Der Herausgeber von Downcodes erfuhr, dass chinesische Wissenschaftler vom Georgia Institute of Technology und NVIDIA ein innovatives Feinabstimmungs-Framework namens RankRAG vorgeschlagen haben, das den komplexen Prozess der Retrieval Enhancement Generation (RAG) erheblich vereinfacht. RankRAG optimiert ein einzelnes großes Sprachmodell (LLM), um gleichzeitig die Aufgaben des Abrufens, Rankings und Generierens zu übernehmen, wodurch Leistung und Effizienz erheblich verbessert werden und experimentelle Ergebnisse erzielt werden, die bestehenden Open-Source-Modellen überlegen sind. Diese bahnbrechende Technologie eröffnet neue Möglichkeiten für die Anwendung von KI in verschiedenen Bereichen.
Kürzlich haben zwei chinesische Wissenschaftler vom Georgia Institute of Technology und NVIDIA ein neues Feinabstimmungs-Framework namens RankRAG vorgeschlagen. Dieses Framework vereinfacht die ursprüngliche komplexe RAG-Pipeline erheblich und verwendet die Feinabstimmungsmethode, um den Abruf, die Rangfolge und die Generierung mit demselben LLM zu ermöglichen Aufgaben, was auch zu einer erheblichen Leistungsverbesserung führte.

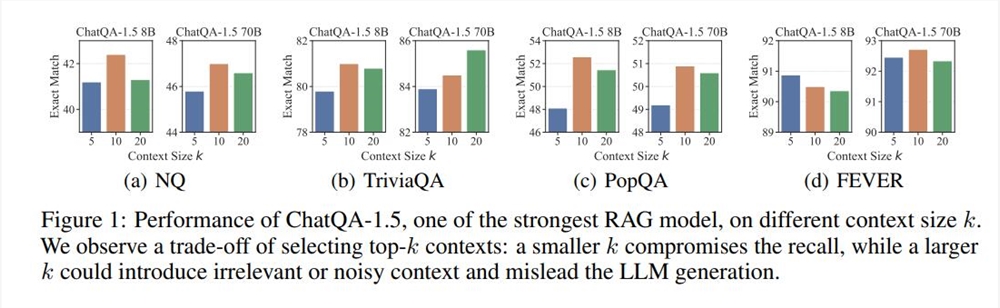
RAG (Retrieval-Augmented Generation) ist eine häufig verwendete Technologie im LLM-Einsatz und eignet sich besonders für Textgenerierungsaufgaben, die ein hohes Maß an Sachwissen erfordern. Im Allgemeinen ist der Prozess von RAG wie folgt: Ein dichtes Modell, das auf Textkodierung basiert, ruft Top-k-Textsegmente aus einer externen Datenbank ab und LLM liest und generiert sie dann. Dieses Verfahren ist weit verbreitet, weist jedoch auch Einschränkungen auf, z. B. die Auswahl des k-Werts. Wenn der k-Wert zu groß ist, hat selbst LLM, das lange Kontexte unterstützt, Schwierigkeiten, ihn schnell zu verarbeiten. Wenn der k-Wert zu klein ist, ist ein Abrufmechanismus mit hohem Rückruf erforderlich, und bestehende Retriever und Ranking-Modelle haben ihre eigenen Mängel.
Basierend auf den oben genannten Problemen stellt das RankRAG-Framework eine neue Idee vor: Erweitern Sie die LLM-Funktionen durch Feinabstimmung und lassen Sie LLM den Abruf und das Ranking selbst durchführen. Experimentelle Ergebnisse zeigen, dass diese Methode nicht nur die Dateneffizienz verbessert, sondern auch die Modellleistung erheblich steigert. Insbesondere bei mehreren allgemeinen Benchmarks und biomedizinischen wissensintensiven Benchmarks übertraf das von RankRAG verfeinerte Modell Llama38B/70B die Modelle ChatQA-1.58B bzw. ChatQA-1.570B.
Der Schlüssel zu RankRAG ist sein hohes Maß an Interaktivität und Bearbeitbarkeit. Benutzer können KI-generierte Inhalte nicht nur in Echtzeit anzeigen, sondern auch direkt auf der Benutzeroberfläche bearbeiten und iterieren. Dieser sofortige Feedback-Mechanismus verbessert die Arbeitseffizienz erheblich und macht KI zu einem wirklich leistungsstarken Assistenten im kreativen Prozess. Noch aufregender ist, dass diese Artefakte durch dieses Update nicht mehr auf die Claude-Plattform beschränkt sind und Benutzer sie problemlos überall teilen können.
Diese Innovation des RankRAG-Feinabstimmungsrahmens umfasst auch zwei Stufen der Feinabstimmung des Unterrichts. Die erste Stufe ist die überwachte Feinabstimmung (Supervised Fine-Tuning, SFT), bei der mehrere Datensätze gemischt werden, um die Fähigkeit des LLM zur Befehlsfolge zu verbessern. Der Feinabstimmungsdatensatz der zweiten Stufe enthält eine Vielzahl von QA-Daten, abrufverstärkten QA-Daten und kontextbezogenen Ranking-Daten, um die Abruf- und Ranking-Funktionen von LLM weiter zu verbessern.
In Experimenten übertrifft RankRAG das aktuelle Open-Source-SOTA-Modell ChatQA-1.5 bei neun allgemeinen Domänendatensätzen durchweg. Insbesondere bei anspruchsvollen QA-Aufgaben wie Long-Tail-QA und Multi-Hop-QA verbessert RankRAG die Leistung um mehr als 10 % gegenüber ChatQA-1.5.
Insgesamt schneidet RankRAG nicht nur bei Abruf- und Generierungsaufgaben gut ab, sondern demonstriert auch seine starke Anpassungsfähigkeit am biomedizinischen RAG-Benchmark Mirage. Auch ohne Feinabstimmung übertrifft RankRAG viele Open-Source-Modelle in Spezialgebieten bei der Beantwortung medizinischer Fragen.
Mit der Einführung und kontinuierlichen Verbesserung des RankRAG-Frameworks haben wir Grund zu der Annahme, dass die Zukunft der kollaborativen Kreation zwischen KI und Menschen rosiger sein wird. Sowohl unabhängige Entwickler als auch Forscher können dieses innovative Framework nutzen, um mehr Ideen und Möglichkeiten anzuregen und die Entwicklung von Technologie und Anwendungen voranzutreiben.
Papieradresse: https://arxiv.org/abs/2407.02485
Die Entstehung des RankRAG-Frameworks läutet einen weiteren Fortschritt für groß angelegte Sprachmodelle in den Bereichen Informationsabruf und Textgenerierung ein. Sein effizientes, einfaches Design und seine hervorragende Leistung werden zweifellos neue Richtungen und Motivation für die Entwicklung der KI-Technologie in der Zukunft bieten. Wir freuen uns darauf, dass RankRAG sein starkes Potenzial in weiteren Bereichen unter Beweis stellt!