OpenAIs neuestes KI-Modell „o1-preview“ (zuvor Codename „Strawberry“) hat heftige Diskussionen ausgelöst. OpenAI behauptete, seine Fähigkeiten seien so gut wie die eines Doktoranden, doch in tatsächlichen Tests zeigte es enttäuschende Fehler. Der Herausgeber von Downcodes führt Sie zu einem detaillierten Verständnis dieses mit Spannung erwarteten, aber problematischen KI-Modells, um zu sehen, welches Niveau es erreicht hat und um das tatsächliche Feedback der Benutzer zu erfahren.
Kürzlich hat OpenAI das mit Spannung erwartete KI-Modell auf den Markt gebracht, das zuvor den Codenamen „Strawberry“ und offiziell den Namen „o1-preview“ trug.
OpenAI verspricht, dass das neue Modell bei schwierigen Benchmark-Aufgaben in Physik, Chemie und Biologie genauso gut abschneiden wird wie ein Doktorand. Vorläufige Testergebnisse zeigen jedoch, dass diese KI noch weit von ihrem Ziel entfernt ist, menschliche Wissenschaftler oder Programmierer zu ersetzen.
In den sozialen Medien teilten viele Benutzer ihre Erfahrungen mit der KI „OpenAI o1“ und die Ergebnisse zeigten, dass das Modell bei grundlegenden Aufgaben immer noch schlecht abschnitt.
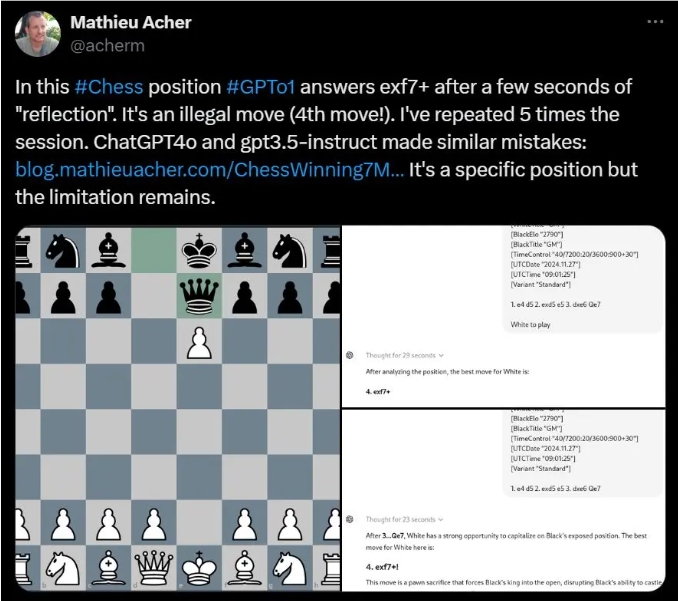
Mathieu Acher, Forscher am INSA Rennes, fand beispielsweise heraus, dass OpenAI o1 beim Lösen bestimmter Schachrätsel häufig illegale Züge vorschlägt.
Der Meta-KI-Wissenschaftler Colin Fraser wies darauf hin, dass die KI in einem einfachen Worträtsel über Bauern, die Schafe über einen Fluss transportieren, tatsächlich die richtige Antwort aufgegeben und stattdessen unlogischen Unsinn gegeben hat.

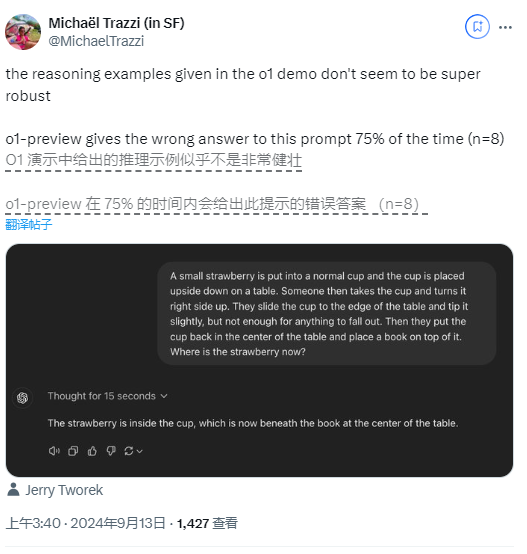
Sogar in dem Logikrätsel, das OpenAI als Demonstration verwendete, führten Fragen zu Erdbeeren dazu, dass Benutzer unterschiedliche Antworten erhielten, wobei ein Benutzer feststellte, dass das Modell eine Fehlerquote von bis zu 75 % aufwies.
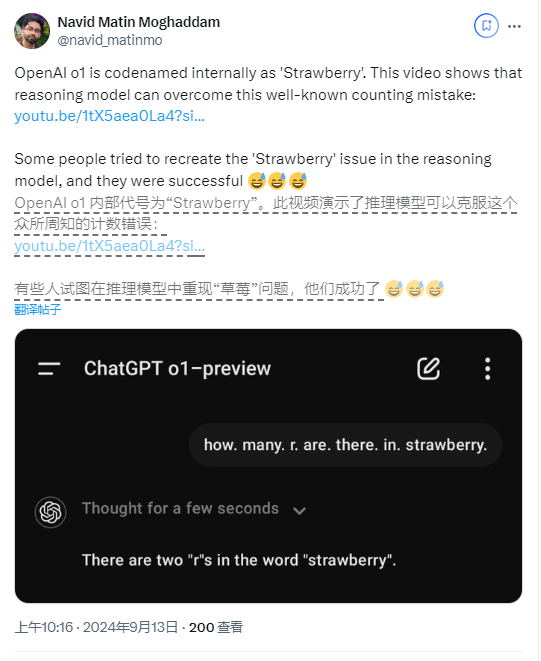
Darüber hinaus haben einige Benutzer berichtet, dass das neue Modell sogar Fehler macht, wenn es zählt, wie oft der Buchstabe „R“ im Wort „Erdbeere“ vorkommt.
Obwohl OpenAI zum Zeitpunkt der Veröffentlichung erklärte, dass es sich um ein frühes Modell handele und noch nicht über Funktionen wie Webbrowsing und Datei-Upload verfüge, sind solche grundlegenden Fehler dennoch überraschend.
Zur Verbesserung führte OpenAI den „Denkketten“-Prozess in das neue Modell ein, wodurch sich OpenAI o1 deutlich vom vorherigen GPT-4o-Modell unterscheidet. Dieser Ansatz ermöglicht es der KI, immer wieder nachzudenken, bevor sie zu einer Antwort kommt, allerdings führt dies auch zu längeren Reaktionszeiten.
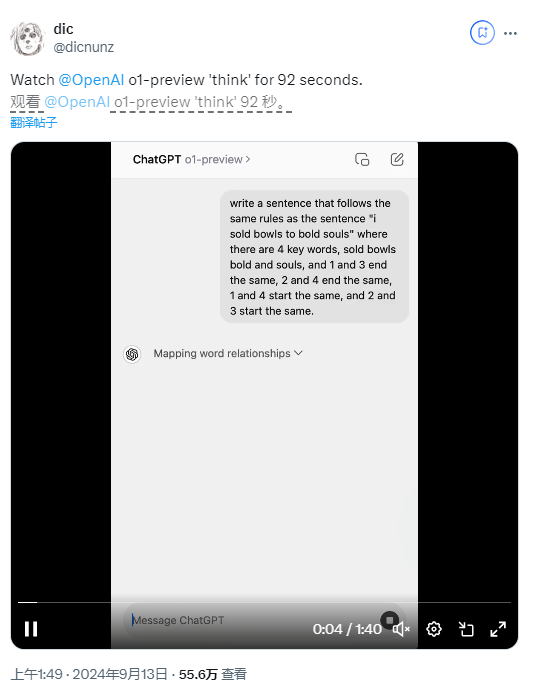
Einige Benutzer stellten fest, dass das Modell tatsächlich 92 Sekunden brauchte, um eine Antwort auf ein Worträtsel zu geben, das Ergebnis aber immer noch falsch war.
Noam Brown, ein Forschungswissenschaftler bei OpenAI, sagte, dass die aktuelle Reaktionsgeschwindigkeit zwar langsam sei, man aber erwarte, dass zukünftige Versionen länger nachdenken und sogar neue Erkenntnisse zu bahnbrechenden Problemen liefern würden.
Der berühmte KI-Kritiker Gary Marcus steht dem jedoch skeptisch gegenüber und glaubt, dass eine langfristige Verarbeitung nicht unbedingt zu transzendenten Denkfähigkeiten führt. Er betonte, dass trotz der kontinuierlichen Weiterentwicklung der KI-Technologie reale Forschung und Experimente weiterhin unverzichtbar seien.
Es zeigt sich, dass die Leistung des neuen KI-Modells von OpenAI im tatsächlichen Einsatz immer noch in allen Aspekten enttäuschend ist, was auch Diskussionen über die zukünftige Entwicklung der KI-Technologie ausgelöst hat.
Highlight:
Kürzlich hat OpenAI ein neues KI-Modell „Strawberry“ auf den Markt gebracht, das angeblich bei komplexen Aufgaben mit Doktoranden vergleichbar ist.
Viele Benutzer stellten fest, dass die KI bei grundlegenden Aufgaben häufig Fehler machte, beispielsweise beim Erfinden illegaler Züge und bei der falschen Beantwortung einfacher Rätsel.
„OpenAI gibt zu, dass sich das Modell noch in der Entwicklung befindet, aber das Denken über einen längeren Zeitraum hinweg wird die Denkfähigkeit möglicherweise nicht verbessern und viele grundlegende Probleme bleiben ungelöst.
Alles in allem zeigt das „o1-preview“-Modell von OpenAI zwar das Potenzial der KI-Technologieentwicklung, weist aber auch viele Mängel in der praktischen Anwendung auf. Auch in Zukunft muss die Entwicklung von KI-Modellen ein Gleichgewicht zwischen technischer Verbesserung und praktischer Anwendung finden, um die erwarteten Ziele wirklich zu erreichen. Der Herausgeber von Downcodes wird die Trends im KI-Bereich weiterhin im Auge behalten und Ihnen weitere spannende Berichte bringen.