Heutzutage ist ein reibungsloses und natürliches Gesprächserlebnis angesichts der immer häufigeren Mensch-Computer-Interaktion immer noch eine Herausforderung. Der Herausgeber von Downcodes stellt Ihnen heute eine bahnbrechende Technologie vor – Moshi, ein von Kyutai Labs entwickeltes Vollduplex-Sprachdialogsystem. Ziel ist es, eine natürlichere und reibungslosere Kommunikation zwischen Mensch und Maschine zu ermöglichen und die Kommunikation mit Maschinen so einfach zu machen wie das Gespräch mit Freunden. Die Kerninnovation von Moshi liegt in der einzigartigen Speech-to-Speech-Erzeugungsmethode und der fortschrittlichen Technologie, die mehrere Audiostreams gleichzeitig verarbeiten kann. Werfen wir einen genaueren Blick auf die vielen Highlights von Moshi.
In diesem digitalen Zeitalter sind unsere Gespräche mit Maschinen zu einem Teil unseres täglichen Lebens geworden. Allerdings mangelt es diesen Dialogen oft an Natürlichkeit und Fluss, wodurch sie etwas weniger menschlich wirken. Das könnte sich jedoch bald ändern. Moshi, ein von Kyutai Labs entwickeltes Vollduplex-Sprachdialogsystem, läutet eine neue Ära eines natürlicheren und reibungsloseren Mensch-Computer-Dialogs ein.
Moshi ist ein Dialogmodell, das auf Sprache und Text basiert. Seine Kerninnovation besteht darin, den Dialog als einen Prozess zur Erzeugung von Sprache zu Sprache zu behandeln. Diese Methode löst auf clevere Weise viele Probleme herkömmlicher Sprachdialogsysteme, wie z. B. Verzögerungen, Informationsverlust und Einschränkungen beim Abwechseln. Das Besondere an Moshi ist, dass er wie wir Menschen gleichzeitig zuhören und sprechen kann und problemlos mit Überschneidungen, Unterbrechungen und Einwürfen in Gesprächen umgehen kann.
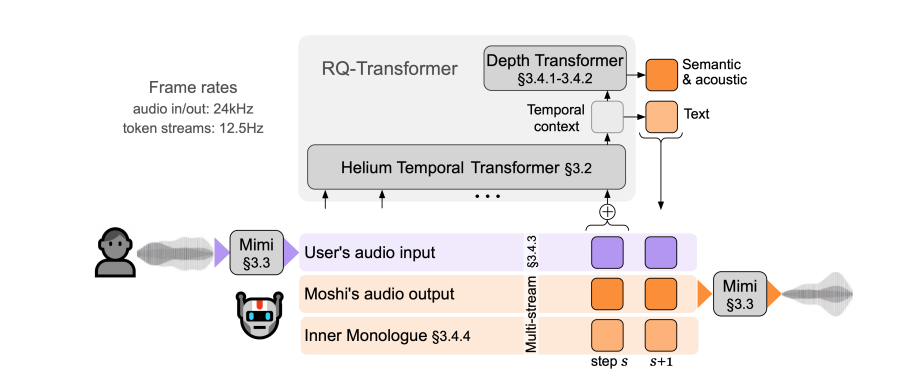
Die leistungsstarke Funktionalität von Moshi beruht auf drei Kerntechnologien. Das erste ist das Helium-Textsprachenmodell, das das Gehirn von Moshi ist. Es verfügt über 7 Milliarden Parameter und verfügt über leistungsstarke Sprachverständnis- und Generierungsfunktionen durch das Erlernen umfangreicher englischer Daten. Als nächstes kommt der Mimi Neural Audio Codec, der als Mund und Ohren von Moshi fungiert und zwischen Sprachsignalen und diskreten Einheiten umwandelt, die das Modell verstehen kann. Schließlich ist das Multi-Stream-Audio-Sprachmodell Moshis Innovation, das die gleichzeitige Verarbeitung mehrerer Audio-Streams ermöglicht und so das gleichzeitige Verstehen der Stimmen mehrerer Sprecher ermöglicht.
Moshi hat auch eine einzigartige innere Monologfunktion. Vor der Spracherzeugung werden zeitlich ausgerichtete Text-Tokens vorhergesagt, die mit Audio-Tokens synchronisiert werden. Dies verbessert nicht nur die sprachliche Qualität der generierten Sprache, sondern bietet auch Streaming-Spracherkennung und Text-to-Speech-Dienste, wodurch die Konversationsfähigkeiten weiter verbessert werden.
In verschiedenen Leistungstests zeigte Moshi hervorragende Leistungen. Ob es um Textverständnis, Sprachverständlichkeit, Audioqualität oder gesprochene Fragen und Antworten geht, Moshi hat das Spitzenniveau unter den bestehenden Sprach-Text-Modellen erreicht. Damit sind wir einem wirklich natürlichen und reibungslosen Mensch-Computer-Dialog einen Schritt näher gekommen.
Mit der Entwicklung der KI-Technologie sind Sicherheitsfragen jedoch immer wichtiger geworden. Es ist erwähnenswert, dass Moshis Entwicklungsteam dies von Anfang an berücksichtigt hat. Sie ergreifen verschiedene Maßnahmen, um die Sicherheit des Systems zu gewährleisten, einschließlich der Vermeidung der Generierung schädlicher Inhalte, des Schutzes der Privatsphäre der Benutzer und der Gewährleistung einer soliden Konsistenz. Moshi ist in der Lage, unangemessene Fragen zu erkennen und deren Beantwortung zu verweigern, wobei die Konsistenz seiner eigenen Stimme erhalten bleibt und die Stimme des Benutzers nicht imitiert wird, was den Benutzern zusätzliche Sicherheit bietet.
Das Aufkommen von Moshi ist nicht nur ein Durchbruch in der Technologie, sondern kündigt auch eine große Innovation in der Art der Mensch-Computer-Interaktion an. Es zeigt uns die unendlichen Möglichkeiten zukünftiger Dialogsysteme und lässt uns die glänzende Aussicht auf einen natürlichen, reibungslosen und humanen Dialog zwischen Menschen und Maschinen erkennen. Wenn sich diese Technologie weiterentwickelt und verbessert, können wir möglicherweise schon bald eine wirklich barrierefreie und qualitativ hochwertige Kommunikation mit Maschinen erreichen, sodass Szenen aus Science-Fiction-Filmen im echten Leben nachgespielt werden können.
Modelladresse: https://huggingface.co/kyutai/moshiko-pytorch-bf16
Papieradresse: https://kyutai.org/Moshi.pdf
Die Entstehung von Moshi weist den Weg für die zukünftige Mensch-Computer-Interaktion und sein reibungsloses und natürliches Gesprächserlebnis ist aufregend. Man geht davon aus, dass die Kommunikation zwischen Mensch und Maschine mit der kontinuierlichen Weiterentwicklung der Technologie immer komfortabler und natürlicher wird und schließlich eine wirklich barrierefreie Kommunikation erreicht wird. Warten wir ab!