OpenAI hat ein auffälliges neues Modell gpt-4o-audio-preview veröffentlicht, das bedeutende Durchbrüche im Bereich der Sprachgenerierung und -analyse erzielt und Benutzern ein natürlicheres und intelligenteres Sprachinteraktionserlebnis bietet. Der Herausgeber von Downcodes vermittelt Ihnen ein tiefgreifendes Verständnis der Kernfunktionen, Anwendungsszenarien und Preisstrategien dieses Modells und analysiert seine möglichen Auswirkungen auf verschiedene Branchen.
OpenAI führt erneut den Trend der künstlichen Intelligenztechnologie an und bringt ein neues gpt-4o-audio-preview-Modell auf den Markt. Dieses Modell demonstriert nicht nur erstaunliche Fähigkeiten bei der Spracherzeugung und -analyse, sondern eröffnet auch neue Möglichkeiten für die Mensch-Computer-Interaktion. Werfen wir einen genaueren Blick auf die Merkmale dieses innovativen Modells und seine möglichen Anwendungen.
Die Kernfunktionen von gpt-4o-audio-preview umfassen drei Hauptaspekte: Erstens kann es natürliche und flüssige Sprachantworten auf Textbasis generieren und bietet so eine starke Unterstützung für Anwendungen wie Sprachassistenten und virtuellen Kundenservice. Zweitens verfügt das Modell über die Fähigkeit, Emotionen, Intonation und Tonhöhe von Audioeingaben zu analysieren, was breite Anwendungsaussichten in den Bereichen Affective Computing und User Experience-Analyse bietet. Schließlich unterstützt es die Voice-to-Voice-Interaktion, bei der Audio sowohl als Eingabe als auch als Ausgabe verwendet werden kann, und legt damit den Grundstein für eine umfassende Palette von Sprachinteraktionssystemen.
Im Vergleich zur bestehenden Echtzeit-API von OpenAI konzentriert sich gpt-4o-audio-preview mehr auf die Details der Sprachverarbeitung. Es zeichnet sich durch Sprachgenerierung, Stimmungsanalyse und Sprachinteraktion aus, wobei ein besonderer Schwerpunkt auf der Verarbeitung subtiler Merkmale wie Intonation und Emotionen liegt. Im Gegensatz dazu konzentriert sich Realtime API mehr auf die Datenverarbeitung in Echtzeit und eignet sich für Szenarien, die sofortiges Feedback erfordern, wie z. B. Echtzeit-Sprache-zu-Text oder Echtzeit-Übersetzung und andere kontinuierlich interaktive Anwendungen.
Die Flexibilität von gpt-4o-audio-preview spiegelt sich in der Unterstützung mehrerer Moduskombinationen wider. Benutzer können die Texteingabe auswählen, um eine Text- und Audioausgabe zu generieren, oder die Audioeingabe verwenden, um eine Text- und Sprachausgabe zu erhalten. Darüber hinaus unterstützt es auch die Audio-zu-Text-Konvertierung und gemischte Eingabemodi und bietet Entwicklern umfangreiche Optionen.
Bezüglich der Preisgestaltung setzt OpenAI auf ein tokenbasiertes Abrechnungsmodell. Der Preis für die Texteingabe ist mit etwa 5 US-Dollar pro Million Token relativ niedrig. Die Textausgabe ist mit etwa 15 US-Dollar pro Million Token etwas höher. Die Kosten für die Audioverarbeitung sind relativ hoch: Die Eingabe kostet 100 US-Dollar pro Million Token (ungefähr 0,06 US-Dollar pro Minute), während die Audioausgabe 200 US-Dollar pro Million Token (ungefähr 0,24 US-Dollar pro Minute) erreicht. Diese Preisstrategie spiegelt die Komplexität und den Rechenressourcenbedarf der Audioverarbeitung wider.
Die Einführung von gpt-4o-audio-preview wird zweifellos transformative Auswirkungen auf mehrere Branchen haben. Im Bereich Kundenservice kann es für ein natürlicheres und emotionaleres Sprachinteraktionserlebnis sorgen. In der Bildungsbranche kann diese Technologie zur Entwicklung intelligenter Sprachlernassistenten eingesetzt werden, die Schülern dabei helfen, ihre Aussprache und Intonation zu verbessern. In der Unterhaltungsindustrie wird damit eine realistischere Sprachsynthese und Interaktion mit virtuellen Charakteren erwartet. Darüber hinaus bietet gpt-4o-audio-preview im Hinblick auf die unterstützende Technologie möglicherweise genauere Sprach-zu-Text-Dienste für Hörgeschädigte oder umfassendere Sprachbeschreibungen für Sehbehinderte.
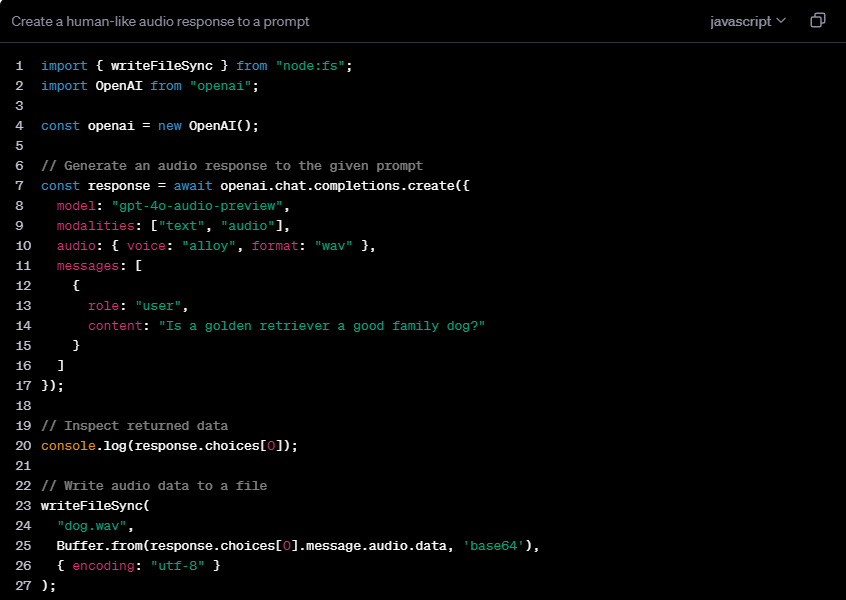
Details: https://platform.openai.com/docs/guides/audio/quickstart
Alles in allem markiert das Aufkommen des gpt-4o-audio-preview-Modells eine neue Stufe in der Technologie der künstlichen Sprachintelligenz. Seine leistungsstarken Funktionen und breiten Anwendungsaussichten werden revolutionäre Veränderungen für die zukünftigen Methoden der Mensch-Computer-Interaktion mit sich bringen. Der Herausgeber von Downcodes freut sich auf weitere innovative Anwendungen, die auf diesem Modell basieren.