In den letzten Jahren hat die künstliche Intelligenz in verschiedenen Bereichen erhebliche Fortschritte gemacht, ihre Fähigkeit zum mathematischen Denken war jedoch immer ein Engpass. Heute bietet das Aufkommen eines neuen Benchmarks namens FrontierMath einen neuen Maßstab für die Bewertung der mathematischen Fähigkeiten der KI. Er bringt die mathematischen Denkfähigkeiten der KI an beispiellose Grenzen und stellt bestehende KI-Modelle vor große Herausforderungen. Der Herausgeber von Downcodes vermittelt Ihnen ein tiefgreifendes Verständnis von FrontierMath und zeigt, wie es unser Verständnis der mathematischen Fähigkeiten der KI untergräbt.
Im riesigen Universum der künstlichen Intelligenz galt die Mathematik einst als letzte Bastion der maschinellen Intelligenz. Heute ist ein neuer Benchmark-Test namens FrontierMath erschienen, der die mathematischen Denkfähigkeiten der KI an beispiellose Grenzen bringt.
Epoch AI hat sich mit mehr als 60 Top-Köpfen der Mathematikwelt zusammengetan, um gemeinsam dieses KI-Herausforderungsfeld zu schaffen, das als Mathematikolympiade bezeichnet werden kann. Dies ist nicht nur ein technischer Test, sondern auch der ultimative Test der mathematischen Weisheit der künstlichen Intelligenz.
Stellen Sie sich ein Labor voller weltbester Mathematiker vor, die Hunderte mathematischer Rätsel gelöst haben, die die Vorstellungskraft gewöhnlicher Menschen übertreffen. Diese Probleme umfassen die modernsten mathematischen Bereiche wie Zahlentheorie, reelle Analysis, algebraische Geometrie und Kategorientheorie und sind von atemberaubender Komplexität. Selbst ein Mathematikgenie mit einer Goldmedaille bei der Internationalen Mathematikolympiade braucht Stunden oder sogar Tage, um ein Problem zu lösen.
Erschreckenderweise schnitten die aktuellen hochmodernen KI-Modelle bei diesem Benchmark enttäuschend ab: Kein Modell konnte mehr als 2 % der Probleme lösen. Dieses Ergebnis war wie ein Weckruf und schlug der KI ins Gesicht.
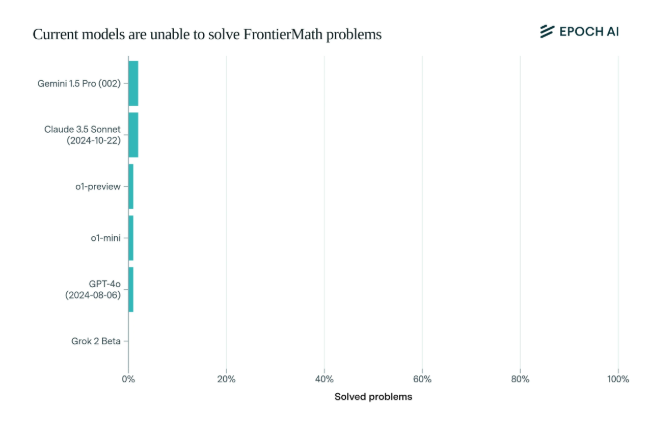
Was FrontierMath einzigartig macht, ist sein strenger Bewertungsmechanismus. Traditionelle mathematische Testbenchmarks wie MATH und GSM8K wurden durch KI ausgereizt, und dieser neue Benchmark verwendet neue, unveröffentlichte Fragen und ein automatisiertes Verifizierungssystem, um Datenverschmutzung effektiv zu vermeiden und die mathematischen Denkfähigkeiten der KI wirklich zu testen.
Die viel beachteten Vorzeigemodelle von Top-KI-Unternehmen wie OpenAI, Anthropic und Google DeepMind überschlugen sich in diesem Test kollektiv. Dies spiegelt eine tiefgreifende technische Philosophie wider: Für Computer mögen scheinbar komplexe mathematische Probleme einfach sein, aber Aufgaben, die Menschen einfach finden, können die KI hilflos machen.
Wie Andrej Karpathy sagte, bestätigt dies Moravecs Paradoxon: Die Schwierigkeit intelligenter Aufgaben zwischen Menschen und Maschinen ist oft kontraintuitiv. Dieser Benchmark-Test ist nicht nur eine strenge Prüfung der KI-Fähigkeiten, sondern auch ein Katalysator für die Entwicklung der KI in höhere Dimensionen.
Für die Mathematik-Community und KI-Forscher ist FrontierMath wie ein unbesiegter Mount Everest. Es prüft nicht nur Wissen und Fähigkeiten, sondern auch Einsicht und kreatives Denken. Wer es in Zukunft schafft, diesen Gipfel der Intelligenz zu erklimmen, wird in die Geschichte der Entwicklung der künstlichen Intelligenz eingehen.
Das Aufkommen des FrontierMath-Benchmark-Tests stellt nicht nur einen harten Test des bestehenden KI-Technologieniveaus dar, sondern zeigt auch die Richtung für die zukünftige KI-Entwicklung auf. Er zeigt, dass die KI im Bereich des mathematischen Denkens noch einen langen Weg vor sich hat Es stimuliert auch die Forschung und führt weiterhin Innovationen durch, um die Engpässe bestehender Technologien zu überwinden.