Der Herausgeber von Downcodes erfuhr, dass Wissenschaftler von Meta, der University of California, Berkeley und der New York University gemeinsam eine neue Technologie namens „Thinking Preference Optimization“ (TPO) entwickelt haben, die darauf abzielt, die Leistung großer Sprachmodelle (LLMs) zu verbessern. Diese Technologie verbessert die „Denk“-Fähigkeit der KI, indem sie es dem Modell ermöglicht, vor der Beantwortung einer Frage eine Reihe von Denkschritten zu generieren, und das Bewertungsmodell verwendet, um die Qualität der endgültigen Antwort zu optimieren, sodass sie bei verschiedenen Aufgaben bessere Leistungen erbringen kann. Anders als die traditionelle „Kettendenken“-Technologie verfügt TPO über ein breiteres Anwendungsspektrum und weist insbesondere erhebliche Vorteile beim kreativen Schreiben, beim Denken mit gesundem Menschenverstand usw. auf.
Kürzlich haben Wissenschaftler von Meta, der University of California, Berkeley und der New York University gemeinsam eine neue Technologie namens Thought Preference Optimization (TPO) entwickelt. Ziel dieser Technologie ist es, die Leistung großer Sprachmodelle (LLMs) bei der Ausführung verschiedener Aufgaben zu verbessern, sodass die KI ihre Antworten vor der Beantwortung sorgfältiger prüfen kann.
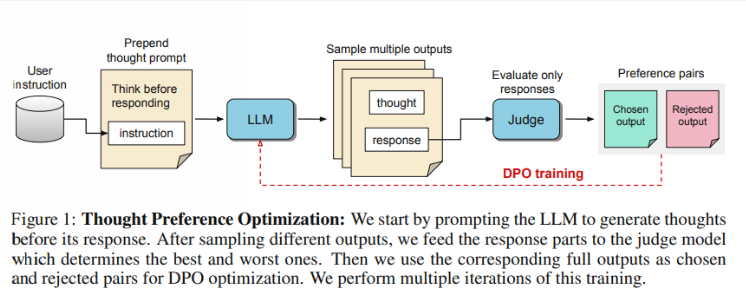
Forscher sagen, dass Denken einen breiten Nutzen haben sollte. Beispielsweise kann KI bei kreativen Schreibaufgaben interne Denkprozesse nutzen, um die Gesamtstruktur und Charakterentwicklung zu planen. Diese Methode unterscheidet sich deutlich von der bisherigen „Chain-of-Thought“ (CoT)-Prompting-Technologie. Letzteres wird hauptsächlich bei mathematischen und logischen Aufgaben verwendet, während TPO ein breiteres Anwendungsspektrum hat. Die Forscher erwähnten das neue o1-Modell von OpenAI und glauben, dass der Denkprozess auch für ein breiteres Aufgabenspektrum hilfreich ist.
Wie funktioniert TPO? Zunächst generiert das Modell eine Reihe von Denkschritten, bevor eine Frage beantwortet wird. Als nächstes werden mehrere Ausgaben erstellt, die dann von einem Bewertungsmodell nur anhand der endgültigen Antwort bewertet werden, nicht anhand der Gedankenschritte selbst. Abschließend wird das Modell durch Präferenzoptimierung dieser Bewertungsergebnisse trainiert. Die Forscher hoffen, dass eine Verbesserung der Qualität der Antworten durch eine Verbesserung des Denkprozesses erreicht werden kann, sodass das Modell beim impliziten Lernen effektivere Argumentationsfähigkeiten erlangen kann.
Beim Testen schnitt das Llama38B-Modell mit TPO bei einem Benchmark mit allgemeiner Anweisung besser ab als eine Version ohne explizite Inferenz. In den Benchmarks AlpacaEval und Arena-Hard erreichten die Gewinnquoten von TPO 52,5 % bzw. 37,3 %. Noch aufregender ist, dass TPO auch in Bereichen Fortschritte macht, die normalerweise kein explizites Denken erfordern, wie etwa gesunder Menschenverstand, Marketing und Gesundheit.
Das Forschungsteam stellte jedoch fest, dass der aktuelle Aufbau für mathematische Probleme nicht geeignet ist, da TPO bei diesen Aufgaben tatsächlich schlechter abschneidet als das Basismodell. Dies deutet darauf hin, dass für hochspezialisierte Aufgaben möglicherweise ein anderer Ansatz erforderlich ist. Zukünftige Forschung könnte sich auf Aspekte wie die Längenkontrolle von Denkprozessen und die Auswirkungen des Denkens auf größere Modelle konzentrieren.
Highlight:
Das Forschungsteam startete „Thinking Preference Optimization“ (TPO), das darauf abzielt, die Denkfähigkeit der KI bei der Aufgabenausführung zu verbessern.
?TPO verwendet Bewertungsmodelle, um die Antwortqualität zu optimieren, indem das Modell vor der Antwort Denkschritte generieren lässt.
Tests haben gezeigt, dass TPOs in Bereichen wie Allgemeinwissen und Marketing gut abschneiden, bei Mathematikaufgaben jedoch schlecht abschneiden.
Alles in allem bietet die TPO-Technologie eine neue Richtung für die Verbesserung großer Sprachmodelle, und es lohnt sich, auf ihr Potenzial zur Verbesserung der KI-Denkfähigkeiten zu blicken. Allerdings weist diese Technologie auch Einschränkungen auf, und künftige Forschung muss ihren Anwendungsbereich weiter verbessern und erweitern. Der Herausgeber von Downcodes wird die neuesten Entwicklungen in diesem Bereich weiterhin im Auge behalten und den Lesern weitere spannende Berichte bringen.