Der Herausgeber von Downcodes wird mit Ihnen die Wahrheit über visuelle Sprachmodelle (VLMs) enthüllen! Glauben Sie, dass VLMs Bilder wie Menschen „verstehen“ können? Die Wahrheit ist nicht so einfach. In diesem Artikel werden die Grenzen von VLMs beim Bildverständnis eingehend untersucht und anhand einer Reihe experimenteller Ergebnisse die große Lücke zwischen ihnen und den menschlichen Sehfähigkeiten aufgezeigt. Sind Sie bereit, Ihr Verständnis von VLMs auf den Kopf zu stellen?
Jeder sollte schon einmal von visuellen Sprachmodellen (VLMs) gehört haben. Diese kleinen Experten auf dem Gebiet der KI können nicht nur Texte lesen, sondern auch Bilder „sehen“. Aber das ist nicht der Fall. Schauen wir uns heute ihre „Unterhosen“ an, um zu sehen, ob sie Bilder wirklich „sehen“ und verstehen können wie wir Menschen.
Zunächst muss ich Ihnen einige populärwissenschaftliche Informationen darüber geben, was VLMs sind. Vereinfacht gesagt handelt es sich um große Sprachmodelle wie GPT-4o und Gemini-1.5Pro, die bei der Bild- und Textverarbeitung sehr gute Leistungen erbringen und in vielen visuellen Verständnistests sogar hohe Punktzahlen erzielen. Aber lassen Sie sich von diesen Highscores nicht täuschen, heute werden wir sehen, ob sie wirklich so großartig sind.
Die Forscher entwickelten eine Testreihe namens BlindTest, die sieben Aufgaben enthält, die für Menschen äußerst einfach sind. Bestimmen Sie beispielsweise, ob sich zwei Kreise überlappen, ob sich zwei Linien schneiden, oder zählen Sie, wie viele Kreise das Olympia-Logo enthält. Hört sich an, als könnten diese Aufgaben problemlos von Kindergartenkindern bewältigt werden. Aber lassen Sie mich Ihnen sagen, dass die Leistung dieser VLMs nicht so beeindruckend ist.
Die Ergebnisse sind schockierend. Die durchschnittliche Genauigkeit dieser sogenannten fortgeschrittenen Modelle beträgt bei BlindTest nur 56,20 %, und das beste Sonnet-3.5 hat eine Genauigkeit von 73,77 %. Das ist wie bei einem Top-Studenten, der behauptet, er könne an der Tsinghua-Universität und der Peking-Universität aufgenommen werden, aber es stellt sich heraus, dass er nicht einmal die Matheaufgaben der Grundschule richtig lösen kann.

Warum passiert das? Forscher haben analysiert, dass es daran liegen könnte, dass VLMs bei der Verarbeitung von Bildern einer Kurzsichtigkeit ähneln und Details nicht klar erkennen können. Obwohl sie den Gesamttrend des Bildes grob erkennen können, sind sie verwirrt, wenn es um genaue räumliche Informationen geht, etwa ob sich zwei Grafiken schneiden oder überlappen.
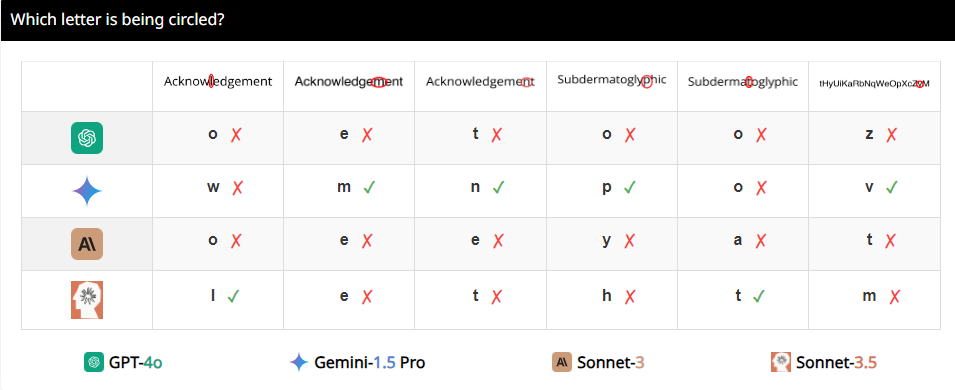
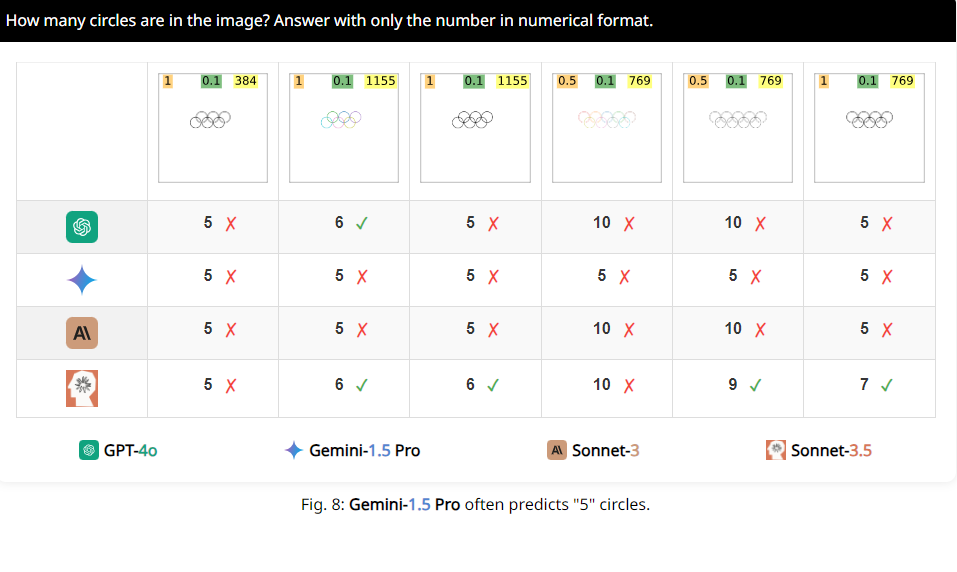
Beispielsweise baten die Forscher VLMs, festzustellen, ob sich zwei Kreise überlappten, und stellten fest, dass diese Modelle die Frage selbst dann nicht 100 % genau beantworten konnten, wenn die beiden Kreise so groß wie Wassermelonen wären. Auch wenn man sie bittet, die Anzahl der Kreise im olympischen Logo zu zählen, ist ihre Leistung schwer zu beschreiben.
Interessanter ist, dass die Forscher auch herausfanden, dass diese VLMs beim Zählen offenbar eine besondere Vorliebe für die Zahl 5 hatten. Wenn beispielsweise die Anzahl der Kreise im Olympia-Logo 5 übersteigt, neigen sie dazu, mit „5“ zu antworten. Dies kann daran liegen, dass das Olympia-Logo 5 Kreise enthält und sie mit dieser Zahl besonders vertraut sind.
Okay, nachdem das alles gesagt ist, habt ihr ein neues Verständnis für diese scheinbar großen VLMs? Tatsächlich weisen sie immer noch viele Einschränkungen im visuellen Verständnis auf, die weit davon entfernt sind, unser menschliches Niveau zu erreichen. Wenn Sie also das nächste Mal jemanden sagen hören, dass KI den Menschen vollständig ersetzen kann, können Sie lachen.
Papieradresse: https://arxiv.org/pdf/2407.06581
Projektseite: https://vlmsareblind.github.io/
Zusammenfassend lässt sich sagen, dass VLMs zwar erhebliche Fortschritte auf dem Gebiet der Bilderkennung gemacht haben, ihre Fähigkeiten im präzisen räumlichen Denken jedoch immer noch große Mängel aufweisen. Diese Studie erinnert uns daran, dass die Bewertung der KI-Technologie nicht nur auf hohen Punktzahlen beruhen kann, sondern auch ein tiefes Verständnis ihrer Grenzen erfordert, um blinden Optimismus zu vermeiden. Wir freuen uns darauf, dass VLMs in Zukunft Durchbrüche beim visuellen Verständnis erzielen werden!