Kürzlich hat das Tencent Artificial Intelligence Laboratory ein neues Modell namens VTA-LDM auf den Markt gebracht, das darauf ausgelegt ist, Videoinhalte effizient in semantisch und zeitlich konsistentes Audio umzuwandeln. Die Kerntechnologie dieses Modells liegt in der „impliziten Ausrichtung“, die den generierten Audio- und Videoinhalt perfekt anpasst und so die Qualität und Anwendungsszenarien der Audioerzeugung erheblich verbessert. Der Herausgeber von Downcodes vermittelt Ihnen ein tiefgreifendes Verständnis der Innovationen und Anwendungsperspektiven des VTA-LDM-Modells.
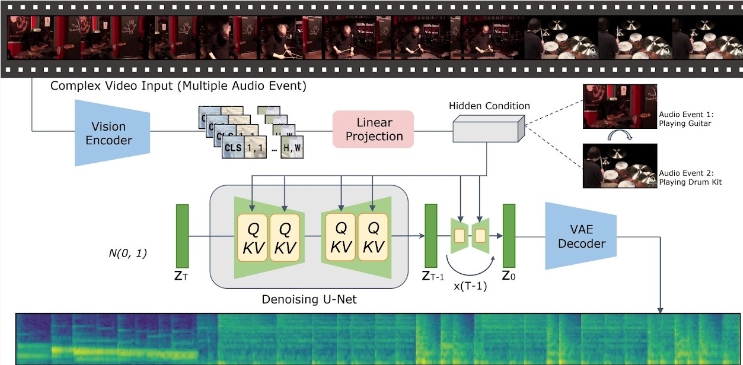
Angesichts der erheblichen Fortschritte in der Technologie zur Text-zu-Video-Generierung ist die Frage, wie semantisch und zeitlich konsistente Audioinhalte aus Videoeingaben generiert werden können, unter Forschern zu einem heißen Thema geworden. Kürzlich hat das Forschungsteam des Tencent Artificial Intelligence Laboratory ein neues Modell namens „Implicitly Aligned Video to Audio Generation“ (VTA-LDM) auf den Markt gebracht, das darauf abzielt, effiziente Lösungen für die Audioerzeugung bereitzustellen.
Projekteingang: https://top.aibase.com/tool/vta-ldm
Die Kernidee des VTA-LDM-Modells besteht darin, die generierten Audio- und Videoinhalte durch implizite Alignment-Technologie semantisch und zeitlich abzugleichen. Diese Methode verbessert nicht nur die Qualität der Audioerzeugung, sondern erweitert auch die Anwendungsszenarien der Videoerzeugungstechnologie. Das Forschungsteam führte eine eingehende Untersuchung des Modelldesigns durch und kombinierte verschiedene technische Mittel, um die Genauigkeit und Konsistenz des erzeugten Audios sicherzustellen.
Die Forschung konzentriert sich auf drei Schlüsselaspekte: visuelle Encoder, zusätzliche Einbettungen und Datenerweiterungstechniken. Das Forschungsteam erstellte zunächst ein Basismodell und führte auf dieser Grundlage eine große Anzahl von Ablationsexperimenten durch, um den Einfluss verschiedener visueller Encoder und Hilfseinbettungen auf den Generierungseffekt zu bewerten. Die Ergebnisse dieser Experimente zeigen, dass das Modell hinsichtlich der Erzeugungsqualität und der gleichzeitigen Ausrichtung von Video und Audio eine gute Leistung erbringt und damit an die Spitze der aktuellen Technologie gelangt.
Was die Inferenz betrifft, müssen Benutzer lediglich die Videoclips in das angegebene Datenverzeichnis legen und das bereitgestellte Inferenzskript ausführen, um den entsprechenden Audioinhalt zu generieren. Das Forschungsteam stellt außerdem eine Reihe von Tools bereit, die Benutzern dabei helfen, das generierte Audio mit dem Originalvideo zusammenzuführen und so den Komfort der Anwendung weiter zu verbessern.
Das VTA-LDM-Modell bietet derzeit mehrere verschiedene Modellversionen, um unterschiedlichen Forschungsanforderungen gerecht zu werden. Diese Modelle umfassen Basismodelle und eine Vielzahl erweiterter Modelle und zielen darauf ab, Benutzern flexible Auswahlmöglichkeiten für die Anpassung an verschiedene Experimente und Anwendungsszenarien zu bieten.
Die Einführung des VTA-LDM-Modells stellt einen wichtigen Fortschritt auf dem Gebiet der Video-zu-Audio-Generierung dar. Forscher hoffen, dieses Modell nutzen zu können, um die Entwicklung verwandter Technologien voranzutreiben und umfassendere Anwendungsmöglichkeiten zu schaffen.
## Highlights:
Das Aufkommen des VTA-LDM-Modells hat neue Durchbrüche im Bereich der Video- und Audioerzeugung gebracht. Seine effizienten und komfortablen Betriebsmethoden und leistungsstarken Funktionen kündigen eine breitere Anwendungsperspektive für die Zukunft an. Man geht davon aus, dass das VTA-LDM-Modell mit der kontinuierlichen Weiterentwicklung der Technologie in immer mehr Bereichen eine wichtige Rolle spielen wird.