Der Herausgeber von Downcodes führt Sie zu einer innovativen Technologie, die die Effizienz großer Sprachmodelle (LLMs) verbessert – Q-Sparse. Die leistungsstarken Fähigkeiten zur Verarbeitung natürlicher Sprache von LLMs haben viel Aufmerksamkeit erregt, aber ihre hohen Rechenkosten und ihr hoher Speicherbedarf waren schon immer Engpässe bei praktischen Anwendungen. Q-Sparse nutzt eine clevere Sparsifizierungsmethode, um die Inferenzeffizienz deutlich zu verbessern und gleichzeitig die Modellleistung sicherzustellen, was den Weg für die weit verbreitete Anwendung von LLMs ebnet. In diesem Artikel werden die Kerntechnologie, Vorteile und experimentellen Verifizierungsergebnisse von Q-Sparse eingehend untersucht und sein enormes Potenzial zur Verbesserung der Effizienz von LLMs aufgezeigt.
In der Welt der künstlichen Intelligenz sind große Sprachmodelle (LLMs) für ihre überlegenen Fähigkeiten zur Verarbeitung natürlicher Sprache bekannt. Der Einsatz dieser Modelle in praktischen Anwendungen steht jedoch vor großen Herausforderungen, vor allem aufgrund ihres hohen Rechenaufwands und Speicherbedarfs während der Inferenzphase. Um dieses Problem zu lösen, haben Forscher untersucht, wie die Effizienz von LLMs verbessert werden kann. In letzter Zeit hat eine Methode namens Q-Sparse große Aufmerksamkeit erregt.
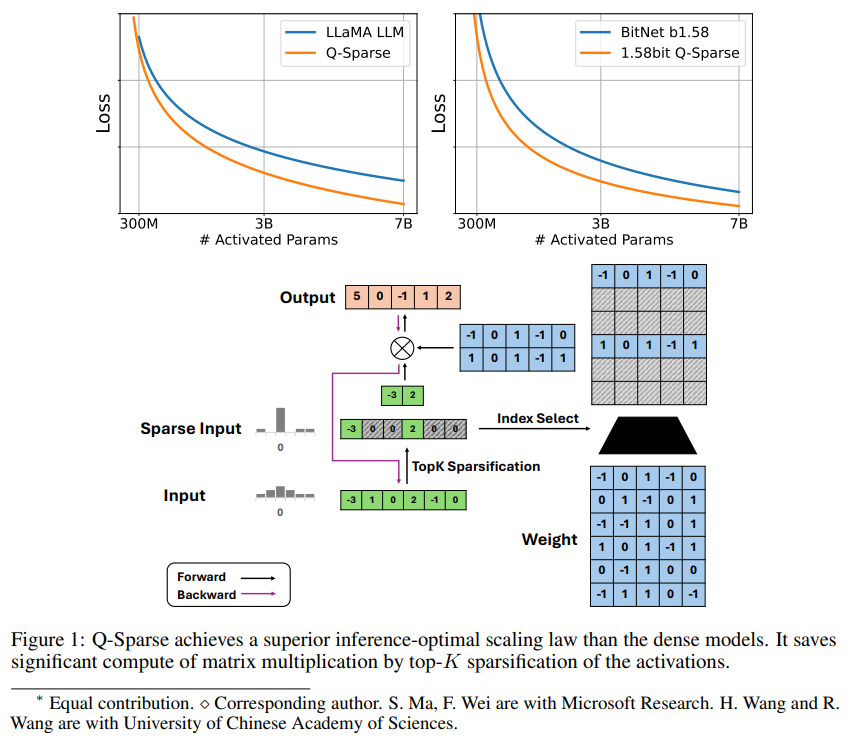
Q-Sparse ist eine einfache, aber effektive Methode, die eine vollständig spärliche Aktivierung von LLMs durch Anwendung der Top-K-Sparsifizierung bei Aktivierungen und eines Pass-Through-Schätzers im Training erreicht. Dies bedeutet erhebliche Effizienzsteigerungen beim Ableiten. Zu den wichtigsten Forschungsergebnissen gehören:
Q-Sparse erreicht eine höhere Inferenzeffizienz und behält gleichzeitig vergleichbare Ergebnisse mit Basis-LLMs bei.
Es wird eine inferenzielle optimale Erweiterungsregel vorgeschlagen, die für LLMs mit geringer Aktivierung geeignet ist.
Q-Sparse funktioniert in verschiedenen Umgebungen, darunter Training von Grund auf, kontinuierliches Training von Standard-LLMs und Feinabstimmung.
Q-Sparse arbeitet mit voller Präzision und 1-Bit-LLMs (z. B. BitNet b1.58).
Vorteile einer spärlichen Aktivierung
Sparsity verbessert die Effizienz von LLMs auf zwei Arten: Erstens kann Sparsity den Berechnungsaufwand für die Matrixmultiplikation reduzieren, da keine Nullelemente berechnet werden. Zweitens kann Sparsity den Umfang der Eingabe-/Ausgabeübertragung (I/O) reduzieren Dies ist der Hauptengpass in der Inferenzphase von LLMs.
Q-Sparse erreicht eine vollständige Sparsität der Aktivierungen, indem es in jeder linearen Projektion eine Top-K-Sparsifizierungsfunktion anwendet. Für die Rückausbreitung wird der Gradient der Aktivierung mithilfe eines Pass-Through-Schätzers berechnet. Darüber hinaus wird die quadrierte ReLU-Funktion eingeführt, um die Sparsität der Aktivierung weiter zu verbessern.
Experimentelle Überprüfung
Die Forscher untersuchten das Expansionsgesetz spärlich aktivierter LLMs durch eine Reihe von Expansionsexperimenten und kamen zu einigen interessanten Erkenntnissen:
Die Leistung von Sparse-Aktivierungsmodellen verbessert sich mit zunehmender Modellgröße und Sparsity-Verhältnis.
Bei einem festen Sparsity-Verhältnis S skaliert die Leistung eines Sparse-Aktivierungsmodells nach dem Potenzgesetz mit der Modellgröße N.
Bei einem festen Parameter N skaliert die Leistung des Sparse-Aktivierungsmodells exponentiell mit dem Sparsity-Verhältnis S.
Q-Sparse kann nicht nur für das Training von Grund auf verwendet werden, sondern auch für das kontinuierliche Training und die Feinabstimmung von Standard-LLMs. In den Einstellungen zum Fortsetzen des Trainings und zur Feinabstimmung verwendeten die Forscher dieselbe Architektur und denselben Trainingsprozess wie beim Training von Grund auf. Der einzige Unterschied bestand darin, das Modell mit vorab trainierten Gewichten zu initialisieren und spärlichen Funktionen die Fortsetzung des Trainings zu ermöglichen.
Forscher untersuchen die Verwendung von Q-Sparse mit 1-Bit-LLMs (wie BitNet b1.58) und gemischten Experten (MoE), um die Effizienz von LLMs weiter zu verbessern. Darüber hinaus arbeiten sie daran, Q-Sparse mit dem Batch-Modus kompatibel zu machen, was mehr Flexibilität für das Training und die Inferenz von LLMs bietet.
Das Aufkommen der Q-Sparse-Technologie liefert neue Ideen zur Lösung des Effizienzproblems von LLMs. Sie bietet ein großes Potenzial zur Reduzierung der Rechenkosten und der Speichernutzung und dürfte die Anwendung von LLMs in weiteren Bereichen fördern. Es wird davon ausgegangen, dass in Zukunft weitere Forschungsergebnisse auf Basis von Q-Sparse entstehen werden, um die Leistung und Effizienz von LLMs weiter zu verbessern.