In den letzten Jahren haben sich multimodale Großmodelle rasant entwickelt und es sind viele hervorragende Modelle entstanden. Die meisten vorhandenen Modelle basieren jedoch auf visuellen Encodern, die unter visuellen Induktionsverzerrungsproblemen leiden, die durch Trainingstrennung verursacht werden und die Effizienz und Leistung einschränken. Der Herausgeber von Downcodes stellt Ihnen ein neues visuelles Sprachmodell vor, das EVE vom Zhiyuan Research Institute in Zusammenarbeit mit Universitäten eingeführt hat. Es verwendet eine codiererlose Architektur und hat in mehreren Benchmark-Tests hervorragende Ergebnisse erzielt, was neue Möglichkeiten für die Entwicklung multimodaler Modelle bietet . Ideen.
In der Erforschung und Anwendung multimodaler Großmodelle wurden in jüngster Zeit erhebliche Fortschritte erzielt. Ausländische Unternehmen wie OpenAI, Google, Microsoft usw. haben eine Reihe fortschrittlicher Modelle auf den Markt gebracht, und inländische Institutionen wie Zhipu AI und Step Star haben auf diesem Gebiet Durchbrüche erzielt. Diese Modelle basieren normalerweise auf visuellen Encodern, um visuelle Merkmale zu extrahieren und sie mit großen Sprachmodellen zu kombinieren. Es gibt jedoch ein Problem der visuellen Induktionsverzerrung, das durch die Trainingstrennung verursacht wird und die Bereitstellungseffizienz und Leistung multimodaler großer Modelle einschränkt.
Um diese Probleme zu lösen, hat das Zhiyuan Research Institute zusammen mit der Dalian University of Technology, der Peking University und anderen Universitäten eine neue Generation des programmiererfreien visuellen Sprachmodells EVE auf den Markt gebracht. EVE integriert visuell-linguistische Darstellung, Ausrichtung und Inferenz durch verfeinerte Trainingsstrategien und zusätzliche visuelle Überwachung in eine einheitliche reine Decoder-Architektur. Unter Verwendung öffentlicher Daten schneidet EVE bei mehreren visuell-linguistischen Benchmarks gut ab und kommt den gängigen Encoder-basierten multimodalen Methoden nahe oder übertrifft diese sogar.
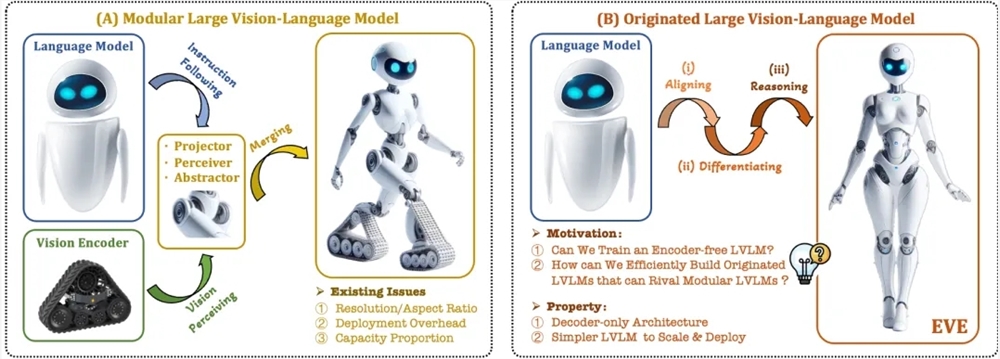
Zu den Hauptmerkmalen von EVE gehören:
Natives visuelles Sprachmodell: Entfernt den visuellen Encoder und verarbeitet jedes Bildseitenverhältnis, was deutlich besser ist als das gleiche Fuyu-8B-Modell.
Geringe Daten- und Schulungskosten: Das Vortraining nutzt öffentliche Daten wie OpenImages, SAM und LAION und die Schulungszeit ist kurz.
Transparente und effiziente Erkundung: Bietet einen effizienten und transparenten Entwicklungspfad für native multimodale Architekturen reiner Decoder.
Modellstruktur:
Patch-Einbettungsschicht: Erhalten Sie die 2D-Feature-Map des Bildes über eine einzelne Faltungsschicht und eine durchschnittliche Pooling-Schicht, um lokale Features und globale Informationen zu verbessern.
Patch-Ausrichtungsschicht: Integrieren Sie mehrschichtige visuelle Netzwerkfunktionen, um eine feinkörnige Ausrichtung mit der visuellen Encoder-Ausgabe zu erreichen.
Trainingsstrategie:
Anhand großer Sprachmodelle geleitete Vortrainingsphase: Herstellung der ersten Verbindung zwischen Vision und Sprache.
Generative Vortrainingsphase: Verbessern Sie die Fähigkeit des Modells, visuell-linguistische Inhalte zu verstehen.
Überwachte Feinabstimmungsphase: Reguliert die Fähigkeit des Modells, Sprachanweisungen zu befolgen und Konversationsmuster zu lernen.
Quantitative Analyse: EVE schneidet in mehreren visuellen Sprachbenchmarks gut ab und ist mit einer Vielzahl gängiger Encoder-basierter visueller Sprachmodelle vergleichbar. Trotz der Herausforderung, genau auf bestimmte Anweisungen zu reagieren, erreicht EVE durch eine effiziente Trainingsstrategie eine Leistung, die mit visuellen Sprachmodellen mit Encoder-Basis vergleichbar ist.
EVE hat das Potenzial von nativen visuellen Sprachmodellen ohne Encoder demonstriert. In Zukunft wird es möglicherweise die Entwicklung multimodaler Modelle durch weitere Leistungsverbesserungen, die Optimierung von Architekturen ohne Encoder und den Aufbau nativer multimodaler Modelle vorantreiben Modelle.
Papieradresse: https://arxiv.org/abs/2406.11832
Projektcode: https://github.com/baaivision/EVE
Modelladresse: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
Alles in allem bietet das Aufkommen des EVE-Modells neue Richtungen und Möglichkeiten für die Entwicklung multimodaler Großmodelle. Seine effiziente Trainingsstrategie und hervorragende Leistung verdienen Aufmerksamkeit. Wir freuen uns darauf, dass das zukünftige EVE-Modell seine leistungsstarken Fähigkeiten in weiteren Bereichen unter Beweis stellen kann.