Der Herausgeber von Downcodes stellt Ihnen eine aktuelle Forschung der Technischen Universität Darmstadt in Deutschland vor. In dieser Studie wurde das Bongard-Problem als Testwerkzeug verwendet, um die Leistung des aktuellen, hochmodernen KI-Bildmodells bei einfachen visuellen Denkaufgaben zu bewerten. Die Forschungsergebnisse sind überraschend, selbst die Genauigkeit von multimodalen Spitzenmodellen wie GPT-4o ist weitaus geringer als erwartet, was eine tiefgreifende Reflexion über die bestehenden Standards zur Bewertung der visuellen KI-Fähigkeiten auslöst.
Die neueste Forschung der Technischen Universität Darmstadt in Deutschland zeigt ein Phänomen, das zum Nachdenken anregt: Selbst die fortschrittlichsten KI-Bildmodelle können bei einfachen visuellen Denkaufgaben erhebliche Fehler machen. Die Ergebnisse dieser Forschung bringen neue Überlegungen zu den Bewertungsstandards der visuellen Fähigkeiten der KI hervor.
Als Testinstrument nutzte das Forschungsteam das vom russischen Wissenschaftler Michail Bongard entwickelte Bongard-Problem. Diese Art von visuellem Puzzle besteht aus 12 einfachen Bildern, die in zwei Gruppen unterteilt sind, und erfordert die Identifizierung der Regeln, die die beiden Gruppen unterscheiden. Diese Aufgabe des abstrakten Denkens ist für die meisten Menschen nicht schwierig, aber die Leistung des KI-Modells war überraschend.
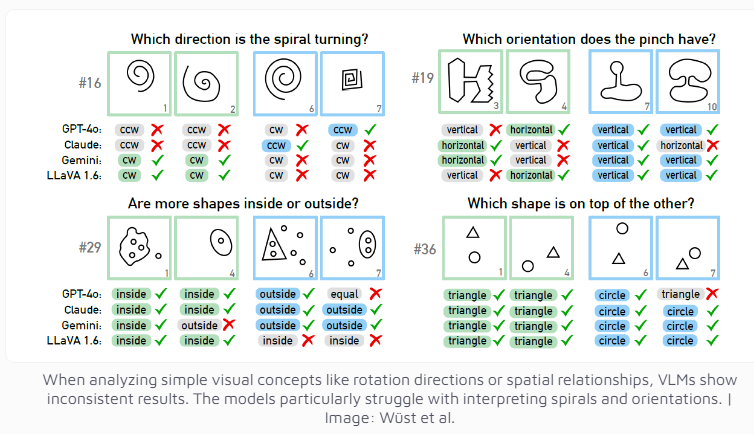
Selbst das multimodale Modell GPT-4o, das derzeit als das fortschrittlichste gilt, löste nur 21 von 100 visuellen Rätseln erfolgreich. Die Leistung anderer bekannter KI-Modelle wie Claude, Gemini und LLaVA ist noch weniger zufriedenstellend. Diese Modelle weisen erhebliche Schwierigkeiten bei der Identifizierung grundlegender visueller Konzepte wie vertikaler und horizontaler Linien oder der Beurteilung der Richtung einer Spirale auf.
Die Forscher stellten fest, dass sich die Leistung des KI-Modells selbst bei Bereitstellung mehrerer Auswahlmöglichkeiten nur geringfügig verbesserte. Nur unter strenger Beschränkung der Anzahl möglicher Antworten konnten GPT-4 und Claude ihre Erfolgsquote auf 68 bzw. 69 Rätsel verbessern. Durch eine eingehende Analyse von vier spezifischen Fällen stellte das Forschungsteam fest, dass KI-Systeme manchmal Probleme auf der Ebene der grundlegenden visuellen Wahrnehmung haben, bevor sie die Phase des Denkens und Denkens erreichen, die spezifischen Gründe jedoch immer noch schwer zu bestimmen sind.
Diese Forschung regt auch zum Nachdenken über die Bewertungskriterien von KI-Systemen an. Das Forschungsteam wies darauf hin: Warum schneiden visuelle Sprachmodelle bei etablierten Benchmarks gut ab, haben aber Probleme mit dem scheinbar einfachen Bongard-Problem? Wie aussagekräftig sind diese Benchmarks bei der Bewertung realer Denkfähigkeiten? Möglicherweise muss es neu gestaltet werden, um die visuellen Denkfähigkeiten der KI genauer zu messen.
Diese Forschung zeigt nicht nur die Grenzen der aktuellen KI-Technologie auf, sondern weist auch den Weg für die zukünftige Entwicklung der visuellen Fähigkeiten der KI. Es erinnert uns daran, dass wir zwar den schnellen Fortschritt der KI bejubeln, uns aber auch klar darüber im Klaren sein müssen, dass es bei den grundlegenden kognitiven Fähigkeiten der KI noch Raum für Verbesserungen gibt.
Diese Forschung zeigt deutlich, dass KI-Modelle beim visuellen Denken noch viel Raum für Verbesserungen haben und dass in Zukunft effektivere Bewertungsmethoden und technologische Durchbrüche erforderlich sind, um die kognitiven Fähigkeiten der KI zu verbessern. Der Herausgeber von Downcodes wird weiterhin auf die bahnbrechenden Fortschritte im Bereich KI achten und Ihnen weitere spannende Berichte bringen.