Der Herausgeber von Downcodes bringt Ihnen große Neuigkeiten! Cerebras Systems hat den weltweit schnellsten KI-Inferenzdienst eingeführt – Cerebras Inference, der mit seiner erstaunlichen Geschwindigkeit und seinem äußerst wettbewerbsfähigen Preis die Spielregeln im Bereich der KI-Inferenz völlig verändert hat. Es bietet eine gute Leistung bei der Verarbeitung verschiedener KI-Modelle, insbesondere großer Sprachmodelle (LLMs), und ist 20-mal schneller als herkömmliche GPU-Systeme, und das zu einem Preis von nur einem Zehntel oder sogar einem Hundertstel. Wie wird sich dies auf die zukünftige Entwicklung von KI-Anwendungen auswirken? Schauen wir genauer hin.
Cerebras Systems, ein Pionier im Bereich Performance-KI-Computing, hat eine bahnbrechende Lösung eingeführt, die die KI-Inferenz revolutionieren wird. Am 27. August 2024 gab das Unternehmen den Start von Cerebras Inference bekannt, dem weltweit schnellsten KI-Inferenzdienst. Die Leistungsindikatoren von Cerebras Inference stellen herkömmliche GPU-basierte Systeme in den Schatten und bieten die 20-fache Geschwindigkeit zu extrem niedrigen Kosten, was einen neuen Maßstab für KI-Computing setzt.
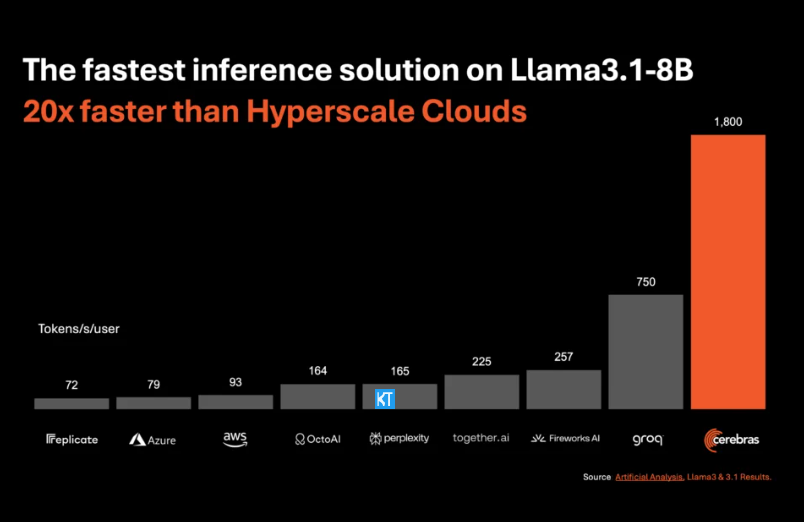
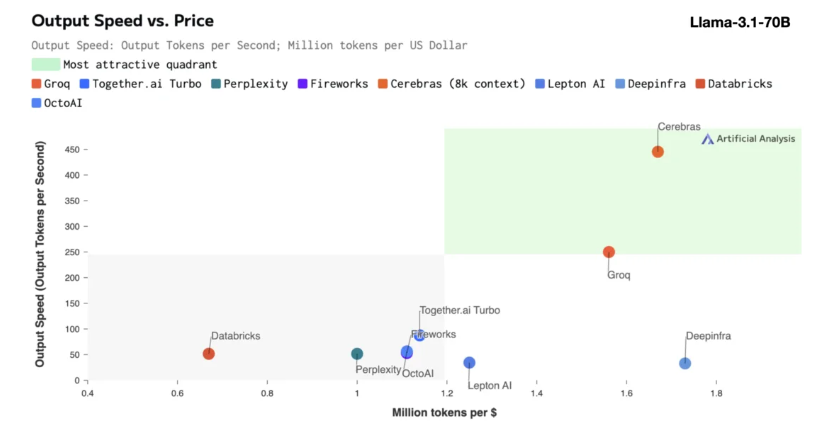
Cerebras-Inferenz eignet sich besonders für die Verarbeitung verschiedener Arten von KI-Modellen, insbesondere der sich schnell entwickelnden „Large Language Models“ (LLMs). Am Beispiel des neuesten Llama3.1-Modells kann die 8B-Version 1.800 Token pro Sekunde verarbeiten, während die 70B-Version 450 Token verarbeiten kann. Dies ist nicht nur 20-mal schneller als NVIDIA-GPU-Lösungen, sondern auch preislich wettbewerbsfähiger. Die Preise für Cerebras Inference beginnen bei nur 10 Cent pro Million Token und die 70B-Version liegt bei 60 Cent. Im Vergleich zu bestehenden GPU-Produkten ist das Preis-Leistungs-Verhältnis um das Hundertfache verbessert.
Es ist beeindruckend, dass Cerebras Inference diese Geschwindigkeit erreicht und gleichzeitig die branchenführende Genauigkeit beibehält. Im Gegensatz zu anderen Speed-First-Lösungen führt Cerebras die Inferenz immer im 16-Bit-Bereich durch und stellt so sicher, dass Leistungsverbesserungen nicht auf Kosten der Ausgabequalität des KI-Modells gehen. Micha Hill-Smith, CEO von Artificial Analytics, sagte, dass Cerebras auf dem Llama3.1-Modell von Meta eine Geschwindigkeit von mehr als 1.800 Ausgabetokens pro Sekunde erreicht habe und damit einen neuen Rekord aufgestellt habe.
KI-Inferenz ist das am schnellsten wachsende Segment des KI-Computings und macht etwa 40 % des gesamten KI-Hardwaremarktes aus. Hochgeschwindigkeits-KI-Inferenz, wie sie von Cerebras bereitgestellt wird, ist wie die Entstehung des Breitband-Internets, eröffnet neue Möglichkeiten und läutet eine neue Ära für KI-Anwendungen ein. Entwickler können Cerebras Inference verwenden, um KI-Anwendungen der nächsten Generation zu erstellen, die komplexe Echtzeitleistung erfordern, wie zum Beispiel intelligente Agenten und intelligente Systeme.
Cerebras Inference bietet drei preisgünstige Servicestufen: kostenlose Stufe, Entwicklerstufe und Enterprise-Stufe. Die kostenlose Stufe bietet API-Zugriff mit großzügigen Nutzungsbeschränkungen und ist somit ideal für ein breites Benutzerspektrum. Die Entwicklerebene bietet flexible serverlose Bereitstellungsoptionen, während die Unternehmensebene maßgeschneiderte Dienste und Support für Organisationen mit kontinuierlichen Arbeitslasten bereitstellt.
Als Kerntechnologie nutzt Cerebras Inference das CerebrasCS-3-System, das von der branchenführenden Wafer Scale Engine3 (WSE-3) angetrieben wird. Dieser KI-Prozessor ist in Größe und Geschwindigkeit beispiellos und bietet 7.000-mal mehr Speicherbandbreite als der NVIDIA H100.
Cerebras Systems ist nicht nur führend im Bereich KI-Computing, sondern spielt auch eine wichtige Rolle in zahlreichen Branchen wie Medizin, Energie, Regierung, wissenschaftliches Rechnen und Finanzdienstleistungen. Durch die kontinuierliche Weiterentwicklung technologischer Innovationen unterstützt Cerebras Unternehmen in verschiedenen Bereichen bei der Bewältigung komplexer KI-Herausforderungen.
Highlight:
Die Servicegeschwindigkeit von Cerebras Systems wird um das Zwanzigfache erhöht, der Preis ist wettbewerbsfähiger und es eröffnet eine neue Ära des KI-Denkens.
Unterstützt verschiedene KI-Modelle, insbesondere bei großen Sprachmodellen (LLMs).
Es stehen drei Servicelevel zur Verfügung, um Entwicklern und Unternehmensanwendern eine flexible Auswahl zu ermöglichen.
Alles in allem markiert das Aufkommen von Cerebras Inference einen wichtigen Meilenstein auf dem Gebiet der KI-Inferenz. Seine hervorragende Leistung und Wirtschaftlichkeit wird die weit verbreitete Popularisierung und innovative Entwicklung von KI-Anwendungen fördern und verdient die Aufmerksamkeit und Vorfreude der Branche! Der Herausgeber von Downcodes wird Ihnen weiterhin aktuelle Technologieinformationen liefern.