Große Sprachmodelle (LLMs) werden immer häufiger verwendet, ihre große Anzahl an Parametern bringt jedoch einen enormen Bedarf an Rechenressourcen mit sich. Um dieses Problem zu lösen und die Effizienz und Genauigkeit des Modells in verschiedenen Ressourcenumgebungen zu verbessern, erforschen Forscher weiterhin neue Methoden. In diesem Artikel wird das von Forschern von NVIDIA und der University of Texas in Austin gemeinsam entwickelte Flextron-Framework vorgestellt, das eine flexible Bereitstellung von KI-Modellen ohne zusätzliche Feinabstimmung ermöglicht und die Ineffizienzprobleme herkömmlicher Methoden effektiv löst. Der Herausgeber von Downcodes wird die Neuerungen des Flextron-Frameworks und seine Vorteile in ressourcenbeschränkten Umgebungen ausführlich erläutern.
Im Bereich der künstlichen Intelligenz haben große Sprachmodelle (LLMs) wie GPT-3 und Llama-2 erhebliche Fortschritte gemacht und können menschliche Sprache genau verstehen und erzeugen. Aufgrund der großen Anzahl von Parametern dieser Modelle erfordern sie jedoch während des Trainings und der Bereitstellung große Rechenressourcen, was in Umgebungen mit begrenzten Ressourcen eine Herausforderung darstellt.
Papiereingang: https://arxiv.org/html/2406.10260v1
Um bei unterschiedlichen Rechenressourceneinschränkungen ein Gleichgewicht zwischen Effizienz und Genauigkeit zu erreichen, müssen Forscher traditionell mehrere verschiedene Versionen des Modells trainieren. Beispielsweise umfasst die Llama-2-Modellfamilie verschiedene Varianten mit 7 Milliarden, 1,3 Milliarden und 700 Millionen Parametern. Allerdings erfordert diese Methode große Mengen an Daten und Rechenressourcen und ist nicht sehr effizient.
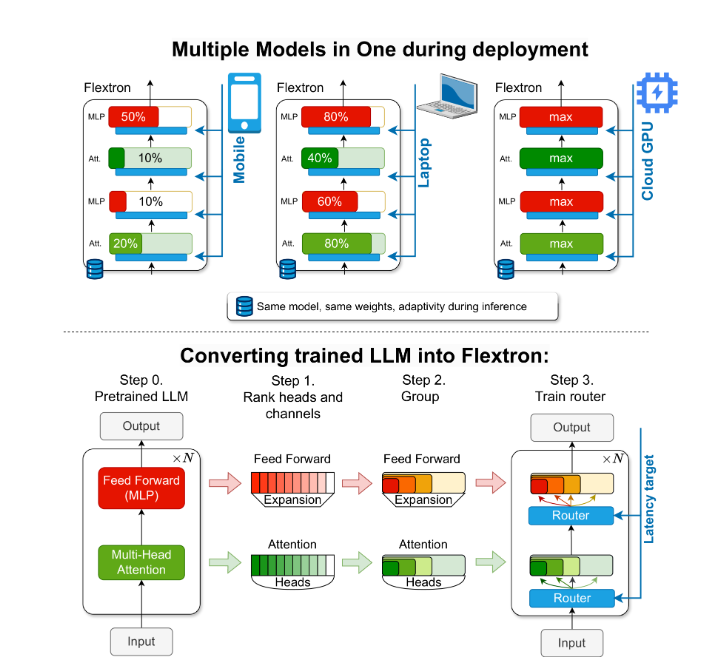
Um dieses Problem zu lösen, führten Forscher von NVIDIA und der University of Texas in Austin das Flextron-Framework ein. Flextron ist eine neuartige flexible Modellarchitektur und ein Post-Training-Optimierungsframework, das die adaptive Bereitstellung von Modellen ohne die Notwendigkeit einer zusätzlichen Feinabstimmung unterstützt und so die Ineffizienzprobleme herkömmlicher Methoden löst.
Flextron wandelt vorab trainiertes LLM durch probeneffiziente Trainingsmethoden und fortschrittliche Routing-Algorithmen in elastische Modelle um. Diese Struktur verfügt über ein verschachteltes elastisches Design, das dynamische Anpassungen während der Inferenz ermöglicht, um bestimmte Latenz- und Genauigkeitsziele zu erreichen. Diese Anpassungsfähigkeit ermöglicht die Verwendung eines einzigen vorab trainierten Modells in verschiedenen Bereitstellungsszenarien, wodurch der Bedarf an mehreren Modellvarianten erheblich reduziert wird.
Die Leistungsbewertung von Flextron zeigt, dass es im Vergleich zu mehreren durchgängig trainierten Modellen und anderen hochmodernen elastischen Netzwerken eine bessere Effizienz und Genauigkeit aufweist. Flextron schneidet beispielsweise bei mehreren Benchmarks wie ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU und HellaSwag gut ab und nutzt nur 7,63 % der Trainingsmarker im ursprünglichen Vortraining, wodurch viel Rechenressourcen und Zeit gespart werden .
Das Flextron-Framework umfasst außerdem elastische Mehrschicht-Perzeptron- (MLP) und elastische Mehrkopf-Aufmerksamkeitsschichten (MHA), was seine Anpassungsfähigkeit weiter verbessert. Die elastische MHA-Schicht nutzt effektiv den verfügbaren Speicher und die Verarbeitungsleistung, indem sie eine Teilmenge von Aufmerksamkeitsköpfen basierend auf Eingabedaten auswählt, und eignet sich besonders für Szenarien mit begrenzten Rechenressourcen.
Highlight:
? Das Flextron-Framework unterstützt die flexible Bereitstellung von KI-Modellen ohne zusätzliche Feinabstimmung.
Durch effizientes Probentraining und fortschrittliche Routing-Algorithmen werden Modelleffizienz und -genauigkeit verbessert.
Die elastische Multi-Head-Aufmerksamkeitsschicht optimiert die Ressourcennutzung und eignet sich besonders für Umgebungen mit begrenzten Rechenressourcen.
Dieser Bericht soll Oberstufenschülern die Bedeutung und Innovation des Flextron-Frameworks auf leicht verständliche Weise näherbringen.
Alles in allem bietet das Flextron-Framework eine effiziente und innovative Lösung für das Problem der Bereitstellung großer Sprachmodelle in ressourcenbeschränkten Umgebungen. Seine flexible Architektur und die probeneffiziente Trainingsmethode verschaffen ihm erhebliche Vorteile in der praktischen Anwendung und geben eine neue Richtung für die Weiterentwicklung der Technologie der künstlichen Intelligenz vor. Der Herausgeber von Downcodes hofft, dass dieser Artikel jedem helfen kann, die Kernideen und technischen Beiträge des Flextron-Frameworks besser zu verstehen.