Der Herausgeber von Downcodes führt Sie zu Emu3, dem neuesten multimodalen Weltmodell, das vom Zhiyuan Research Institute veröffentlicht wurde! Emu3 verlässt sich auf seine einzigartige Fähigkeit zur „Nächsten-Token-Vorhersage“, um bahnbrechende Verständnis- und Generierungsfunktionen in drei Modalitäten zu erreichen: Text, Bild und Video. Es kann nicht nur qualitativ hochwertige Bilder und flüssige und natürliche Videos erzeugen, sondern auch ein genaues Bildverständnis und eine Videovorhersage durchführen. Seine Leistung übertrifft die vieler bekannter Open-Source-Modelle. Der Open-Source-Charakter von Emu3 verleiht der Entwicklung multimodaler KI auch neue Dynamik. Lassen Sie uns die technologische Innovation und das zukünftige Potenzial dahinter erkunden.
Das Zhiyuan Research Institute hat sein multimodales Weltmodell Emu3 offiziell veröffentlicht. Das größte Highlight dieses Modells ist, dass es den nächsten Token in drei verschiedenen Modi vorhersagen kann: Text, Bild und Video.

Was die Bilderzeugung betrifft, ist Emu3 in der Lage, qualitativ hochwertige Bilder basierend auf der visuellen Token-Vorhersage zu generieren. Das bedeutet, dass Benutzer flexible Auflösungen und eine Vielfalt an Stilen erwarten können.

Im Hinblick auf die Videogenerierung funktioniert Emu3 auf völlig neue Weise. Im Gegensatz zu anderen Modellen, die Videos durch Rauschen erzeugen, generiert Emu3 Videos direkt durch sequentielle Vorhersage. Dieser technologische Fortschritt macht die Videoerzeugung flüssiger und natürlicher.

Bei Aufgaben wie Bildgenerierung, Videogenerierung und visuellem Sprachverständnis übertrifft die Leistung von Emu3 die vieler bekannter Open-Source-Modelle wie SDXL, LLaVA und OpenSora. Dahinter verbirgt sich ein leistungsstarker visueller Tokenizer, der Videos und Bilder in diskrete Token umwandeln kann. Dieses Design bietet neue Ideen für die einheitliche Verarbeitung von Text, Bildern und Videos.
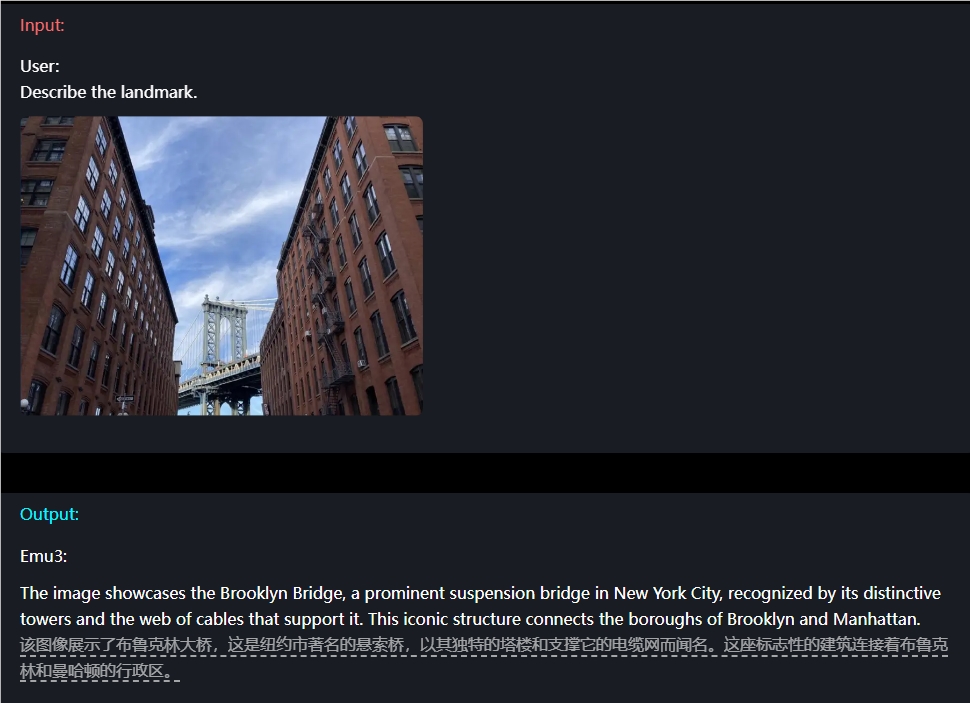
In Bezug auf das Bildverständnis müssen Benutzer beispielsweise nur eine Frage eingeben, und Emu3 kann den Bildinhalt genau beschreiben.
Emu3 verfügt auch über Videovorhersagefunktionen. Wenn Emu3 ein Video erhält, kann es anhand vorhandener Inhalte vorhersagen, was als nächstes passieren wird. Dadurch kann es starke Fähigkeiten bei der Simulation von Umgebungen sowie menschlichem und tierischem Verhalten unter Beweis stellen und den Benutzern ein realistischeres interaktives Erlebnis ermöglichen.

Darüber hinaus ist die Designflexibilität von Emu3 erfrischend. Es kann direkt anhand menschlicher Vorlieben optimiert werden, sodass der generierte Inhalt besser den Benutzererwartungen entspricht. Darüber hinaus hat Emu3 als Open-Source-Modell heftige Diskussionen in der technischen Community ausgelöst. Viele Menschen glauben, dass diese Errungenschaft das Entwicklungsmuster der multimodalen KI völlig verändern wird.
Projekt-URL: https://emu.baai.ac.cn/about
Papier: https://arxiv.org/pdf/2409.18869
Highlight:
Emu3 realisiert das multimodale Verständnis und die Generierung von Text, Bildern und Videos durch die Vorhersage des nächsten Tokens.
Bei mehreren Aufgaben übertraf die Leistung von Emu3 die vieler bekannter Open-Source-Modelle und demonstrierte damit seine leistungsstarken Fähigkeiten.
Das flexible Design und die Open-Source-Funktionen von Emu3 bieten Entwicklern neue Möglichkeiten und sollen die Innovation und Entwicklung multimodaler KI fördern.
Die Entstehung von Emu3 markiert einen neuen Meilenstein im Bereich der multimodalen KI. Seine leistungsstarke Leistung, sein flexibles Design und seine Open-Source-Funktionen werden zweifellos tiefgreifende Auswirkungen auf die zukünftige Entwicklung der KI haben. Wir freuen uns darauf, dass Emu3 in weiteren Bereichen eingesetzt wird und der Menschheit mehr Komfort und Überraschungen bringt!