage eine effektive Möglichkeit ist, allgemeine multimodale Intelligenz über die Sprache hinaus aufzubauen. Um die weitere Forschung in diesem Bereich zu unterstützen, verfügt das Emu3-Team über Open-Source-Schlüsseltechnologien und -Modelle, darunter einen leistungsstarken visuellen Tokenizer, der Videos und Bilder in diskrete Token umwandeln kann, der bisher nicht öffentlich verfügbar war.
Der Erfolg von Emu3 zeigt die Richtung für die zukünftige Entwicklung multimodaler Modelle auf und bringt neue Hoffnung für die Verwirklichung von AGI.
Projektadresse: https://github.com/baaivision/Emu3
Der Downcodes-Editor fasst zusammen: Die Entstehung des Emu3-Modells markiert einen neuen Meilenstein im multimodalen Bereich. Seine einfache Architektur und leistungsstarke Leistung liefern neue Ideen und Richtungen für die zukünftige AGI-Forschung. Die Open-Source-Strategie fördert auch die gemeinsame Entwicklung von Wissenschaft und Industrie. Es lohnt sich, sich auf weitere Durchbrüche in der Zukunft zu freuen!