Der Herausgeber von Downcodes erfuhr, dass das Beijing Zhiyuan Artificial Intelligence Research Institute mit mehreren Universitäten zusammengearbeitet hat, um ein großes Modell für das Verständnis ultralanger Videos namens Video-XL auf den Markt zu bringen. Das Modell schneidet bei der Verarbeitung langer Videos von mehr als zehn Minuten gut ab, erreicht Spitzenplätze in mehreren Benchmarks und demonstriert starke Generalisierungsfähigkeiten und Verarbeitungseffizienz. Video-XL verwendet Sprachmodelle, um lange visuelle Sequenzen zu komprimieren und erreicht eine Genauigkeit von fast 95 % bei Aufgaben wie „Die Suche nach einer Nadel im Heuhaufen“. Zur Verarbeitung von 2048 Eingabebildern ist lediglich eine Grafikkarte mit 80 GB Videospeicher erforderlich. Die offene Quelle dieses Modells wird die Zusammenarbeit und Entwicklung der globalen multimodalen Videoverständnis-Forschungsgemeinschaft fördern.
Das Beijing Zhiyuan Artificial Intelligence Research Institute hat sich mit Universitäten wie der Shanghai Jiao Tong University, der Renmin University of China, der Peking University und der Beijing University of Posts and Telecommunications zusammengetan, um ein großes Modell zum Verstehen ultralanger Videos namens Video-XL auf den Markt zu bringen. Dieses Modell ist eine wichtige Demonstration der Kernfähigkeiten multimodaler großer Modelle und ein wichtiger Schritt in Richtung allgemeiner künstlicher Intelligenz (AGI). Im Vergleich zu bestehenden multimodalen Großmodellen zeigt Video-XL eine bessere Leistung und Effizienz bei der Verarbeitung langer Videos von mehr als 10 Minuten.

Video-XL nutzt die nativen Fähigkeiten von Sprachmodellen (LLM), um lange visuelle Sequenzen zu komprimieren, behält die Fähigkeit, kurze Videos zu verstehen, und zeigt hervorragende Generalisierungsfähigkeiten beim Verstehen langer Videos. Dieses Modell belegt bei mehreren Aufgaben den ersten Platz in mehreren Mainstream-Benchmarks zum Verständnis langer Videos. Video-XL erreicht ein gutes Gleichgewicht zwischen Effizienz und Leistung. Es benötigt lediglich eine Grafikkarte mit 80G-Videospeicher, um 2048 Frame-Eingaben zu verarbeiten, stundenlange Videos abzutasten und bei der Video-„Nadel im Heuhaufen“-Aufgabe fast 95 % zu erreichen. % Genauigkeit.
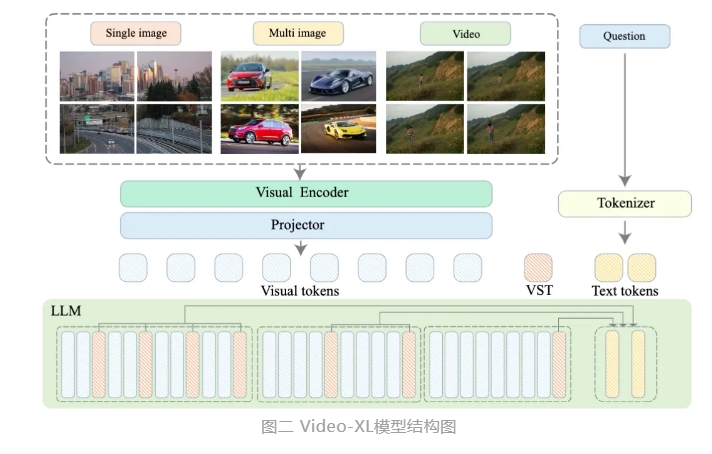
Es wird erwartet, dass Video-XL in Anwendungsszenarien wie der Zusammenfassung von Filmen, der Erkennung von Videoanomalien und der Erkennung von Anzeigenplatzierungen einen umfassenden Anwendungswert zeigt und zu einem leistungsstarken Assistenten für das Verständnis langer Videos wird. Die Einführung dieses Modells stellt einen wichtigen Schritt in der Effizienz und Genauigkeit der Technologie zum Verstehen langer Videos dar und bietet starke technische Unterstützung für die automatisierte Verarbeitung und Analyse langer Videoinhalte in der Zukunft.
Derzeit ist der Modellcode von Video-XL als Open Source verfügbar, um die Zusammenarbeit und den Technologieaustausch in der globalen multimodalen Videoverständnis-Forschungsgemeinschaft zu fördern.
Titel des Papiers: Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Link zum Papier: https://arxiv.org/abs/2409.14485
Modelllink: https://huggingface.co/sy1998/Video_XL
Projektlink: https://github.com/VectorSpaceLab/Video-XL
Die offene Quelle von Video-XL eröffnet der Forschung und Anwendung im Bereich des Langvideoverständnisses neue Möglichkeiten. Seine Effizienz und Genauigkeit werden die Weiterentwicklung verwandter Technologien fördern und in Zukunft technische Unterstützung für weitere Anwendungsszenarien bieten. Wir freuen uns darauf, in Zukunft weitere innovative Anwendungen auf Basis von Video-XL zu sehen.