Heutzutage, mit der rasanten Entwicklung der KI-Technologie, haben kleine Sprachmodelle (SLM) aufgrund ihrer Fähigkeit, auf Geräten mit eingeschränkten Ressourcen ausgeführt zu werden, große Aufmerksamkeit auf sich gezogen. Das Nvidia-Team hat kürzlich Llama-3.1-Minitron4B veröffentlicht, ein hervorragendes kleines Sprachmodell, das auf der Komprimierung des Llama-3-Modells basiert. Es nutzt Modellbereinigungs- und Destillationstechnologien, um in der Leistung mit größeren Modellen mithalten zu können, bietet gleichzeitig effiziente Schulungs- und Bereitstellungsvorteile und eröffnet neue Möglichkeiten für KI-Anwendungen. Der Herausgeber von Downcodes vermittelt Ihnen ein tiefgreifendes Verständnis dieses technologischen Durchbruchs.
In einer Zeit, in der Technologieunternehmen der künstlichen Intelligenz auf Geräten nachjagen, entstehen immer mehr kleine Sprachmodelle (SLM), die auf Geräten mit eingeschränkten Ressourcen ausgeführt werden können. Kürzlich nutzte das Forschungsteam von Nvidia modernste Modellbereinigungs- und Destillationstechnologie, um Llama-3.1-Minitron4B auf den Markt zu bringen, eine komprimierte Version des Llama3-Modells. Dieses neue Modell ist nicht nur in der Leistung mit größeren Modellen vergleichbar, sondern konkurriert auch mit kleineren Modellen gleicher Größe und ist gleichzeitig effizienter bei Training und Einsatz.
Beschneiden und Destillieren sind zwei Schlüsseltechniken zur Erstellung kleinerer, effizienterer Sprachmodelle. Beschneiden bezieht sich auf das Entfernen unwichtiger Teile des Modells, einschließlich „Tiefenbeschneiden“ – das Entfernen ganzer Schichten, und „Breitenbeschneiden“ – das Entfernen bestimmter Elemente wie Neuronen und Aufmerksamkeitsköpfe. Die Modelldestillation hingegen überträgt Wissen und Fähigkeiten von einem großen Modell (d. h. „Lehrermodell“) auf ein kleineres, einfacheres „Schülermodell“.
Es gibt zwei Hauptmethoden zur Destillation: Die erste ist das „SGD-Training“, das es dem Schülermodell ermöglicht, die Eingaben und Reaktionen des Lehrermodells zu erlernen. Die zweite Methode ist die „klassische Wissensdestillation“. Das Schülermodell benötigt auch eine interne Aktivierung des lernenden Lehrermodells.
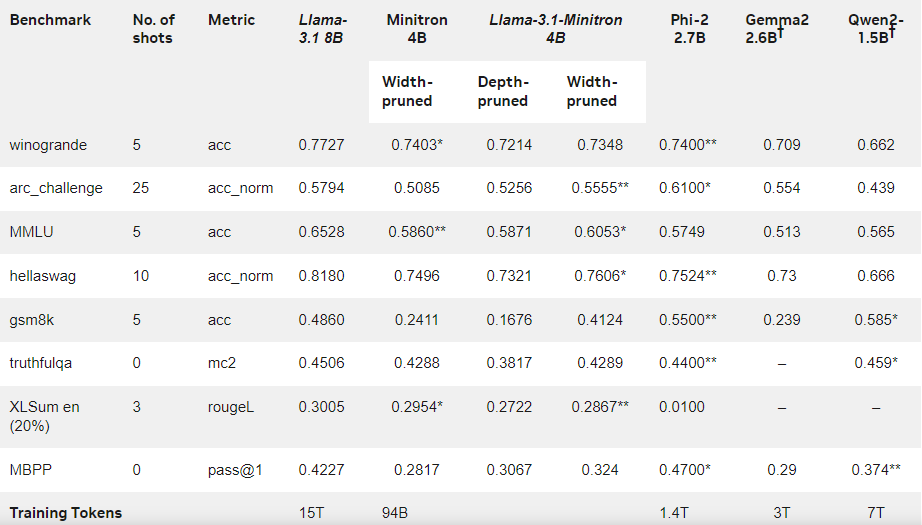
In einer früheren Studie haben Nvidia-Forscher das Nemotron15B-Modell durch Beschneiden und Destillieren erfolgreich auf ein 800-Millionen-Parameter-Modell reduziert und es schließlich weiter auf 400 Millionen Parameter reduziert. Dieser Prozess verbessert nicht nur die Leistung um 16 % gegenüber dem berühmten MMLU-Benchmark, sondern erfordert auch 40-mal weniger Trainingsdaten als ein Training von Grund auf.
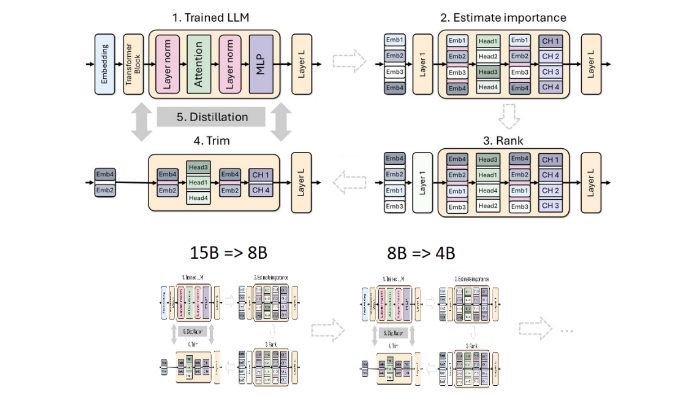
Diesmal verwendete das Nvidia-Team dieselbe Methode, um ein 400-Millionen-Parameter-Modell basierend auf dem Llama3.18B-Modell zu erstellen. Zunächst optimierten sie das ungekürzte 8B-Modell anhand eines Datensatzes mit 94 Milliarden Token, um die Verteilungsunterschiede zwischen den Trainingsdaten und dem destillierten Datensatz zu bewältigen. Dann wurden zwei Methoden des Tiefenbeschneidens und des Breitenbeschneidens verwendet und schließlich wurden zwei verschiedene Versionen von Llama-3.1-Minitron4B erhalten.
Die Forscher optimierten das beschnittene Modell mithilfe von NeMo-Aligner und bewerteten seine Fähigkeiten in Bezug auf Befehlsfolge, Rollenspiele, Retrieval Augmentation Generation (RAG) und Funktionsaufrufe.
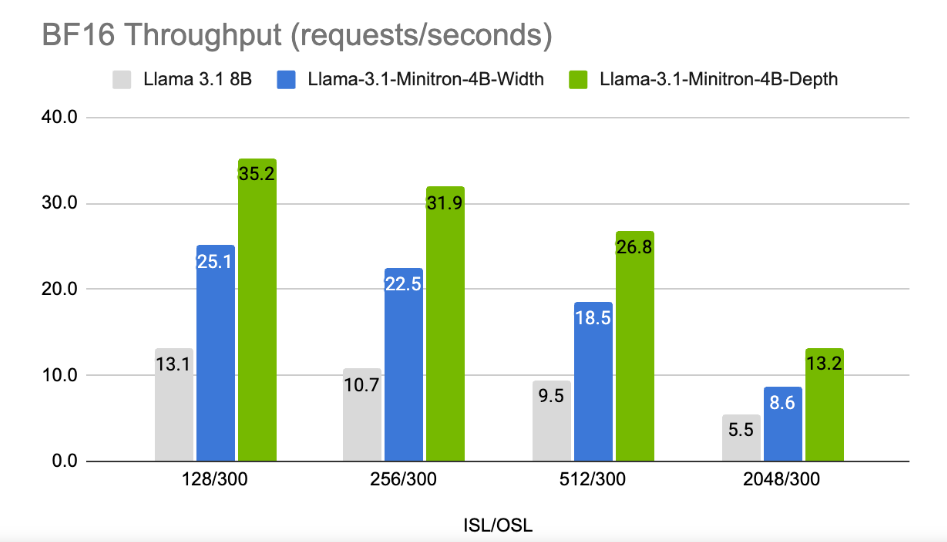
Die Ergebnisse zeigen, dass die Leistung von Llama-3.1-Minitron4B trotz der geringen Menge an Trainingsdaten immer noch nahe an der anderer kleiner Modelle liegt und eine gute Leistung erbringt. Die auf die Breite reduzierte Version des Modells wurde auf Hugging Face veröffentlicht und ermöglicht die kommerzielle Nutzung, damit mehr Benutzer und Entwickler von seiner Effizienz und hervorragenden Leistung profitieren können.
Offizieller Blog: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
Highlight:
Llama-3.1-Minitron4B ist ein von Nvidia eingeführtes kleines Sprachmodell, das auf Bereinigungs- und Destillationstechnologie basiert und über effiziente Trainings- und Bereitstellungsfunktionen verfügt.
Die Menge der im Trainingsprozess dieses Modells verwendeten Marker wird im Vergleich zum Training von Grund auf um das 40-fache reduziert, die Leistung wird jedoch deutlich verbessert.
? Die Breitenbeschneidungsversion wurde auf Hugging Face veröffentlicht, um Benutzern die kommerzielle Nutzung und Entwicklung zu erleichtern.
Alles in allem markiert das Aufkommen von Llama-3.1-Minitron4B einen neuen Meilenstein in der Entwicklung kleiner Sprachmodelle. Seine effiziente Leistung und praktische Bereitstellungsmethode werden mehr Entwicklern und Benutzern gute Nachrichten bringen und die Popularisierung und Anwendung der KI-Technologie beschleunigen. Der Herausgeber von Downcodes freut sich auf weitere ähnliche Innovationen in der Zukunft.