Der Herausgeber von Downcodes führt Sie zu einer bahnbrechenden Forschung von Google DeepMind: Mixture of Experts (MoE). Diese Forschung hat revolutionäre Fortschritte in der Transformer-Architektur gemacht. Ihr Kern liegt in einem Parameter-effizienten Experten-Abrufmechanismus, der Produktschlüsseltechnologie verwendet, um die Rechenkosten und die Anzahl der Parameter auszugleichen und so das Modellpotenzial bei gleichzeitiger Beibehaltung der Effizienz erheblich zu verbessern. Diese Forschung untersucht nicht nur extreme MoE-Einstellungen, sondern beweist auch zum ersten Mal, dass die Struktur des Lernindex effektiv an mehr als eine Million Experten weitergeleitet werden kann, was dem Bereich der KI neue Möglichkeiten eröffnet.
Das von Google DeepMind vorgeschlagene Mixture-Modell mit Millionen von Experten ist eine Forschung, die revolutionäre Schritte in der Transformer-Architektur unternommen hat.
Stellen Sie sich ein Modell vor, das eine spärliche Abfrage von einer Million Mikroexperten durchführen kann. Klingt das ein wenig wie die Handlung eines Science-Fiction-Romans? Aber genau das zeigen die neuesten Untersuchungen von DeepMind. Der Kern dieser Forschung ist ein Parameter-effizienter Experten-Abrufmechanismus, der Produktschlüsseltechnologie nutzt, um die Rechenkosten von der Parameteranzahl zu entkoppeln und so das größere Potenzial der Transformer-Architektur freizusetzen und gleichzeitig die Recheneffizienz aufrechtzuerhalten.
Der Höhepunkt dieser Arbeit besteht darin, dass sie nicht nur extreme MoE-Einstellungen untersucht, sondern auch zum ersten Mal zeigt, dass eine erlernte Indexstruktur effizient an über eine Million Experten weitergeleitet werden kann. Das ist so, als würde man in einer großen Menge schnell ein paar Experten finden, die das Problem lösen können, und das alles unter der Voraussetzung kontrollierbarer Rechenkosten.
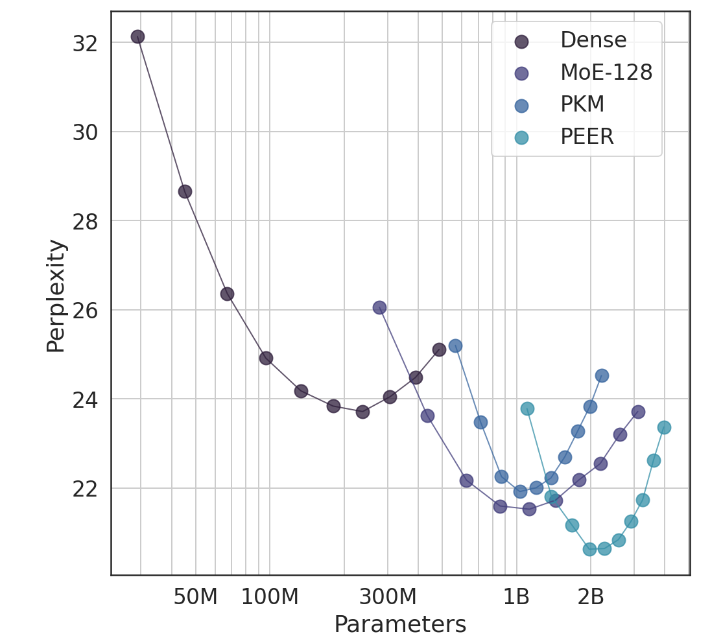
In Experimenten zeigte die PEER-Architektur eine überlegene Rechenleistung und war effizienter als dichte FFW-, grobkörnige MoE- und Product Key Memory (PKM)-Schichten. Dies ist nicht nur ein theoretischer Sieg, sondern auch ein großer Sprung in der praktischen Anwendung. Anhand der empirischen Ergebnisse können wir die überlegene Leistung von PEER bei Sprachmodellierungsaufgaben erkennen. Es weist nicht nur eine geringere Verwirrung auf, sondern auch die Leistung von PEER, indem die Anzahl der Experten und die Anzahl der aktiven Experten angepasst werden Modell wurde deutlich verbessert.
Der Autor dieser Studie, Xu He (Owen), ist Forschungswissenschaftler bei Google DeepMind. Seine alleinige Erforschung hat zweifellos neue Erkenntnisse auf dem Gebiet der KI gebracht. Wie er zeigte, können wir durch personalisierte und intelligente Methoden die Konversionsraten deutlich verbessern und Nutzer binden, was besonders im AIGC-Bereich wichtig ist.
Papieradresse: https://arxiv.org/abs/2407.04153
Insgesamt liefert die Hybridmodellforschung von Google DeepMind neue Ideen für die Konstruktion groß angelegter Sprachmodelle. Der effiziente Expertenabrufmechanismus und die hervorragenden experimentellen Ergebnisse weisen auf großes Potenzial für die zukünftige Entwicklung von KI-Modellen hin. Der Herausgeber von Downcodes freut sich auf weitere ähnliche bahnbrechende Forschungsergebnisse!