Der Herausgeber von Downcodes informiert Sie über die neuesten Forschungsergebnisse der Eidgenössischen Technischen Hochschule in Lausanne (EPFL)! Diese Studie bietet einen detaillierten Vergleich zweier gängiger adaptiver Trainingsmethoden für große Sprachmodelle (LLM): kontextuelles Lernen (ICL) und Instruction Fine-Tuning (IFT) und verwendet den MT-Bench-Benchmark, um die Fähigkeit des Modells zu bewerten Anweisungen. Die Forschungsergebnisse zeigen, dass die beiden Methoden in unterschiedlichen Szenarien ihre eigenen Vorzüge haben und wertvolle Hinweise für die Auswahl von LLM-Trainingsmethoden liefern.
Eine aktuelle Studie der Ecole Polytechnique Fédérale de Lausanne (EPFL) in der Schweiz verglich zwei gängige adaptive Trainingsmethoden für große Sprachmodelle (LLM): kontextuelles Lernen (ICL) und Instruction Fine-Tuning (IFT). Die Forscher verwendeten den MT-Bench-Benchmark, um die Fähigkeit eines Modells, Anweisungen zu befolgen, zu bewerten und stellten fest, dass beide Methoden unter bestimmten Umständen besser und schlechter abschnitten.
Untersuchungen haben ergeben, dass die Auswirkungen von ICL und IFT sehr ähnlich sind, wenn die Anzahl der verfügbaren Trainingsbeispiele gering ist (z. B. nicht mehr als 50). Dies deutet darauf hin, dass ICL eine Alternative zum IFT sein könnte, wenn die Daten begrenzt sind.
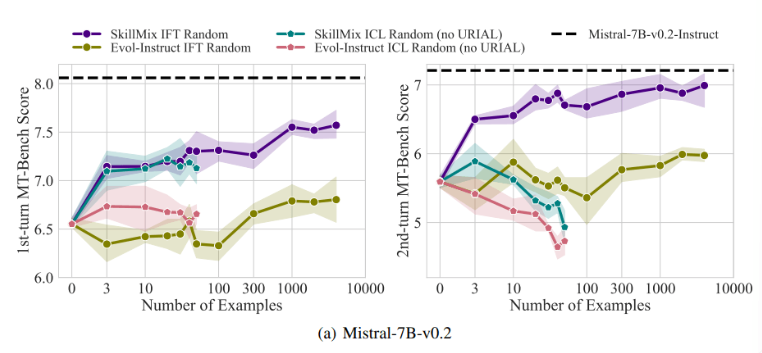
Mit zunehmender Aufgabenkomplexität, beispielsweise in Dialogszenarien mit mehreren Runden, werden die Vorteile von IFT jedoch deutlich. Die Forscher glauben, dass das ICL-Modell dazu neigt, sich übermäßig an den Stil einer einzelnen Stichprobe anzupassen, was zu einer schlechten Leistung bei der Bearbeitung komplexer Konversationen oder sogar zu einer schlechteren Leistung als das Basismodell führt.
Die Studie untersuchte auch die URIAL-Methode, die nur drei Beispiele und Anweisungen verwendet, um Regeln zum Trainieren eines Basissprachmodells zu befolgen. Obwohl URIAL bestimmte Ergebnisse erzielt hat, besteht immer noch eine Lücke im Vergleich zu dem von IFT trainierten Modell. EPFL-Forscher verbesserten die Leistung von URIAL, indem sie die Stichprobenauswahlstrategie verbesserten und es so an die Feinabstimmung von Modellen heranführten. Dies unterstreicht die Bedeutung hochwertiger Trainingsdaten für ICL, IFT und grundlegendes Modelltraining.
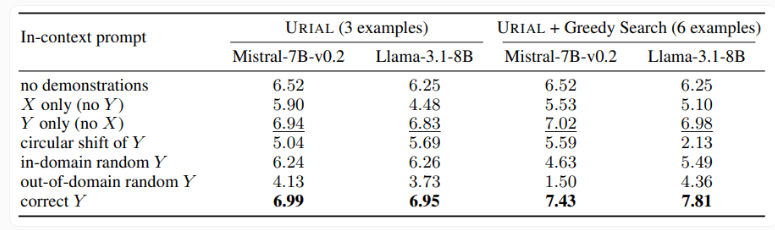
Darüber hinaus ergab die Studie, dass Decodierungsparameter einen erheblichen Einfluss auf die Modellleistung haben. Diese Parameter bestimmen, wie das Modell Text generiert und sind sowohl für grundlegendes LLM als auch für mit URIAL trainierte Modelle von entscheidender Bedeutung.
Die Forscher weisen darauf hin, dass selbst das Basismodell bei geeigneten Dekodierungsparametern bis zu einem gewissen Grad Anweisungen befolgen kann.
Die Bedeutung dieser Studie besteht darin, dass sie zeigt, dass kontextuelles Lernen Sprachmodelle schnell und effizient optimieren kann, insbesondere wenn die Trainingsstichproben begrenzt sind. Aber für komplexe Aufgaben wie Gespräche mit mehreren Runden ist die Feinabstimmung der Befehle immer noch die bessere Wahl.
Mit zunehmender Größe des Datensatzes wird sich die Leistung von IFT weiter verbessern, während sich die Leistung von ICL nach Erreichen einer bestimmten Anzahl von Stichproben stabilisiert. Die Forscher betonen, dass die Wahl zwischen ICL und IFT von einer Vielzahl von Faktoren abhängt, etwa den verfügbaren Ressourcen, dem Datenvolumen und den spezifischen Anwendungsanforderungen. Für welche Methode Sie sich auch entscheiden, qualitativ hochwertige Trainingsdaten sind entscheidend.
Insgesamt liefert diese EPFL-Studie neue Erkenntnisse zur Auswahl von Trainingsmethoden für große Sprachmodelle und weist den Weg für zukünftige Forschungsrichtungen. Die Wahl von ICL oder IFT erfordert das Abwägen der Vor- und Nachteile auf der Grundlage der spezifischen Situation, und qualitativ hochwertige Daten sind immer der Schlüssel. Wir hoffen, dass diese Forschung allen helfen kann, große Sprachmodelle besser zu verstehen und anzuwenden.