In den letzten Jahren sind nacheinander Innovationen bei großen Sprachmodellen (LLM) entstanden, die die Grenzen bestehender Architekturen immer wieder aufs Neue herausfordern. Der Herausgeber von Downcodes erfuhr, dass Forscher von Stanford, UCSD, UC Berkeley und Meta gemeinsam eine neue Architektur namens TTT (Test-Time-Training Layers) vorgeschlagen haben, die voraussichtlich unser Verständnis von Sprache völlig verändern wird Das Modell wird erkannt und angewendet. Durch die geschickte Kombination der Vorteile von RNN und Transformer verbessert die TTT-Architektur die Ausdrucksfähigkeit des Modells und gewährleistet gleichzeitig eine lineare Komplexität. Sie bietet eine besonders gute Leistung bei der Verarbeitung langer Texte und bringt neue Erkenntnisse in Bereichen wie der Möglichkeit der langen Videomodellierung.
In der Welt der KI kommen Veränderungen immer unerwartet. Erst kürzlich entstand eine neue Architektur namens TTT, die gemeinsam von Forschern aus Stanford, UCSD, UC Berkeley und Meta vorgeschlagen wurde. Sie unterwanderte Transformer und Mamba und brachte revolutionäre Änderungen an den Sprachmodellen.
TTT, der vollständige Name der Test-Time-Training-Schichten, ist eine brandneue Architektur, die den Kontext durch Gradientenabstieg komprimiert und den traditionellen Aufmerksamkeitsmechanismus direkt ersetzt. Dieser Ansatz verbessert nicht nur die Effizienz, sondern erschließt auch eine lineare Komplexitätsarchitektur mit ausdrucksstarkem Gedächtnis, die es uns ermöglicht, LLMs zu trainieren, die Millionen oder sogar Milliarden von Token im Kontext enthalten.

Der Vorschlag der TTT-Schicht basiert auf tiefen Einblicken in die bestehenden RNN- und Transformer-Architekturen. Obwohl RNN hocheffizient ist, ist es durch seine Ausdrucksfähigkeit begrenzt; während Transformer über eine starke Ausdrucksfähigkeit verfügt, steigt sein Rechenaufwand linear mit der Kontextlänge. Die TTT-Schicht kombiniert geschickt die Vorteile beider, behält die lineare Komplexität bei und verbessert die Ausdrucksfähigkeiten.
In Experimenten zeigten beide Varianten, TTT-Linear und TTT-MLP, eine hervorragende Leistung und übertrafen Transformer und Mamba sowohl im kurzen als auch im langen Kontext. Insbesondere in Szenarien mit langem Kontext liegen die Vorteile der TTT-Schicht deutlicher auf der Hand, was ein enormes Potenzial für Anwendungsszenarien wie die Modellierung langer Videos bietet.
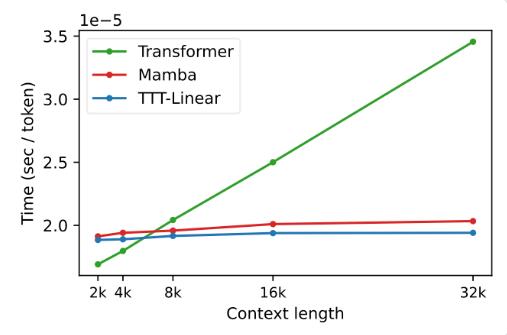
Der Vorschlag der TTT-Schicht ist nicht nur theoretisch innovativ, sondern zeigt auch großes Potenzial in der praktischen Anwendung. Es wird erwartet, dass die TTT-Schicht in Zukunft auf die Modellierung langer Videos angewendet wird, um durch dichtes Abtasten von Frames umfangreichere Informationen bereitzustellen. Dies ist eine Belastung für den Transformer, aber ein Segen für die TTT-Schicht.
Diese Forschung ist das Ergebnis von fünf Jahren harter Arbeit des Teams und wird seit der Postdoktorandenzeit von Dr. Yu Sun vorangetrieben. Sie forschten und versuchten beharrlich und erzielten schließlich dieses bahnbrechende Ergebnis. Der Erfolg der TTT-Schicht ist das Ergebnis des unermüdlichen Einsatzes und des Innovationsgeistes des Teams.
Das Aufkommen der TTT-Schicht hat dem KI-Bereich neue Vitalität und Möglichkeiten gebracht. Es verändert nicht nur unser Verständnis von Sprachmodellen, sondern eröffnet auch einen neuen Weg für zukünftige KI-Anwendungen. Freuen wir uns auf die zukünftige Anwendung und Entwicklung der TTT-Schicht und werden wir Zeuge der Fortschritte und Durchbrüche der KI-Technologie.
Papieradresse: https://arxiv.org/abs/2407.04620
Das Aufkommen der TTT-Architektur hat dem KI-Bereich zweifellos einen Aufschwung verliehen. Ihre bahnbrechenden Fortschritte bei der Langtextverarbeitung deuten darauf hin, dass zukünftige KI-Anwendungen über leistungsfähigere Verarbeitungsfähigkeiten und breitere Anwendungsaussichten verfügen werden. Warten wir ab, wie die TTT-Architektur unsere Welt weiter verändern wird.