Bei der Echtzeit-Sprachkommunikation war es schon immer ein technisches Problem, die Klangfarbe des Sprechers zu ändern, ohne Semantik und Prosodie zu beeinträchtigen. Der Herausgeber von Downcodes stellt heute eine bahnbrechende Technologie vor – StreamVC, die die Klangfarbe der Stimme des Sprechers in Echtzeit ändern kann, während der Sprachinhalt und -rhythmus erhalten bleibt. Sie ist für mobile Plattformen geeignet und bietet neue Möglichkeiten für Kommunikation und Stimme. Die geringe Latenz, die hochwertige Sprachsynthese und die Tonhöhenstabilität von StreamVC verschaffen ihm erhebliche Vorteile im Bereich der Echtzeitkommunikation.
In einer Welt der Echtzeitkommunikation, sei es ein Telefonanruf oder eine Videokonferenz, ist Ton für uns ein wichtiges Ausdrucksmittel. Aber haben Sie jemals darüber nachgedacht, was passieren würde, wenn wir die Klangfarbe der Stimme eines Sprechers in Echtzeit ändern könnten, ohne den Inhalt und Rhythmus der Sprache zu beeinflussen? Das Aufkommen der StreamVC-Technologie ermöglicht uns dies?
StreamVC ist eine innovative Sprachkonvertierungslösung, die das Timbre der Zielstimme anpasst und gleichzeitig den Inhalt und die Prosodie der Quellstimme beibehält. Im Gegensatz zu herkömmlichen Methoden erzeugt StreamVC die resultierende Wellenform mit geringer Latenz auf dem Eingangssignal, selbst auf mobilen Plattformen, wodurch es für Echtzeit-Kommunikationsszenarien wie Telefonanrufe und Videokonferenzen sowie für die Sprachanonymisierung in diesen Szenarien geeignet ist.
Technische Highlights:
Echtzeit: StreamVC ist in der Lage, 70,8 Millisekunden Inferenz mit geringer Latenz auf Mobilgeräten durchzuführen.
Hochwertige Sprachsynthese: Nutzen Sie die Architektur und Trainingsstrategie des SoundStream-Neuronal-Audio-Codecs, um eine leichte, hochwertige Sprachsynthese zu erreichen.
Tonhöhenstabilität: Durch die Einführung aufgehellter Grundfrequenzinformationen (f0) wird die Tonhöhenkonsistenz verbessert, ohne dass die Klangfarbeninformationen des Quelllautsprechers verloren gehen.
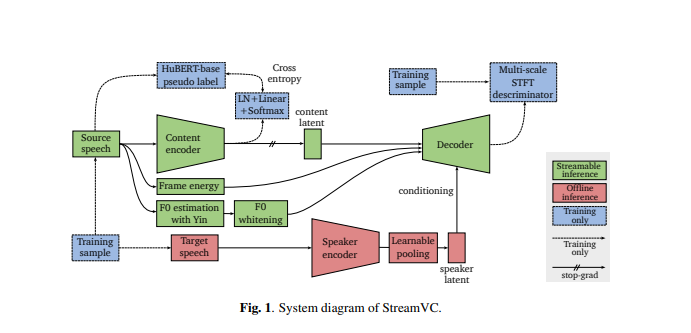
Das Design von StreamVC ist von Soft-VC und SoundStream inspiriert. Es verwendet diskrete Spracheinheiten, die vom HuBERT-Modell extrahiert wurden, als Vorhersageziele für das Content-Encoder-Netzwerk. Die Content-Encoder- und Decoder-Architektur sowie die Trainingsstrategie basieren auf dem neuronalen Audio-Codec SoundStream, um eine qualitativ hochwertige kausale Audiosynthese zu erreichen.
StreamVC wurde anhand mehrerer Benchmarks mit bestehenden Technologien verglichen, darunter Natürlichkeit, Verständlichkeit, Sprecherähnlichkeit und Tonhöhenkonsistenz. Experimentelle Ergebnisse zeigen, dass StreamVC die Tonhöhe der Ausgangssprache gut beibehält und hinsichtlich der Sprecherähnlichkeit mit dem fein abgestimmten Modell vergleichbar ist.
StreamVC beweist, dass eine effiziente Tonkonvertierung mit geringer Latenz auf Mobilgeräten durchaus machbar ist. Von HuBERT abgeleitete Soft-Speech-Einheiten können durch eine streambare kausale neuronale Faltungsnetzwerkarchitektur erlernt werden, und die Einspeisung aufgehellter f0-Informationen in den Decoder ist entscheidend, um eine qualitativ hochwertige Ausgabe zu liefern.
Papieradresse: https://arxiv.org/pdf/2401.03078
Das Aufkommen der StreamVC-Technologie hat neue Möglichkeiten für die Echtzeit-Sprachkommunikation eröffnet. Ihre Sprachkonvertierungsfunktionen mit geringer Latenz und hoher Qualität werden die Anwendung der Sprachtechnologie in mehr Bereichen fördern. Ich glaube, dass StreamVC in Zukunft eine größere Rolle bei der Sprachanonymisierung, Sprachspezialeffekten usw. spielen wird. Wir freuen uns auf weitere innovative Anwendungen auf Basis von StreamVC!