Der Herausgeber von Downcodes wird Sie dabei unterstützen, ein beunruhigendes Phänomen im Bereich der KI zu verstehen – den Modellkollaps. Stellen Sie sich vor, dass ein KI-Modell wie ein Food-Blogger ist, der anfängt, das Essen zu essen, das er kocht, desto süchtiger wird es und das Essen wird schließlich immer ungenießbarer ist der Zeitpunkt, an dem das Modell zusammenbricht. Es tritt auf, wenn sich ein KI-Modell zu sehr auf die von ihm generierten Daten verlässt, was zu einer Verschlechterung der Modellqualität oder sogar zum vollständigen Ausfall führt. Dieser Artikel befasst sich mit den Ursachen, Auswirkungen und der Vermeidung eines Modellkollapses.
Im KI-Kreis ist kürzlich etwas Seltsames passiert, wie zum Beispiel ein Food-Blogger, der plötzlich anfing, das Essen zu essen, das er gekocht hatte, und je mehr er aß, desto süchtiger wurde er und das Essen wurde immer ungenießbarer. Es ist ziemlich beängstigend, das zu sagen. Der Fachbegriff dafür heißt „Modellkollaps“.
Was ist ein Modellkollaps? Einfach ausgedrückt: Wenn ein KI-Modell während des Trainingsprozesses eine große Menge selbst generierter Daten verwendet, gerät es in einen Teufelskreis, der dazu führt, dass die Qualität der Modellgenerierung immer schlechter wird und schließlich scheitern.
Das ist wie ein geschlossenes Ökosystem. Das KI-Modell ist das einzige Lebewesen in diesem System, und die Nahrung, die es produziert, sind Daten. Anfangs konnte das Unternehmen noch einige natürliche Inhaltsstoffe finden (echte Daten), aber mit der Zeit begann es, sich immer mehr auf die von ihm hergestellten „künstlichen“ Inhaltsstoffe zu verlassen (synthetische Daten). Das Problem besteht darin, dass diese „künstlichen“ Zutaten einen Nährstoffmangel aufweisen und einige der Mängel des Modells selbst aufweisen. Wenn Sie zu viel essen, bricht der „Körper“ des KI-Modells zusammen und die erzeugten Dinge werden immer ungeheuerlicher.
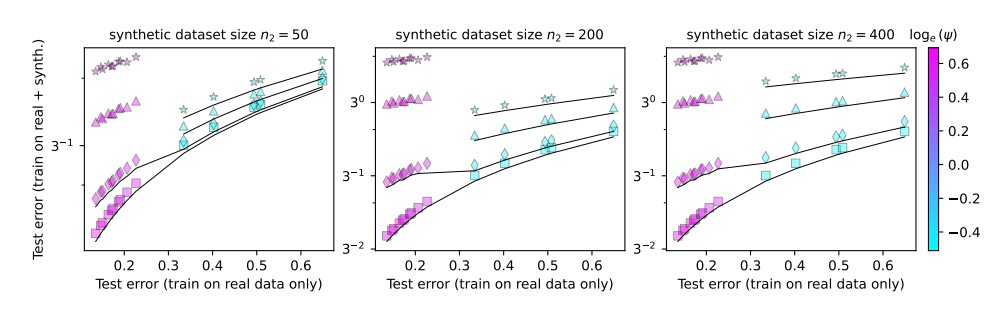
Dieser Artikel untersucht das Phänomen des Modellkollapses und versucht, zwei Schlüsselfragen zu beantworten:
Ist ein Modellkollaps unvermeidlich? Kann das Problem durch die Mischung realer und synthetischer Daten gelöst werden?
Je größer das Modell, desto leichter kann es abstürzen?
Um diese Probleme zu untersuchen, haben die Autoren des Papiers eine Reihe von Experimenten entworfen und ein Zufallsprojektionsmodell verwendet, um den Trainingsprozess des neuronalen Netzwerks zu simulieren. Sie fanden heraus, dass bereits die Verwendung eines kleinen Teils der synthetischen Daten (z. B. 1 %) zum Zusammenbruch des Modells führen könnte. Erschwerend kommt hinzu, dass mit zunehmender Größe des Modells das Phänomen des Modellkollapses immer schwerwiegender wird.
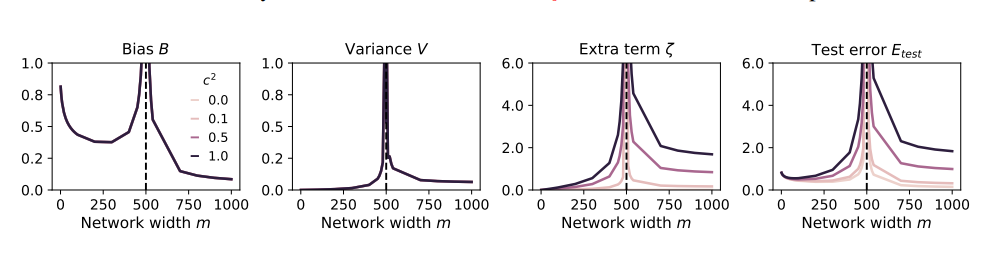
Das ist wie bei einem Food-Blogger, der anfängt, alle möglichen seltsamen Zutaten auszuprobieren, um Aufmerksamkeit zu erregen, aber am Ende einen schlechten Magen bekommt. Um die Verluste auszugleichen, konnte er nur seine Nahrungsaufnahme steigern und mehr und seltsamere Dinge essen. Infolgedessen verschlechterte sich sein Magen immer weiter und er musste schließlich mit der Welt des Essens und Fernsehens aufhören.
Wie können wir also einen Modellkollaps verhindern?
Die Autoren des Papiers machten einige Vorschläge:
Priorisieren Sie die Verwendung realer Daten: Echte Daten sind wie natürliche Nahrung, reich an Nährstoffen und der Schlüssel zum gesunden Wachstum von KI-Modellen.
Verwenden Sie synthetische Daten mit Vorsicht: Synthetische Daten sind wie künstliche Lebensmittel. Obwohl sie einige Nährstoffe ergänzen können, sollten Sie sich nicht zu sehr darauf verlassen, da sie sonst kontraproduktiv sind.
Kontrollieren Sie die Größe des Modells: Je größer das Modell, desto größer der Appetit und desto leichter kann es zu Magenproblemen kommen. Kontrollieren Sie bei der Verwendung synthetischer Daten die Größe des Modells, um eine Überfütterung zu vermeiden.
Der Modellkollaps ist eine neue Herausforderung im Entwicklungsprozess der KI. Er erinnert uns daran, dass wir beim Streben nach Modellgröße und -effizienz auch auf die Qualität der Daten und den Zustand des Modells achten müssen. Nur so können sich KI-Modelle gesund weiterentwickeln und einen größeren Mehrwert für die menschliche Gesellschaft schaffen.
Papier: https://arxiv.org/pdf/2410.04840
Alles in allem ist der Modellzusammenbruch ein Problem, das bei der Entwicklung von KI Beachtung verdient. Wir müssen mit synthetischen Daten vorsichtig umgehen, auf die Qualität realer Daten achten und den Maßstab des Modells kontrollieren, um das Phänomen „KI“ zu vermeiden zu viel essen." Ich hoffe, dass diese Analyse allen helfen kann, den Modellzusammenbruch besser zu verstehen und zu einer gesunden Entwicklung der KI beizutragen.