Downcodes-Editorberichte: Forschungsteams der Shanghai Jiao Tong University, der Cambridge University und des Geely Automobile Research Institute haben kürzlich ein neues Text-to-Speech-System (TTS) namens F5-TTS auf den Markt gebracht. Das System verwendet eine autoregressionsfreie Methode in Kombination mit Flussanpassung und Diffusionstransformator (DiT), die den komplexen Prozess des traditionellen TTS-Modells effektiv vereinfacht und erhebliche Durchbrüche sowohl bei der Synthesequalität als auch bei der Inferenzgeschwindigkeit erzielt. Im Vergleich zu herkömmlichen TTS-Modellen schneidet F5-TTS hinsichtlich Verarbeitungsgeschwindigkeit und Robustheit gut ab und eröffnet der Sprachsynthesetechnologie neue Möglichkeiten.
Kürzlich hat ein Forschungsteam der Shanghai Jiao Tong University, der Cambridge University und des Geely Automobile Research Institute ein neues Text-to-Speech-System (TTS) namens F5-TTS auf den Markt gebracht. Das Besondere an diesem System ist, dass es eine autoregressionsfreie Methode verwendet, die Flussanpassung mit einem Diffusionstransformator (DiT) kombiniert und so die komplexen Schritte im traditionellen TTS-Modell erfolgreich vereinfacht.

Wie wir alle wissen, erfordern herkömmliche TTS-Modelle häufig eine komplexe Dauermodellierung, Phonemausrichtung und spezielle Textkodierung, was die Komplexität des Syntheseprozesses erhöht. Insbesondere frühere Modelle wie E2TTS sind häufig mit Problemen wie langsamer Konvergenz und ungenauer Ausrichtung von Text und Sprache konfrontiert, was eine effiziente Anwendung in realen Szenarien erschwert. Die Entstehung von F5-TTS dient genau der Lösung dieser Herausforderungen.
Das Funktionsprinzip von F5-TTS ist einfach. Zunächst wird der Eingabetext durch die ConvNeXt-Architektur verarbeitet, um die Ausrichtung auf Sprache zu erleichtern. Die aufgefüllte Zeichenfolge wird dann zusammen mit einer verrauschten Version der Eingabesprache in das Modell eingespeist.
Das Training des Systems basiert auf dem Diffusion Transformer (DiT), der durch Flussanpassung effektiv eine einfache Anfangsverteilung auf die Datenverteilung abbildet. Darüber hinaus führt F5-TTS auf innovative Weise die Sway-Sampling-Strategie während der Inferenz ein, mit der frühe Flussschritte in der Inferenzphase priorisiert werden können, wodurch die Ausrichtung zwischen generierter Sprache und Eingabetext verbessert wird.
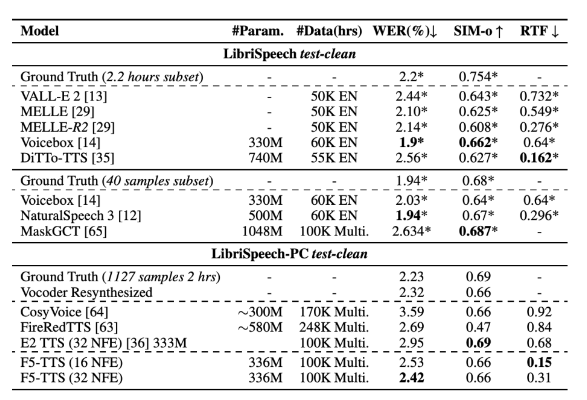
Forschungsergebnissen zufolge übertrifft F5-TTS viele aktuelle TTS-Systeme sowohl in der Synthesequalität als auch in der Inferenzgeschwindigkeit. Im LibriSpeech-PC-Datensatz erreichte das Modell eine Wortfehlerrate (WER) von 2,42 und einen Echtzeitfaktor (RTF) von 0,15 zur Inferenzzeit, was deutlich besser war als das vorherige Diffusionsmodell E2TTS, das bei der Verarbeitung eine bessere Leistung erbrachte Geschwindigkeit und Robustheit weisen Mängel auf.
Gleichzeitig verbessert die Sway-Sampling-Strategie die Natürlichkeit und Verständlichkeit der generierten Sprache erheblich, sodass das Modell ohne Training eine reibungslose und ausdrucksstarke Generierung erreichen kann.
F5-TTS verbessert die Ausrichtungsrobustheit und die Synthesequalität, indem es den Prozess vereinfacht und die Notwendigkeit einer Dauervorhersage, Phonemausrichtung und expliziten Textkodierung eliminiert. Darüber hinaus betonten die Forscher auch ethische Überlegungen und schlugen die Notwendigkeit vor, Wasserzeichen- und Erkennungssysteme einzurichten, um einen Missbrauch des Modells zu verhindern.
Projekteingang: https://github.com/SWivid/F5-TTS
Highlight:
F5-TTS ist ein neuartiges autoregressives Text-to-Speech-System, das die Komplexität des traditionellen TTS-Modells vereinfacht.
Das System nutzt die ConvNeXt- und DiT-Architektur, um die Ausrichtung von Text und Sprache zu verbessern und die Synthesequalität deutlich zu verbessern.
? Die Forscher betonten die Notwendigkeit, auf ethische Fragen zu achten und schlugen die Einführung von Wasserzeichen und Erkennungsmechanismen vor, um potenziellen Missbrauch zu verhindern.
Das Aufkommen des F5-TTS-Systems hat neue Durchbrüche in der Text-to-Speech-Technologie gebracht, und seine effiziente Leistung und vereinfachten Prozesse werden voraussichtlich in vielen Bereichen breite Anwendung finden. Allerdings müssen auch ethische Fragen berücksichtigt werden, und die anschließende Forschung sollte sich der Einrichtung eines soliden Regulierungsmechanismus widmen, um eine verantwortungsvolle Entwicklung der Technologie sicherzustellen.